深刻な分析対策のおかげで、FinFisherスパイウェアはあまり理解されていませんでした。 これはよく知られた追跡ツールですが、以前のサンプルでは部分的な分析のみが公開されていました。
ESETによるFinFisherサイバースパイ活動の分析後、2017年夏に状況は変わり始めました。 この調査の過程で、
インターネットサービスプロバイダーの被害者を侵害する攻撃を特定しました。

Malvariの分析を開始したとき、WindowsバージョンでのFinFisherの分析に対抗するための対策を克服することに主な努力が費やされました。 高度な難読化と独自の仮想化の組み合わせにより、FinFisherマスキングプロセスは非常に困難になります。
このガイドでは、FinFisher分析プロセスで学んだことを共有します。 FinFisher仮想マシンの分析に関するヒントに加えて、このガイドは、仮想マシン全体、つまりバイナリコードで検出され、ソフトウェアの保護に使用される独自の仮想マシンを使用した保護を理解するのに役立ちます。
また、FinFisher for Androidのバージョンも分析しました。その保護メカニズムは、オープンアクセスLLVM難読化ツールに基づいています。 Windowsのバージョンメカニズムほど複雑でおもしろくないので、このガイドでは説明しません。
このガイドが、情報セキュリティの研究者やウイルス分析者がFinFisherのツールと戦術を理解し、この脅威から顧客を保護するのに役立つことを願っています。
分解対策
IDA ProでFinFisherサンプルを開くと、メイン機能に、分解ですが、最初の防御策に対抗するためのシンプルだが効果的な方法があります。
FinFisherは、逆アセンブリに対して一般的な手法を使用します。1つの無条件ジャンプ命令を2つの補完的な条件付き遷移に置き換えることにより、実行の進行を隠します。 これらは同じ遷移ポイントを指しているため、実行される遷移に関係なく、コードの実行順序は変わりません。 条件付きジャンプの後は、意味のないコードバイトになります。 通常の条件下では、非作業領域を認識できず、このゴミの分解作業を継続するため、逆アセンブラーを混乱させるように設計されています。
特に、このマルウェアはこの手法を使用します。 私たちが調査したほとんどのマルウェアは、この方法を特定の回数使用しています。 ただし、FinFisherは各コマンドの後にこのトリックを適用します。
この保護は逆アセンブラに対して非常に効果的であり、多くのコードが適切にプロセスを通過しないように混乱させます。 そして、もちろん、IDA Proのグラフィックモードは使用できなくなります。 最初のタスクは、この保護を取り除くことです。
コードは明らかに手動では難読化されていませんが、自動ツールの助けを借りて、移行コマンドのすべてのペアで特定のパターンを観察しています。
ジャンプペアには2つの異なるタイプがあります。インデントが32ビットの内部ジャンプとインデントが8ビットの短い遷移です。
両方の条件付き内部遷移(DWORDは遷移インデント)のオペレーションコードは、バイト0x0Fで始まり、2番目のバイトは0x8ですか? 両方の遷移命令で、それらは1ビットだけ異なります。 これは、相補的な遷移のx86 OSオペレーションコードが数値的に連続しているという事実によるものです。 たとえば、この難読化スキームは、常にJEとJNE(オペコード0x0F 0x84および0x0F 0x85)、JPとJNP(オペコード0x0F 0x8Aおよび0x0F 0x8B)などをペアにします。
これらのオペコードの後に、遷移が行われるインデントを定義する32ビット引数があります。 両方の命令のサイズは6バイトであるため、2つの連続した遷移のインデントは正確に6異なります(図1を参照)。
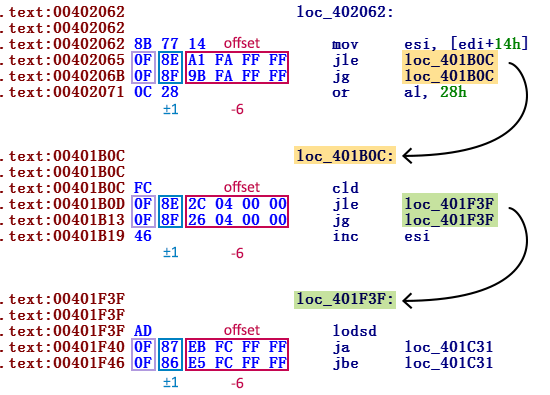 図1.毎回2つの条件付き内部遷移が続くコマンドのスクリーンショット
図1.毎回2つの条件付き内部遷移が続くコマンドのスクリーンショットたとえば、次のコードを使用して、これら2つの連続した遷移を検出できます。
def is_jump_near_pair(addr): jcc1 = Byte(addr+1) jcc2 = Byte(addr+7) # ? if Byte(addr) != 0x0F || Byte(addr+6) != 0x0F: return False # 2 ? if (jcc1 & 0xF0 != 0x80) || (jcc2 & 0xF0 != 0x80): return False # ? if abs(jcc1-jcc2) != 1: return False # ? dst1 = Dword(addr+2) dst2 = Dword(addr+8) if dst1-dst2 != 6 return False return True
短い遷移の難読化解除は同様の考え方に基づいており、定数のみが異なります。
短い条件分岐のオペコードは0x7?で、その後に1バイト(遷移のインデント)が続きます。 したがって、再び2つの連続した条件付き内部遷移を探しており、オペレーションコード0x7?;が必要です。 インデント; 0x7? ±1; インデント-2。 最初のオペコードの後、1つのバイトがあり、2つの連続した遷移で2だけ異なります(これも両方の命令のサイズです)(図2)。
 図2.毎回2つの短い条件付き遷移が続くコマンドの例
図2.毎回2つの短い条件付き遷移が続くコマンドの例たとえば、このコードを使用して、2つの条件付きショートジャンプを検出できます。
def is_jcc8(b): return b&0xF0 == 0x70 def is_jump_short_pair(addr): jcc1 = Byte(addr) jcc2 = Byte(addr+2) if not is_jcc8(jcc1) || not is_jcc8(jcc2): return False if abs(jcc2–jcc1) != 1: return False dst1 = Byte(addr+1) dst2 = Byte(addr+3) if dst1 – dst2 != 2: return False return True
これらの条件分岐のペアの1つを見つけた後、パッチを使用してコードの難読化を解除し、最初の条件分岐を無条件にし(内部遷移ペアに0xE9オペコードを使用し、ショートジャンプペアに0xEBを使用)、残りのバイトを空の命令(0x90)で埋めます
def patch_jcc32(addr): PatchByte(addr, 0x90) PatchByte(addr+1, 0xE9) PatchWord(addr+6, 0x9090) PatchDword(addr+8, 0x90909090) def patch_jcc8(addr): PatchByte(addr, 0xEB) PatchWord(addr+2, 0x9090)
これら2つの状況に加えて、遷移のペアが短いタイプと内部タイプ、つまり異なるタイプで構成される場合があります。 しかし、これは少数の場所でしか見つからないため、FinFisherサンプルではこれを手動で修正できます。
これらの挿入物を使用して、IDA Proは新しいコードを「理解」し始め、チャートを作成する準備ができています(まあ、またはほぼ準備ができています)。 終了点を追加する、つまりノードに遷移位置を割り当て、チャート上で遷移コマンドと一致するように、さらに改善する必要がある場合があります。 このために、Python IDA関数
append_func_tail使用できます。
逆アセンブラの通常の動作を妨げるトリックを回避する最後の手順は、関数定義を修正することです。 移行後のコマンドが
push ebpである場合があります。この場合、IDA Proは(誤って)これを関数の開始と見なし、それに応じて新しい定義を開始します。 この場合、関数定義を削除し、正しいエントリを作成し、さらに末尾を追加する必要があります。
このようにして、分解に対する最初のFinFisher保護を削除します。
FinFisher仮想マシン
第1レベルの保護の難読化解除に成功すると、メイン機能が開きます。その主な目的は、特別に作成された仮想マシンを起動し、さらにペイロードを使用してバイトコードを解釈することです。
通常の実行可能ファイルとは異なり、内部に仮想マシンを持つ実行可能ファイルは、プロセッサ命令を直接実行する代わりに、仮想化された命令セットを使用します。 仮想化されたコマンドは、独自の構造を持ち、バイトコードをアンマネージマシンコードに変換しない仮想プロセッサによって実行されます。 この仮想プロセッサは、バイトコード(および仮想命令)と同様に、仮想マシンをプログラムする人によって決定されます(図3)。
はじめに、仮想マシンのよく知られた例の1つがJava VMであると述べました。 ただし、この場合、仮想マシンはバイナリコード内にあるため、ここではリバースエンジニアリングから保護するための仮想マシンに直面しています。 VMProtectやCode Virtualizerなどの有名な商用仮想マシン保護があります。
FinFisherスパイウェアはソースからコンパイルされ、生成されたバイナリはアセンブリレベルの仮想マシンによって保護されます。 保護プロセスでは、ソースバイナリファイルの命令を仮想命令に変換し、バイトコードと仮想プロセッサを含む新しいバイナリファイルを作成します。 ソースバイナリからのネイティブ命令は失われます。 保護された仮想化されたサンプルは、保護されていないサンプルと同じ動作をする必要があります。
仮想マシンで保護されたバイナリファイルを分析するには、次のものが必要です。
- 仮想CPUの分析
- この非標準の仮想CPU用に独自の逆アセンブラーを作成し、バイトコードを解析します
- オプション:逆アセンブルされたコードをバイナリファイルにコンパイルし、仮想マシンを取り除きます。
最初の2つのタスクには多くの時間がかかり、最初のタスクは非常に複雑になる可能性があります。 各
vm_handlerハンドラーの分析と、レジスター、メモリーアクセス、呼び出しなどの転送方法の理解が含まれます。
 図3.仮想CPUによって解釈されるバイトコード
図3.仮想CPUによって解釈されるバイトコード用語と定義
仮想マシンの個々の部分を定義するための標準はありません。 したがって、このホワイトペーパーで参照するいくつかの用語を定義します。
- 仮想マシン(vm)–仮想CPU。 vm_dispatcher、vm_start、vm_handlersが含まれます
- vm_start-初期化; ここでメモリの割り当てと復号化プロセスが行われます
- バイトコード( pcodeとも呼ばれます)-引数付きの仮想オペコードvm_instructionsはここに保存されます
- vm_dispatcher-仮想オペコードを呼び出してデコードします。 基本的に、 vm_handlersの実行の準備をします
- vm_handler - vm_instructionの実装。 1つのvm_handlerの実行は、1つのvm_instructionの実行を意味します
- インタープリター( vm_loopとも呼ばれる) -vm_dispatcher + vm_handlers-仮想CPU
- 仮想オペコード-ネイティブオペコードの類似物
- vm_context ( vm_structure )-インタープリターが使用する内部構造
- vi_params - vm_context構造内の構造。 vm_handlerが使用する仮想コマンドのパラメーター。 vm_opcodeと引数を含む
バイトコードを解釈するプロセスで、仮想マシンは仮想スタックと単一の仮想レジスタを使用します。
- vm_stack-仮想マシンが使用するネイティブスタックの類似物
- vm_register-この仮想マシンで使用されるネイティブレジスタの類似物。 以下、tmp_REGと呼ばれます
- vm_instruction-仮想マシンの開発者によって定義されたチーム。 コマンドの本体(実装)は、 vm_handlerによって呼び出されます
以下のセクションでは、仮想マシンの要素を技術的な詳細で説明し、それらを分析する方法を説明します。
Malvariのメイン関数の難読化されたグラフィカル表現は、初期化と
vm_startおよびインタープリター(
vm_dispatcher +
vm_handlers )と呼ばれる他の2つの3つの部分で構成されています。
初期化コンポーネントは、バイトコードのエントリポイントとして解釈できるものに一意の識別子を設定し、スタックにプッシュします。 次に、
vm_start部分への移行、つまり仮想マシン自体の初期化プロセスが行われます。 バイトコードが復号化され、制御が
vm_dispatcherに渡されます
。vm_dispatcherは、バイトコードの仮想命令サイクルを開始し、
vm_handlersを使用してそれらを解釈します。
Vm_dispatcherはpushaコマンドで始まり、
jmp dword ptr [eax+ecx*4]コマンド(または同様)、つまり対応する
vm_handlerへの移行で
終わります。
Vm_start
第1レベルの難読化解除後に作成されたグラフィックモデルを図4に示します
。vm_startに関連する部分は、インタープリターの分析にとってそれほど重要ではありません。 ただし、仮想マシン全体の実装、仮想フラグ、仮想スタックなどの使用方法と管理方法を理解すると役立ちます。 2番目の部分である
vm_disperscherと
vm_handlersは、基盤です。
 図4. vm_startおよびvm_dispatcherのグラフィカル表現vm_start
図4. vm_startおよびvm_dispatcherのグラフィカル表現vm_startの呼び出し
は 、メインを含むほぼすべての関数から行われます。
呼び出し関数は常に仮想識別子をプッシュしてから、
vm_startに移行し
ます 。 各仮想チームには独自の仮想識別子があります。 この例では、メイン関数からの実行が開始される仮想エントリポイントの識別子は0x21CD0554です(図5)。
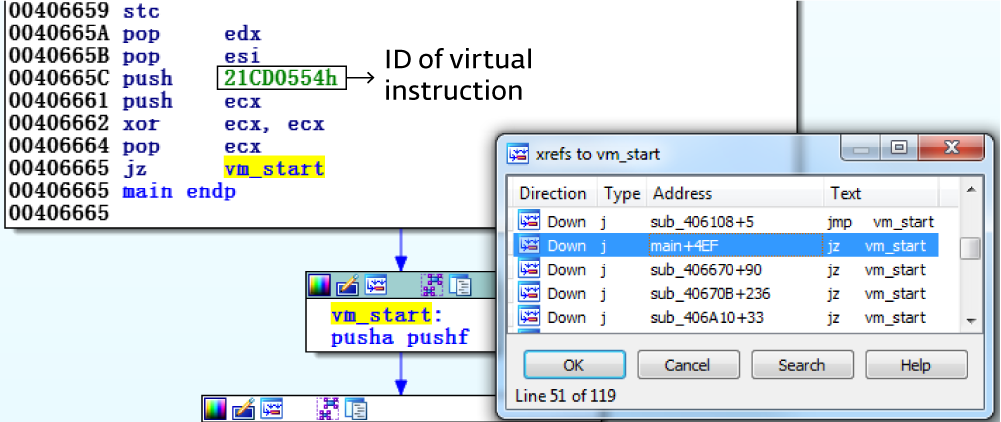 図5. vm_startは、119個の仮想化された関数のそれぞれから呼び出されます。
図5. vm_startは、119個の仮想化された関数のそれぞれから呼び出されます。対応する関数の最初の仮想コマンドの識別子が引数として与えられます。
この部分では、ほとんどのコードは
vm_dispatcherの準備に専念してい
ます。主にバイトコードとインタープリター全体のメモリの割り当てです。 最も重要なコードは次のことを行います。
- バイトコードといくつかの変数の割り当て。読み取り、書き込み、実行の許可を持つ1 MBのメモリ。
- 現在のタスクチェーンの仮想マシンのローカル変数に対して同じ解像度で0x10000バイトが割り当てられているのはvm_stackです。
- XOR復号化(排他的OR)。 復号化されたコードはaPLibとして解凍されます。 サンプルの復号化プロセスでは、XOR dwordキーのわずかに変更されたバージョンを使用しています。 最初の6つのDWORDをスキップし、キーを使用して残りの5つのDWORDにXORを適用します。 以下はプロセスアルゴリズムです(以降、XOR復号化コードと呼びます):
int array[6]; int key; for (i = 1; i < 6; i++) { array[i] ^= key; }
- バイトコードを解凍するaPLibプロセスを呼び出します。 その後、仮想オペコードは暗号化されたままになります(図6)。
仮想オペコードの準備(ステップ
1、3、4 )は最初に一度だけ実行され、以降の
vm_startの実行ではスキップされますが、フラグとレジスタを使用するコマンドのみが実行されます。
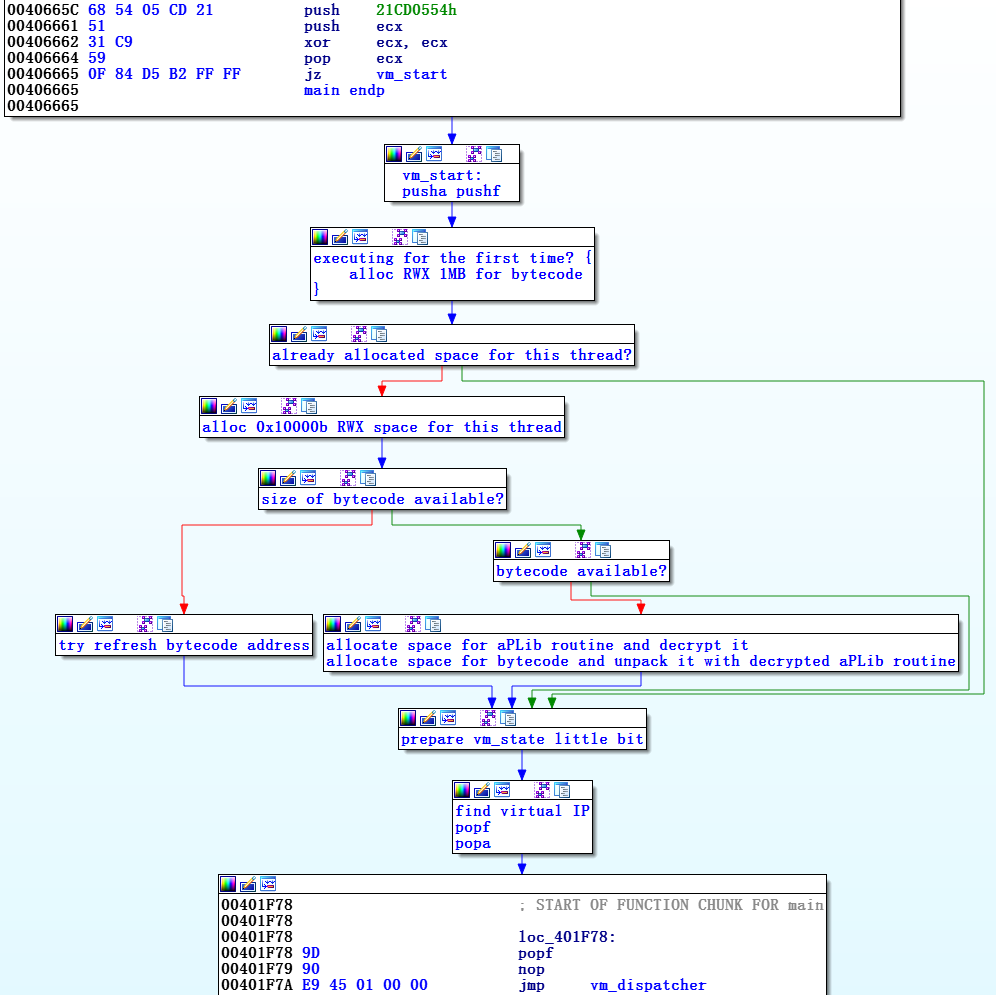 図6. vm_startからvm_dispatcherまでのすべてのコードはグループ化され、宛先に応じて名前が付けられます。
図6. vm_startからvm_dispatcherまでのすべてのコードはグループ化され、宛先に応じて名前が付けられます。FinFisher通訳
この部分には、すべての
vm_handlers (FinFisherサンプルでは34)を含む
vm_dispatcherが含まれ、仮想マシンを分析および/または仮想化するための重要な要素です。 インタープリターはバイトコードを実行します。
jmp dword ptr [eax+ecx*4]コマンドは、34
個のvm_handlersのいずれかにジャンプします。 各
vm_handlerは、1つの仮想マシンコマンドを実装します。
vm_handlerのそれぞれの
機能を理解するに
は 、
vm_contextと
vm_dispatcherを処理する必要があります。
1. IDAでグラフィカル構造を作成する
適切に構造化されたチャートを作成すると、インタープリターをよりよく理解できます。
vm_startと
vm_dispatcherの 2つの部分に分けることをお勧めします。
つまり 、最初の
vm_dispatcherコマンドで関数の開始を決定する必要があります。 この場合、
vm_dispatcherによって
参照される
vm_handlers自体はまだありません。 これらのハンドラーを
vm_dispatcher図に接続するには、次の関数を使用できます。
AddCodeXref(addr_of_jmp_instr, vm_handler,XREF_USER|fl_JN)
最後の
vm_dispatcherコマンドの vm_handlersリンクの先頭に追加
AppendFchunk
最後に追加を生成します
各
vm_handlerハンドラーをディスパッチャー関数に追加すると、図は次の図7に示すようになります。
2. Vm_dispatcher
この部分は、バイトコードの処理とデコードを担当します。 彼女は次の手順を実行します。
pusfおよびpusfを実行して、仮想コマンドの後続の実行のために仮想レジスタおよび仮想フラグを準備します- メモリ内のプログラムアドレスとアドレスvm_stackを取得します
- 次のvm_instructionコマンドとその引数を定義する24バイトのバイトコードを読み取ります
- 前述のXORプロシージャを使用してバイトコードを復号化します
- 引数がグローバル変数である場合、バイトコードの引数としてメモリ内のプログラムアドレスを追加します
- 解読されたバイトコードから仮想オペコード(0〜33の範囲の数字)を取得します
- 仮想オペコードを解釈する対応するvm_handlerハンドラーに移行します
コマンドの
vm_handlerが実行された後、最初の
vm_dispatcherコマンドから開始して、同じシーケンスが後続のシーケンスに対して繰り返されます。
vm_callハンドラーの場合
、制御は
vm_startに渡され
ます (非仮想化関数が後に続く場合を
除く )。
 図7. 34個すべてのvm_handlersを含むvm_dispatcherダイアグラム。
図7. 34個すべてのvm_handlersを含むvm_dispatcherダイアグラム。3. Vm_context
このパートでは、
vm_context -
vm_dispatcherおよび各
vm_handlerの実行に必要なすべての情報を含む仮想マシンが使用する構造について説明します。
vm_dispatcherおよび
vm_handlersコードの詳細な調査では、
ebx+offsetを参照するデータ処理コマンドが含まれていることがわかります。ここで、offsetは0x00〜0x50の数字です。 図8では、FinFisherサンプルの1つでvm_handler 0x05の主要部分がどのように見えるかを確認できます。
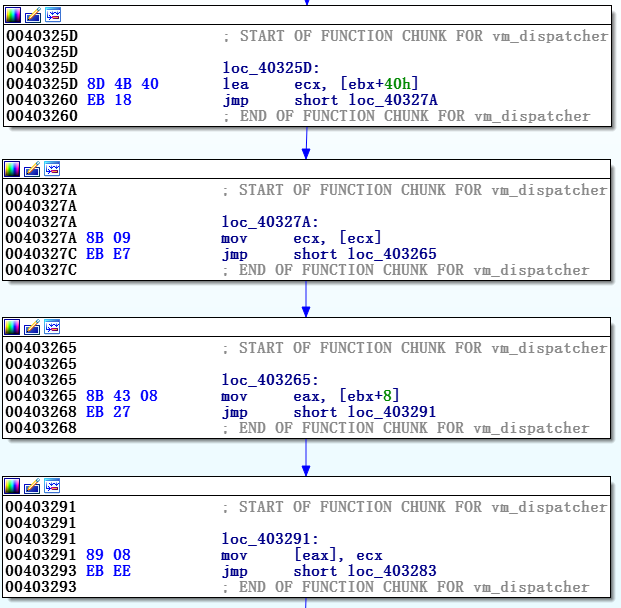 図8. vm_handlersの1つのスクリーンショット
図8. vm_handlersの1つのスクリーンショットebxレジスタは、
vm_contextと呼ばれる構造体を
指します。 この構造がどのように使用されるのか、そのメンバーが何であるのか、それらが何を意味するのか、どのように適用されるのかを理解する必要があります。 この問題を初めて解決するには、
vm_contextとその部分の使用方法を推測する
必要があります。
例として、
vm_dispatcherの最後にある一連のコマンドを見てみましょう。
movzx ecx, byte ptr [ebx+0x3C]
最後のコマンドは
vm_handlerへの移行であることがわかっているため、ecxには仮想オペコードが含まれており、したがって0x3C vm_struct要素は仮想オペコードを参照していると結論付けることができます。
もう1つの根拠のない仮定をしてみましょう。 ほとんどすべてのvm_handlerの最後に、次のコマンドがあります。
add dword ptr [ebx], 0x18.
同じ
vm_context要素が
vm_dispatcherコードで以前に使用されていました
-vm_handlerに移行する
直前 。
vm_dispatcherは、構造要素から別の場所(
[ebx+38h] )に24バイトをコピーし、現在のバイトコードの一部を取得するためにXORを使用してそれを解読します。
つまり、
vm_context (
[ebx+0h] )要素を
vm_instruction_pointerポインターとして、復号化された位置(
[ebx+38h]から
[ebx+50h] )を仮想コマンドのID、その仮想オペコード、および引数と見なし始めることができます。 この構造全体に
vi_paramsという名前を付けました。
上記の手順を完了し、デバッグプログラムを使用すると、構造の対応する要素に含まれる値が
わかります。
つまり 、すべての
vm_context要素を定義できます。
分析後
、FinFisherの vm_contextと
vi_paramsの両方の構造を復元できます。
struct vm_context { DWORD vm_instruct_ptr; // DWORD vm_stack; // vm_stack DWORD tmp_REG; // “” DWORD vm_dispatcher_loop; // vm_dispatcher DWORD cleanAndVMDispatchFn; // , vm_dispatcher, DWORD cleanUpDynamicCodeFn; // , vm_instr_ptr cleanAndVMDispatchFn DWORD jmpLoc1; // DWORD jmpLoc2; // vm_opcode – vm_instruction DWORD Bytecode_start; // DWORD DispatchEBP; DWORD ImageBase; // DWORDESP0_flags;// ( vm_code) DWORDESP1_flags;// DWORD LoadVOpcodesSectionFn; vi_params bytecode; // vm_handler, DWORD limitForTopOfStack; // }; struct vi_params { DWORD Virtual_instr_id; DWORD OpCode; // values 0 – 33 -> , DWORD Arg0; // 4 dword vm_handler DWORD Arg4; // DWORD Arg8; // DWORD ArgC; // };
4.仮想コマンドの使用-vm_handlers
vm_handlerのそれぞれは、1つの仮想オペコード、つまり34の
vm_handlersハンドラーごとに最大34の仮想オペコードで
動作します。 1つの
vm_handlerの実行は1つの
vm_instructionの実行を意味するため、
vm_instructionが何を行うかを判断するには、対応する
vm_handlerを分析する必要があります。
vm_contextを再構築し、ebxのすべてのインデントに名前を
付けると、前述のvm_handlerが読みやすくなります(図9を参照)。
この関数の最後に、
vm_instruction_pointerで始まるコマンドのシーケンスがあります。これは24ずつ
増加します。
つまり 、各
vm_instructionのvi_params構造体のサイズによって増加します。 このシーケンスはほぼすべての
vm_handlerの最後で繰り返されるため、これは標準の終了関数コードであり、
vm_handler自体の本体は
次のように簡単に記述できると結論付けています。
mov [tmp_REG], Arg0
したがって、この仮想マシンの最初のコマンドを分析しました:-)
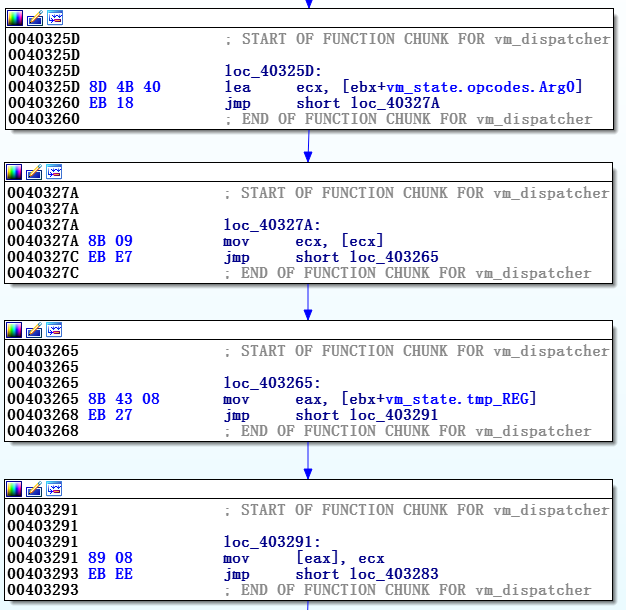 図9. vm_context構造に挿入した後の以前のvm_handler
図9. vm_context構造に挿入した後の以前のvm_handler分析されたコマンドの操作を説明するために、vi_params構造体が次のように設定されていると仮定します。
struct vi_params { DWORD ID_of_virt_instr = , ; DWORD OpCode = 0x0C; DWORD Arg0 = 0x42; DWORD Arg4 = 0; DWORD Arg8 = 0; DWORD ArgC = 0; };
上記から、次のコマンドが実行されていることがわかります。
mov [tmp_REG], 0x42
この時点で、
vm_instructionsの 1つが何をするかをすでに理解しているはずです。 完璧なステップは、通訳者全体の仕事のデモンストレーションとして役立つはずです。
ただし、
解析がより困難な
vm_handlersがいくつかあります。 この仮想マシンの条件付き遷移は、フラグの変換がどのように発生するかを理解するのがより困難です。
前述のように、
vm_dispatcherは、ネイティブEFLAGS(
vm_codeから)を独自のスタックの先頭に置くことから
始めます。 したがって、対応する遷移のハンドラーは、それを行うかどうかを決定するときに、独自のスタック内のEFLAGSをチェックし、独自の遷移メソッドを適用します。 図10は、パリティチェックを介して仮想JNP(パリティがない場合はジャンプ)ハンドラがどのように適用されるかを示しています。
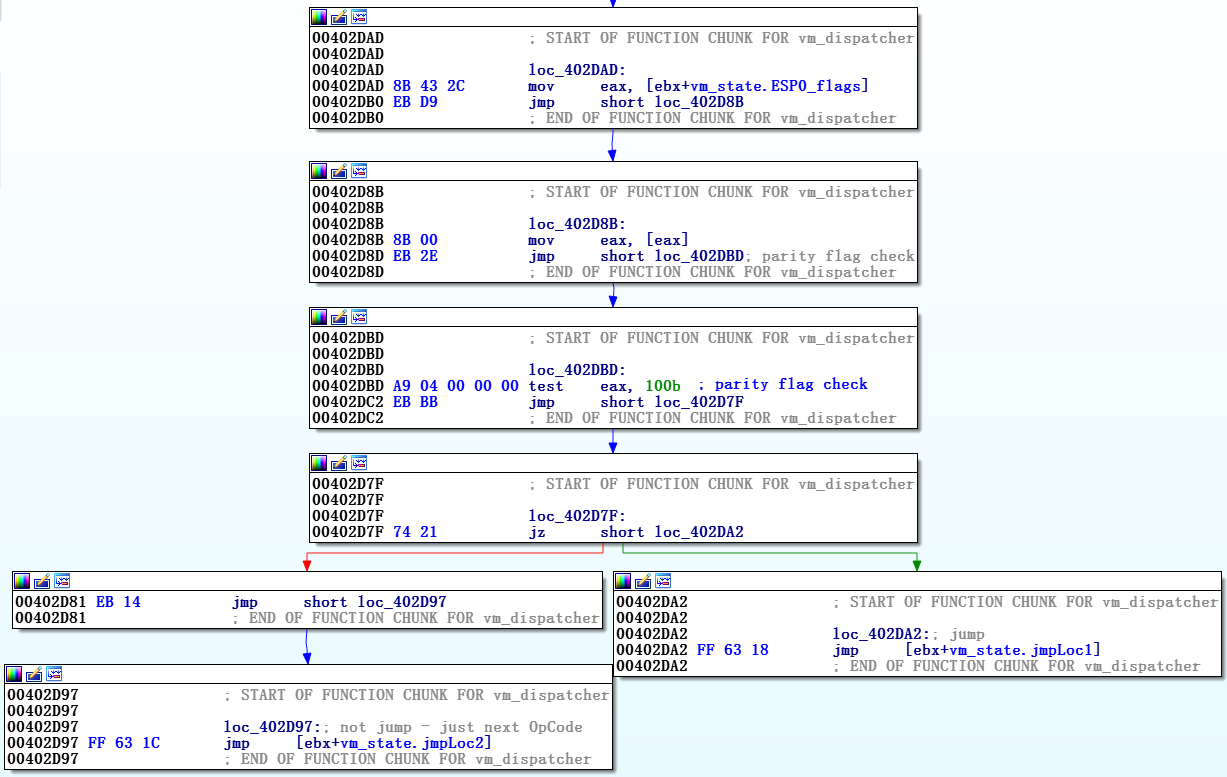 図10. JNP_handlerのスクリーンショット
図10. JNP_handlerのスクリーンショット他の仮想条件付き遷移の場合、いくつかの兆候を確認する必要がある場合があります-たとえば、仮想化されたJBE(以下の場合はジャンプ)の遷移の結果は、キャリーフラグとゼロフラグの両方の値に依存しますが、原理は同じです。
FinFisher仮想マシンの34
個のvm_handlersをすべて分析した後、その仮想コマンドを次のように記述できます。
 図11. 34個すべてのvm_handlersを持つvm_table
図11. 34個すべてのvm_handlersを持つvm_tableキーワード「
tmp_REG 」は、仮想マシンが使用する仮想レジスタ、
vm_contex t構造内の一時レジスタを指し、「
reg 」はプロセッサ自身のレジスタ、つまり eax。
分析された仮想マシンのコマンドを見てみましょう。 たとえば、
case_3_vm_jccは、条件付きまたは無条件の任意のプロセッサジャンプ命令を実行できる汎用ジャンプ命令ハンドラです。
明らかに、この仮想マシンはすべてのハードウェアコマンドを仮想化するわけではありません。ここで、上記のリスト(ケース4およびケース6)のコマンドが役立ちます。
これら2つの
vm_handlerは、コードを直接実行するために使用されます。 それらが行うことは、引数としてプロセッサコマンドオペコードを読み取り、コマンドを実行することです。
また、
vm_registersは常に自身のスタックの最上位にあり、実行可能レジスタの識別子は仮想コマンドのarg0の最後のバイトに格納されることに注意して
ください 。
対応する仮想レジスタにアクセスするには、次のコードを使用できます。 def resolve_reg(reg_pos): stack_regs = ['eax', 'ecx', 'edx', 'ebx', 'esp', 'ebp', 'esi', 'edi'] stack_regs.reverse() return stack_regs[reg_pos] reg_pos = 7 – (state[arg0] & 0x000000FF) reg = resolve_reg(reg_pos)
5.独自の逆アセンブラーの作成
すべてのvm_instructionsを正しく分析した後、サンプル分析を開始する前に実行する必要があるもう1つのステップが残っています-バイトコード用に独自の逆アセンブラーを作成する必要があります(手動で解析するとサイズが問題になります)。努力し、より信頼性の高い逆アセンブラーを作成することで、後でFinFisher仮想マシンが変更および更新されたときに自分自身を救います。次のコマンドを実行するvm_handler 0x0Cから始めましょう。 mov [tmp_REG], reg
このコマンドは引数を1つだけ取ります-regとして使用される独自のレジスタの識別子。この識別子はresolve_reg、たとえば上の例のコマンドを使用して、独自のレジスタの名前で表示する必要があります。このvm_handlerを逆アセンブルするには、次のコードを使用できます。 def vm_0C(state, vi_params): global instr reg_pos = 7 – (vi_arams[arg0] & 0x000000FF) tmpinstr = “mov [tmp_REG], %s” % resolve_reg(reg_pos) instr.append(tmpinstr) return
繰り返しますが、移行用のvm_handlersは理解するのが困難です。遷移の場合、vm_context.vi_params.Arg0およびvm_contextコンポーネント。vi_params.Arg1は、遷移が発生するインデントを格納します。この「ジャンプインデント」は、実際にはバイトコードでインデントされています。遷移ハンドラを解析するには、遷移領域のマーカーを再配置する必要があります。次のコードが適しています。 def computeLoc1(pos, vi_params): global instr jmp_offset = (vi_params[arg0] & 0x00FFFFFF) + (vi_params[arg1] & 0xFF000000) if jmp_offset < 0x7FFFFFFF: jmp_offset /= 0x18 # their increment by 0x18 is my increment by 1 else: jmp_offset = int((- 0x100000000 + jmp_offset) / 0x18) return pos+jmp_offset
最後に、特別な処理が必要な引数を使用してネイティブコマンドを実行するvm_handlerがあります。これを行うには、たとえばオープンアクセスのDistormツールなど、独自のx86コマンド用の逆アセンブラーが必要です。コマンドの長さはvm_context.vi_params.OpCode&0x0000FF00に保存されます。実行用のネイティブコマンドのオペコードは、引数に格納されます。ネイティブコードを実行するvm_handlerを解析するには、次のコードを使用できます。 def vm_04(vi_params, pos): global instr nBytes = vi_params[opCode] & 0x0000FF00 dyn_instr = pack(“<LLLL”, vi_params[arg0], vi_params[arg4], vi_params[arg8], vi_params[argC])[0:nBytes] dec_instr = distorm3.Decode(0x0, dyn_instr, distorm3.Decode32Bits) tmpinstr = “%s” % (dec_instr[0][2]) instr.append(tmpinstr) return
この時点で、各vm_handlersを解析するためのすべての関数をPythonで作成しました。トランジション用の領域をマークするコード、呼び出し後の仮想コマンドのIDを決定するコードなど、それらすべては、独自の逆アセンブラを作成するために必要です。このすべての後、バイトコードによって駆動できます。 図12.解凍および復号化されたFinFisherバイトコードの一部たとえば、図12に示すバイトコードから、次の出力を取得できます。
図12.解凍および復号化されたFinFisherバイトコードの一部たとえば、図12に示すバイトコードから、次の出力を取得できます。 mov tmp_REG, 0 add tmp_REG, EBP add tmp_REG, 0x10 mov tmp_REG, [tmp_REG] push tmp_REG mov tmp_REG, EAX push tmp_REG
6.この仮想マシンの使用を理解する
すべての仮想ハンドラーを分析し、独自のカスタム逆アセンブラーを構築した後、仮想コマンドを再度見て、作成の基本的な考え方を理解できます。最初に、仮想化保護がアセンブラレベルで適用されていることを理解する必要があります。作成者は、独自のチームを独自のやや複雑なチームに変換し、特別な仮想CPUで実行します。このために、一時的な「レジスタ」(tmp_REG)が使用されます。いくつかの例を見て、この変換がどのように機能するかを理解できます。前の例から仮想コマンドを取ります- mov tmp_REG, EAX push tmp_REG
-彼女は自分のチームから変身しましたpush eax。仮想化を使用する場合、タイムステップの一時レジスタを使用して、コマンドをより複雑なものに変更します。別の例を挙げます。 mov tmp_REG, 0 add tmp_REG, EBP add tmp_REG, 0x10 mov tmp_REG, [tmp_REG] push tmp_REG
これらの仮想化コマンドに変換されたネイティブコマンドを以下に示します(regは独自のレジスタの1つです)。 mov reg, [ebp+0x10] push reg
ただし、一連のコマンドを仮想化する方法はこれだけではありません。他のアプローチでは、保護のための仮想マシンの他の用途があります。たとえば、1つではなく複数の一時レジスタを使用して、NOR数学ロジック(両方の入力が負の場合)を使用する仮想マシンによる保護の商用実装があります。順番に、FinFisherはここまで行かず、すべての自社チームを転換しませんでした。以下のような数学的なコマンド、 -それらの多くは、仮想化されていますが、いくつかはそうではないかもしれないadd、imulとdiv。これらのコマンドが元のバイナリである場合、vm_handler、保護されたファイルで処理するために、独自のコマンドの実行を担当します。発生する唯一の変更は、EFLAGSとその独自のレジスタが独自のコマンドの実行直前に取得され、実行の完了後に削除されることです。これにより、各チームの仮想化を回避できます。バイナリを仮想マシンで保護することの重大な欠点は、パフォーマンスへの悪影響です。 FinFisher仮想マシンの場合、各vm_instruction(vm_dispatcher + vm_handlerを処理するために実行されるコマンドの数をカウントすることに基づいて、内部コードの場合よりも速度が約100倍遅いと概算します)したがって、バイナリの選択された部分のみを保護することは理にかなっています。これは、分析したFinFisherサンプルでそれらが行うこととまったく同じです。さらに、既に述べたように、一部の仮想マシンハンドラーは独自の関数を直接呼び出すことができます。その結果、仮想マシン保護のユーザー(つまり、FinFisherの作成者)は、アセンブラー段階で、その助けを借りて保護する機能を決定できます。マークされた機能については、チームは仮想化されます。残りについては、元の関数は対応する仮想ハンドラーによって呼び出されます。したがって、バイナリファイルの最も興味深い部分は保護されたままですが、コードの実行にかかる時間は短くなります(図13)。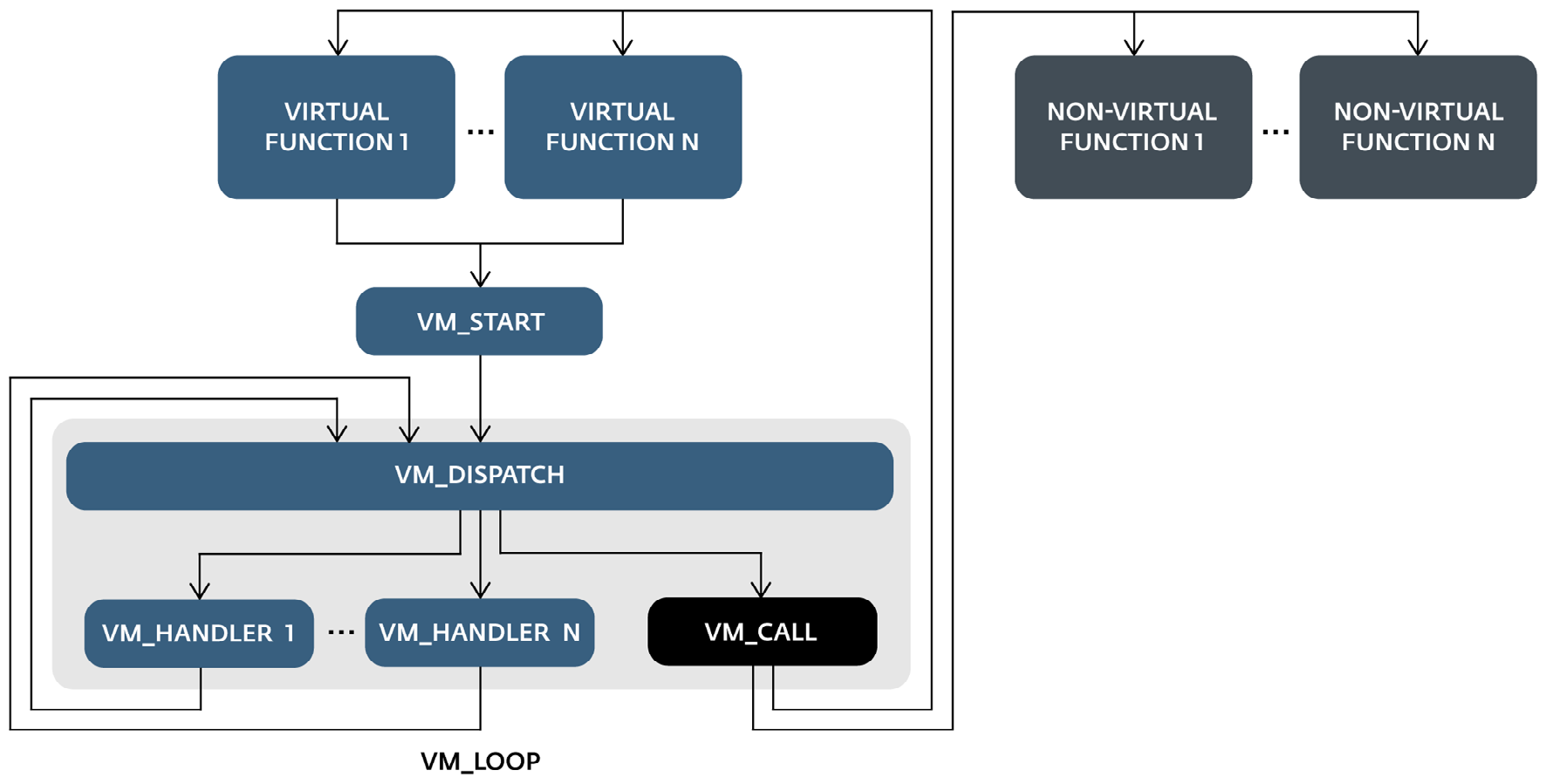 13. , FinFisher, ,
13. , FinFisher, ,7. FinFisher
パーサーが処理する必要のあるバイトコード長に加えて、FinFisherのサンプルには何らかのミキシングがあることを覚えておく必要があります。保護には同じ仮想マシンが使用されますが、仮想オペコードとvm_handlers間の対応の定義は常に一致するとは限りません。それらはランダムにペアにできます(そして、これが起こります)。これらのペアは、分析するFinFisherサンプルごとに異なります。つまり、このサンプルの0x5仮想オペコードのvm_handlerはコマンドを処理し、mov [tmp_REG], arg0別の保護されたサンプルでは別の仮想オペコードに割り当てることができます。この問題を解決するために、分析されたvm_handlersのそれぞれに署名を使用できます。付録AのPython IDAのスクリプトは、図7からダイアグラムを取得した後に適用できます(このマニュアルの最初のセクションで説明したように、jz / jnz遷移の難読化を削除することが特に重要です)。(マイナーな改善により、FinFisherの更新バージョンでvm_handlersが変更された場合、このスクリプトを使用して署名を復元することもできます。)前述のように、FinFisherサンプルの最初のvm_handlerは、分析中に遭遇するJLとは異なる場合がありますサンプルの結果になりましたが、スクリプトはすべてのvm_handlersを正しい方法で決定します。8.仮想マシンを使用しない逆アセンブルコードのコンパイル
分解していくつかの変更を加えた後、コードをコンパイルできます。私たちは、仮想チームを独自のものとして使用します。その結果、保護されていない純粋なバイナリコードが取得されます。vm_instructionsコマンドのほとんどは、単純なコピーでコンパイルできます。これは、逆アセンブラの出力では、基本的にコマンドがネイティブコマンドのように見えるためです。ただし、一部のセクションは特別な方法で変更する必要があります。•tmp_REG-tmp_REGをグローバル変数として定義したため、格納されているアドレスが逆参照されている場合はコードを変更する必要があります。(x86コマンドセットでは、グローバル変数のアドレスを逆参照することはできません。)たとえば、仮想マシンには仮想コマンドが含まれますmov tmp_REG, [tmp_REG] 次のように書き換える必要があります。 push eax mov eax, tmp_REG mov eax, [eax] mov tmp_REG, eax pop eax
•フラグ-仮想チームはフラグを変更しませんが、独自の数学チームが変更します。したがって、仮想化されたバイナリの仮想数学命令でもこれを行わないことが重要です。つまり、命令を実行する前にフラグを保存し、実行の完了後にフラグを復元する必要があります。•遷移と呼び出し-マーカーを仮想コマンド(遷移)または関数(呼び出し)の領域に移動する必要があります。•API関数呼び出し-ほとんどの場合、動的にロードされますが、それ以外の場合は、バイナリファイルのIAT(アドレスインポートテーブル)からアクセスされるため、それに応じて処理する必要があります。•グローバル変数、ネイティブコード-一部のグローバル変数は、仮想化されたバイナリに保存する必要があります。また、FinFisherドロッパーには、x64とx86を切り替える機能があり、これはプロセッサーモードで実行されます(実際、これはコマンドでのみ行われretfます)。これらはすべて、コンパイル中に保持する必要があります。結果によっては、逆アセンブラの出力で、コンパイル可能な純粋に独自のコマンドを取得するために、さらにいくつかの変更を行う必要がある場合があります。次に、好みのコンパイラを使用して、仮想マシンなしでバイナリにコードをコンパイルする必要があります。おわりに
このガイドでは、FinFisherが2つの方法を使用して主要な成果物を保護する方法について説明しました。保護の目的は、ウイルス対策の検出に対抗することではなく、リバースエンジニアリングの問題を作成することにより、スパイウェアで使用される構成ファイルと新しい手法を隠すことです。難読化されたスパイウェアFinFisherの他の詳細な分析はこれまで公開されていないため、これまでこの保護メカニズムの開発者のタスクは正常に完了したと見なすことができました。分解に対する保護レベルが自動化された方法によってどのように克服できるか、仮想マシンを効果的に分析する方法を示しました。このガイドが、FinFisherで保護された仮想マシンのサンプルを分析するリバースエンジニアリングの専門家を助け、仮想マシン全体を使用した保護の詳細をよりよく理解することを願っています。付録A
FinFisherでvm_handlersハンドラーに名前を付けるためのPython IDAスクリプト
このスクリプトは、GitHubのESETリポジトリでも利用できます。 import sys SIGS={'8d4b408b432c8b0a90800f95c2a980000f95c03ac275ff631c':'case_0_JL _loc1','8d4b408b432c8b0a9400074ff631c':'case_1_JNP_loc1','8d4b408b432c 8b0a94000075a90800f95c2a980000f95c03ac275ff631c':'case_2_JLE_loc1','8d4 b408b7b508b432c83e02f8dbc38311812b5c787cfe7ed4ae92f8b066c787d3e7e 4af9b8e80000588d80' : 'case_3_vm_jcc', '8b7b508b432c83e02f3f85766c77ac6668 137316783c728d7340fb64b3df3a4c67e98037818b43c89471c64756c80775af83318588b6 32c' : 'case_4_exec_native_code', '8d4b408b98b438898833188b43c8b632c' : 'c ase_5_mov_tmp_REGref_arg0', '8b7b508b432c83e02f3f85766c77ac6668137316783c7 28d7340fb64b3df3a4c67e98037818b43c89471c64756c80775af83318588b632c' : 'cas e_6_exec_native_code','8d4b408b432c8b0a94000075ff631c':'case_7_JZ_loc1' , '8d4b408b432c8b0a94000075a90800f95c2a980000f95c03ac275ff6318' : 'case_8_ JG_loc1','8d43408b089438833188b43c8b632c':'case_9_mov_tmp_REG_arg0','3 3c9894b8833188b632c8b43c' : 'case_A_zero_tmp_REG', '8d4b408b432c8b0a980000 75ff631c':'case_B_JS_loc1','8d4b40fb69b870002bc18b4b2c8b548148b4b889118 33188b43c8b632c' : 'case_C_mov_tmp_REGDeref_tmp_REG', '8d4b40fb69b870002bc 18b4b2c8b4481489438833188b43c8b632c' : 'case_D_mov_tmp_REG_tmp_REG', '8d4b 408b432c8b0a9100075ff631c':'case_E_JB_loc1','8d4b408b432c8b0a9100075a94 000075ff631c':'case_F_JBE_loc1','8d4b408b432c8b0a94000074ff631c':'cas e_10_JNZ_loc1','8d4b408b432c8b0a9080074ff631c':'case_11_JNO_loc1','8b7 b50834350308d4b408b414343285766c773f50668137a231c6472c280772aa8d57d83c7389 1783ef3c7477a300080777cb83c7889783ef8c647cf28077c3183c7dc67688b383c0188947 183c7566c7777fe668137176283c72c672d803745895f183c75c67848037df478b4314c674 08037288947183c75c67928037515f8b632c' : 'case_12_vm_call', '8d4b40b870002b 18b532c8b4482489438833188b43c8b632c' : 'case_13_mov_tmp_REG_tmp_REG_notRly ','8d4b408b432c8b0a9400075ff631c':'case_14_JP_loc1','8d4b40fb69b870002 bc18b4b2c8b5388954814833188b43c8b632c' : 'case_15_mov_tmp_REG_tmp_REG', '8 d4b408b432c8b0a9080075ff631c':'case_16_JO_loc1','8d4b408b432c8b0a90800f 95c2a980000f95c03ac274ff631c':'case_17_JGE_loc1','8b4388b089438833188b4 3c8b632c' : 'case_18_deref_tmp_REG', '8d4b408b4388b9d3e089438833188b43c8b6 32c' : 'case_19_shl_tmp_REG_arg0l', '8d4b408b432c8b0a98000074ff631c' : 'ca se_1A_JNS_loc1','8d4b408b432c8b0a9100074ff631c':'case_1B_JNB_loc1','8b 7b2c8b732c83ef4b924000fcf3a4836b2c48b4b2c8b438894124833188b43c8b632c' : 'c ase_1C_push_tmp_REG', '8d4b408b432c8b0a94000075a9100075ff6318' : 'case_1D_ JA_loc1','8d4b40b870002b18b532c8b448241438833188b43c8b632c':'case_1E_ad d_stack_val_to_tmp_REG', '8b7b508343503066c77ac3766813731565783c728d4b40c6 72e803746fb6433d3c783c058947183c758d714fb64b3df3a45ac671280377a8b383c01889 47183c7566c777f306681371fac83c72c671f803777895f183c75c677080372b47c6798037 618b4b14894f183c75c67778037b48b632c8d12' : 'case_1F_vm_jmp', '8d4b408b914b 8833188b43c8b632c' : 'case_20_add_arg0_to_tmp_REG', '8d4b408b98b4388918331 88b632c8b43c' : 'case_21_mov_tmp_REG_to_arg0Dereferenced' } SWITCH = 0 # addr of jmp dword ptr [eax+ecx*4] (jump to vm_handlers) SWITCH_SIZE=34 sig = [] def append_bytes(instr, addr): for j in range(instr.size): sig.append(Byte(addr)) addr += 1 return addr defmakeSigName(sig_name,vm_handler): print “naming %x as %s” % (vm_handler, sig_name) MakeName(vm_handler,sig_name) return if SWITCH == 0: print “First specify address of switch jump - jump to vm_handlers!” sys.exit(1) foriinrange(SWITCH_SIZE): addr = Dword(SWITCH+i*4) faddr = addr sig = [] while 1: instr = DecodeInstruction(addr) if instr.get_canon_mnem() == “jmp” and (Byte(addr) == 0xeb or Byte (addr) == 0xe9): addr = instr.Op1.addr continue if instr.get_canon_mnem() == “jmp” and Byte(addr) == 0xff and Byte (addr+1) == 0x63 and (Byte(addr+2) == 0x18 or Byte(addr+2) == 0x1C): addr = append_bytes(instr, addr) break if instr.get_canon_mnem() == “jmp” and Byte(addr) == 0xff: break if instr.get_canon_mnem() == “jz”: sig.append(Byte(addr)) addr += instr.size continue if instr.get_canon_mnem() == “jnz”: sig.append(Byte(addr)) addr += instr.size continue if instr.get_canon_mnem() == “nop”: addr += 1 continue addr = append_bytes(instr, addr) sig_str = “”.join([hex(l)[2:] for l in sig]) hsig = ''.join(map(chr, sig)).encode(“hex”) for key, value in SIGS.iteritems(): if len(key) > len(sig_str): ifkey.find(sig_str)>=0: makeSigName(value,faddr) else: ifsig_str.find(key)>=0: makeSigName(value,faddr)