Splunkにクラスターを展開する方法についてよく聞かれます。 運用中、多くのユーザーは、スタンドアロンからクラスター構成に切り替える必要があります。これにより、データの保存とインデックス付けのための安定したシステムと、機器の誤動作に依存しないデータの常時可用性が提供されます。 したがって、この記事のフレームワークでは、Splunkにインデクサークラスターを展開する方法を説明します。これにより、インデクサーの1つがクラッシュした場合でも、保存されているすべてのデータに常にアクセスできます。
挑戦する
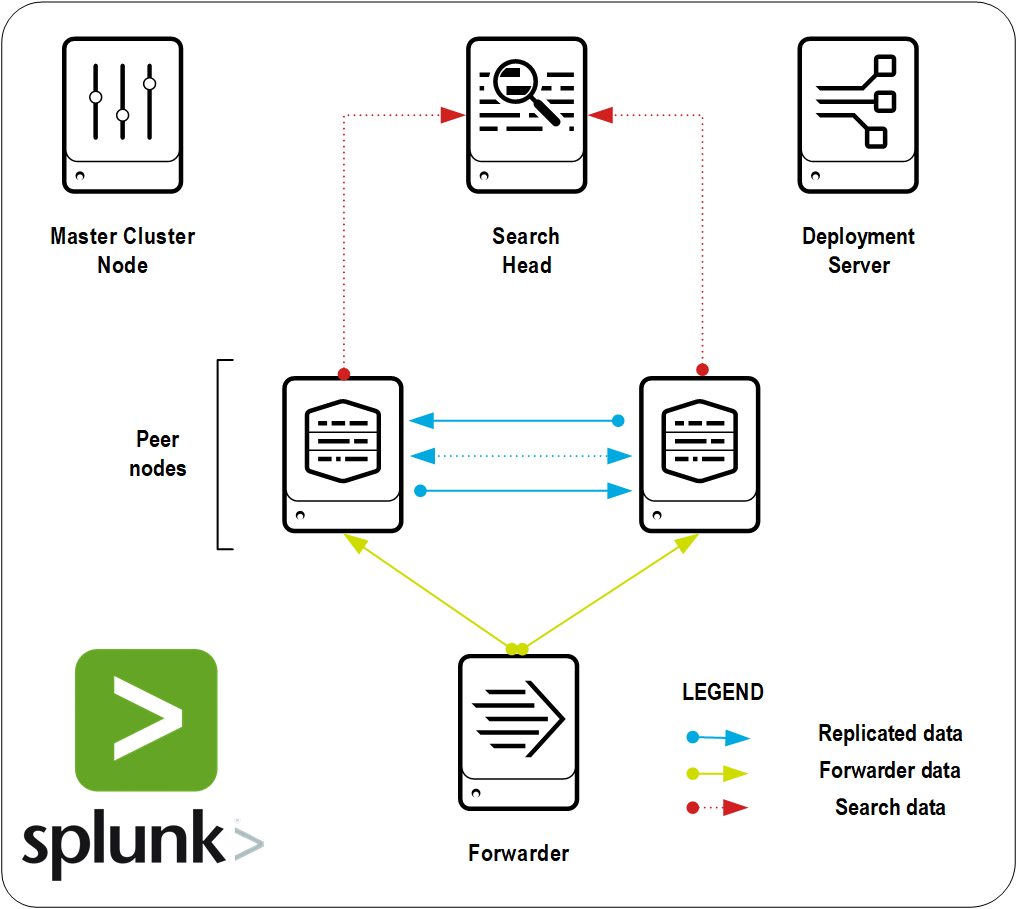
データをロードして複製するクラスターを構築し、インデクサーに2つのコピーを作成します。
これを行うには、次のものが必要です。
インデクサー(2) -データがレプリケートされるノード。
検索ヘッド -インデクサーに保存されたデータの検索、ダッシュボードの作成、アラートの作成などのためのグラフィカルインターフェイスであるコンポーネント
クラスターマスター -他のすべてのノードのアクションを調整するメインノード。
Forwarder(s) -データ転送を担当するコンポーネント。
Deployment Server-すべてのフォワーダーにデータ送信パラメーターを送信するコンポーネント(この場合、Search Headと一緒に配置されます)。
クラスター展開
1.要件の定義
クラスターをデプロイする前に、クラスターの要件を決定する必要があります。
•
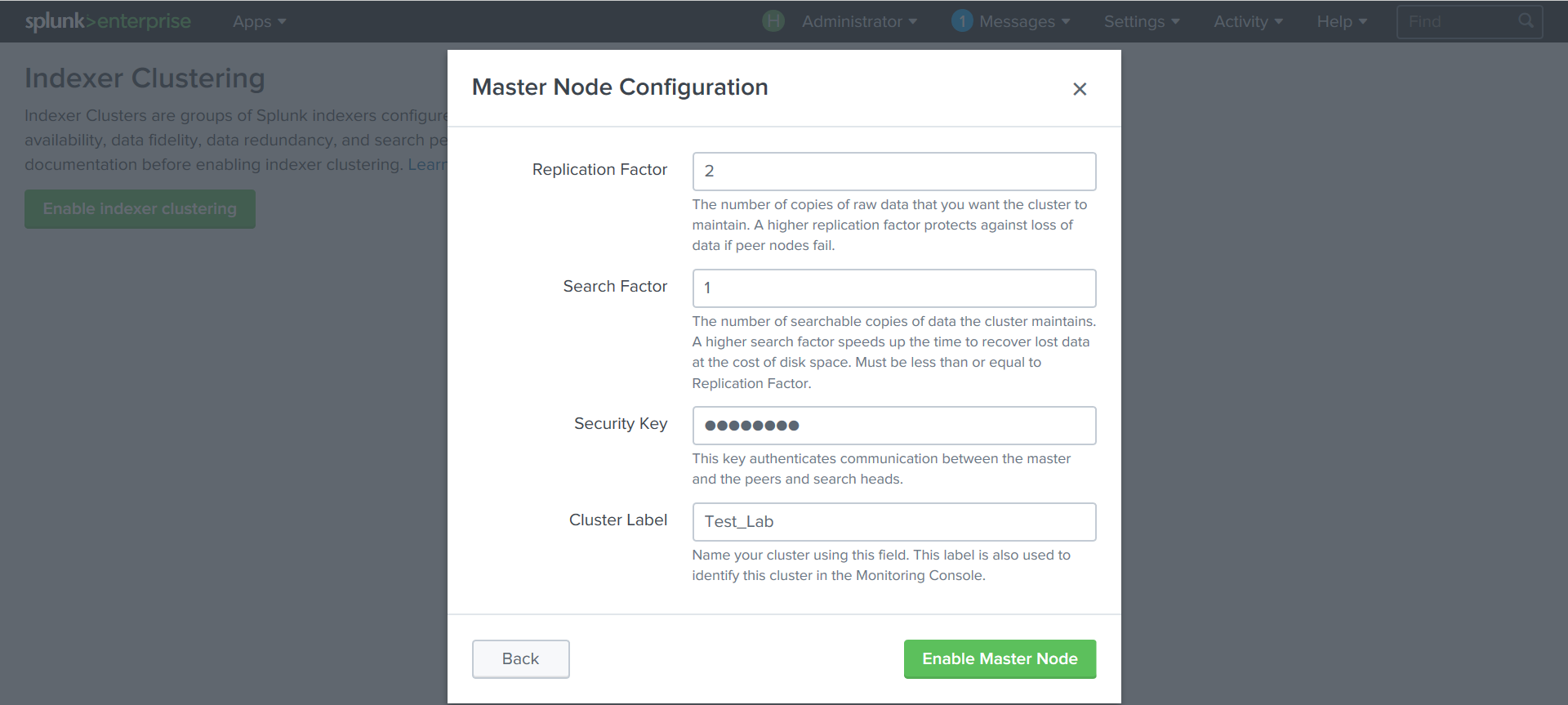
複製係数 -データのコピー数。
メモリ容量の増加とシステムの耐障害性の観点から最適な係数を選択する必要があります。 システム操作中に複製係数を増やすことは可能ですが、追加コピーの作成中にクラスターの速度が低下します。
この場合、レプリケーション係数= 2
•
検索ファクター検索係数は、インデックス付きデータのコピーが検索でサポートされる数をクラスターに伝えます。 これは、クラスターがノード損失から回復できる速度を決定するのに役立ちます。 検索係数が高いほど、クラスターの回復は速くなりますが、より多くのメモリと処理能力も必要になります。 検索係数は、複製係数以下でなければなりません。 この例では、検索係数= 1です。
2. Splunk Enterpriseのインストール
インスタンスの数は、少なくともレプリケーション係数+ 2に等しくなければなりません。この例では、これらは4つのインスタンスです。 詳細なインストール手順については、
こちらをご覧ください 。
インデクサーには2つのインスタンスが必要ですが、インデックス作成のパフォーマンスを向上させるにはさらに多くのインスタンスを実行できます。 さらに、クラスターマスターとサーチヘッドのコピーが2つあります。
3.クラスタリングの有効化
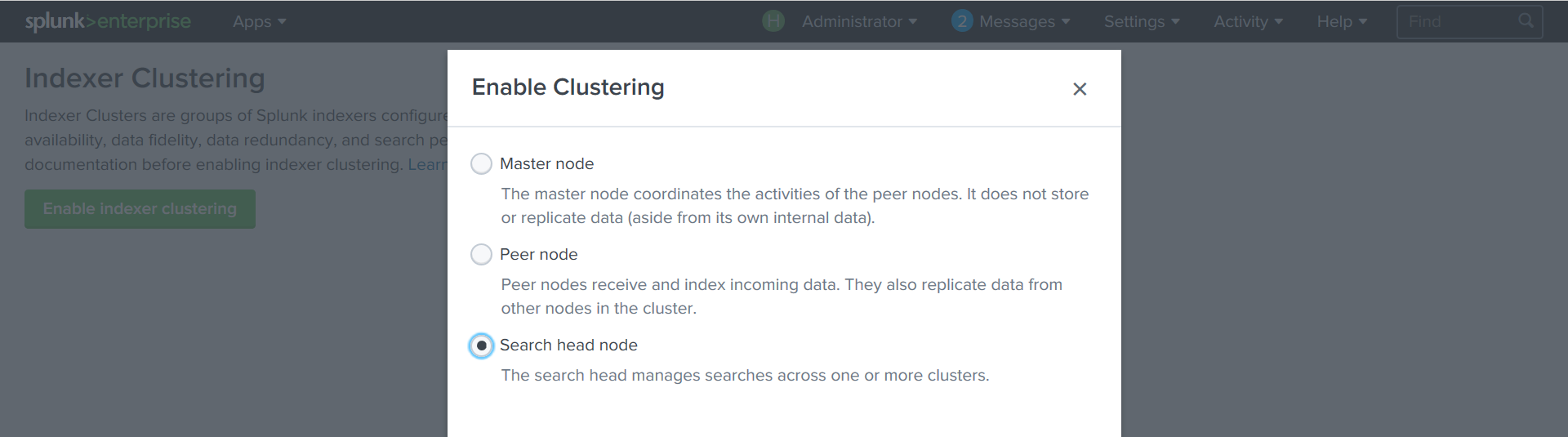
Splunkのインスタンスごとに、クラスター内でのその役割を決定する必要があります。
クラスターマスターを作成します。
設定-インデクサークラスタリング-インデクサークラスタリングを有効にする-マスターノード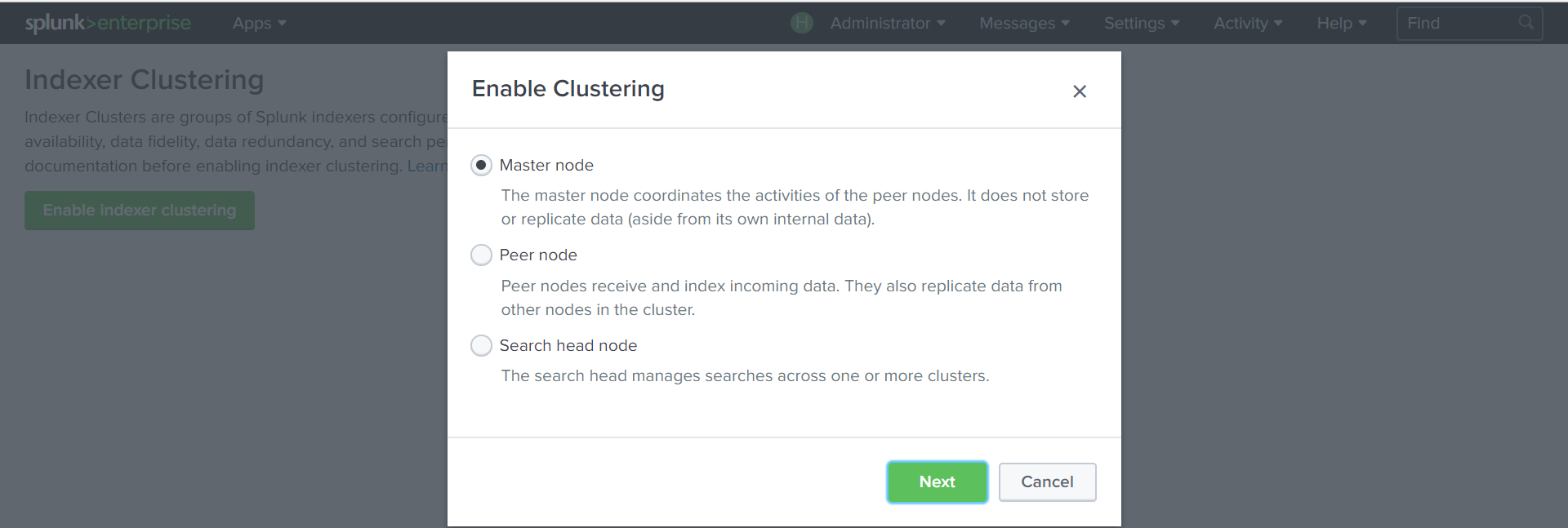
クラスターパラメーターを設定します:
レプリケーション、検索係数、クラスターノードが認証される
キー 。
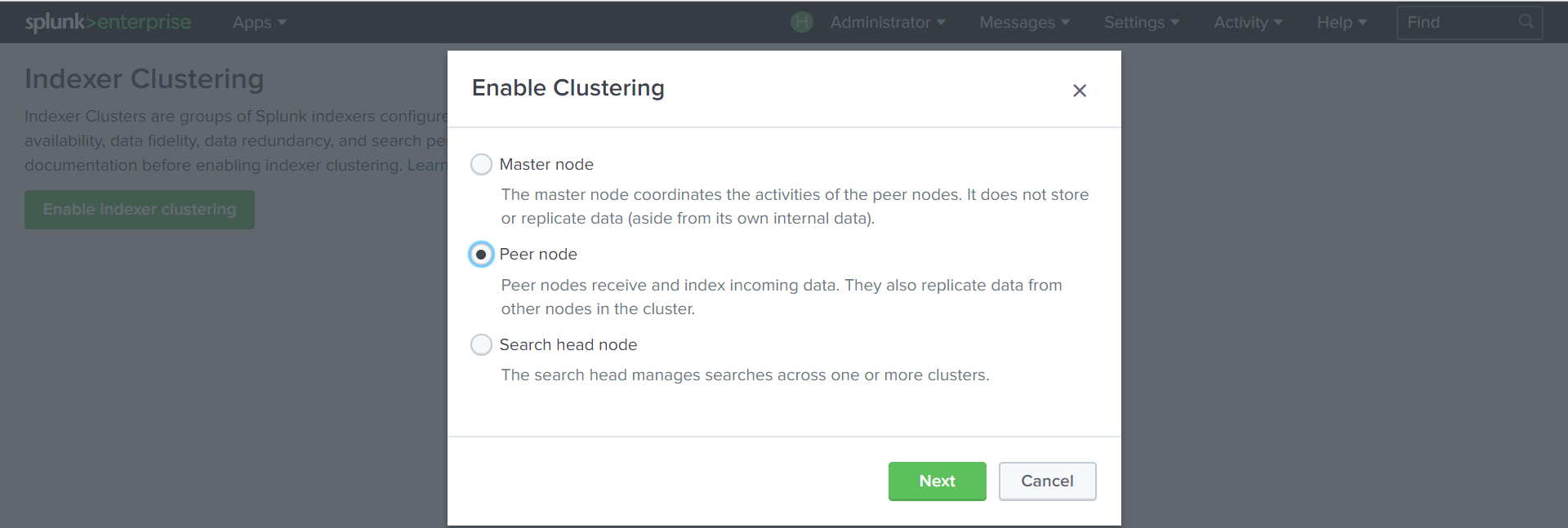
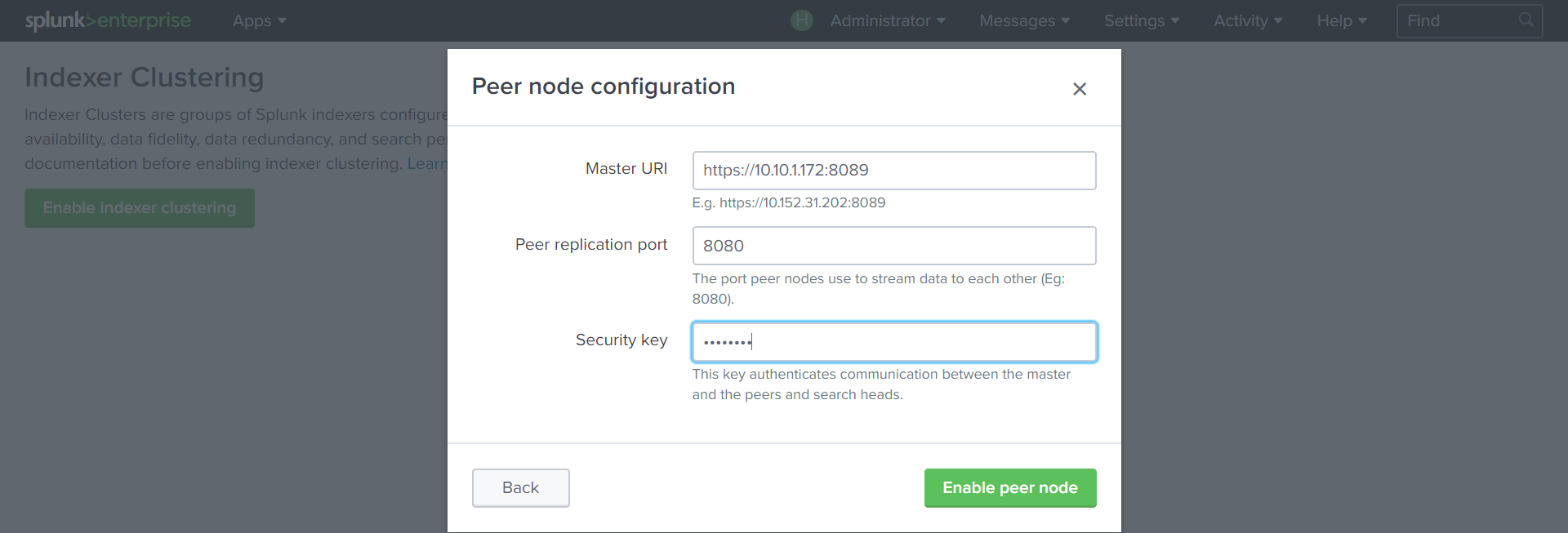
インデクサーを作成します。
設定-インデクサークラスタリング-インデクサークラスタリングを有効にする-ピアノードポート
8089で
クラスターマスター アドレス 、データがレプリケートされるポート(
8080 )、および前の手順で作成された
キーを指定します。
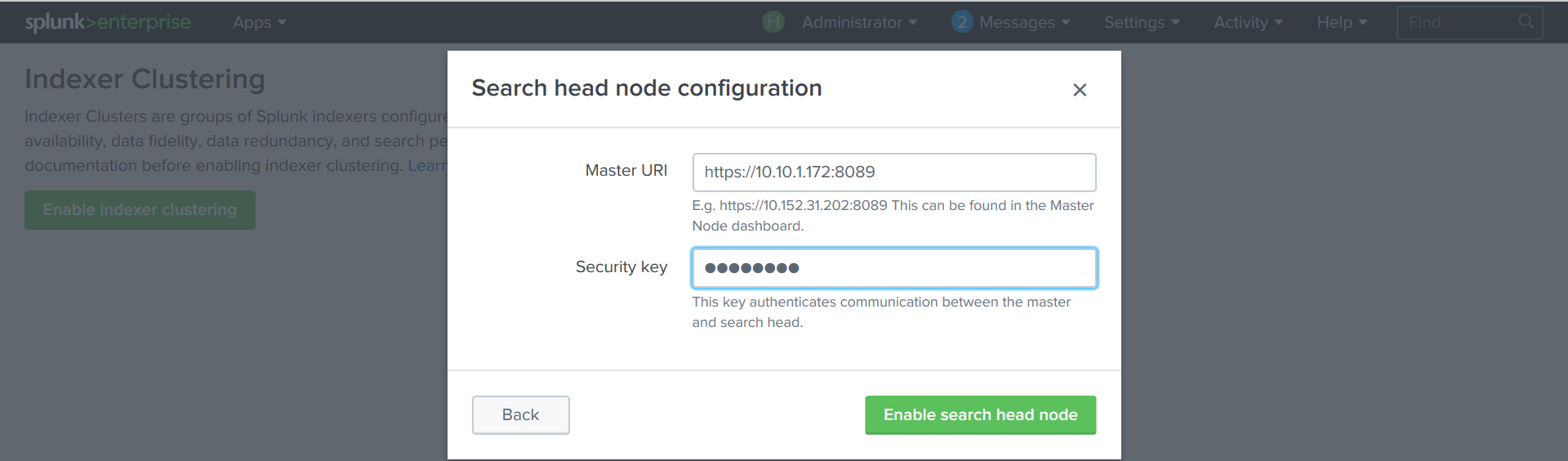
検索ヘッドを作成します。
設定-インデクサークラスタリング-インデクサークラスタリングを有効にする-検索ヘッドノード。ポート
8089と
キーで
クラスタマスターアドレスを指定
し ます 。
すべてのコンポーネントを作成したら、各マシンでSplunkを再起動する必要があります。
4.新しいインデックスの作成
次に、新しいインデックス
テストを作成します。 クラスターマスターはインデックスを作成し、各インデクサーに指定されたインデックスを作成します。
これを行うには、
indexs.confファイルを... splunk / etc / master-apps / _cluster /
defaultから/ opt / splunk / etc / master-apps / _cluster /
localディレクトリにコピーします
データの新しいインデックスと保存場所をファイルに追加します。
[test]
repFactor = auto
homePath = $SPLUNK_HOME/var/lib/splunk/testdb/db/
coldPath = $SPLUNK_HOME/var/lib/splunk/testdb/colddb
thawedPath = $SPLUNK_HOME/var/lib/splunk/testdb/thaweddb次に、ウィザードからインデクサーに対して設定を実行する必要があります。
5.フォワーダーと展開サーバーの構成
ここで書いたForwarderとDeployment Serverの構成方法について。 したがって、この記事では、クラスターを使用した状況の設定の違いに注意します。
この場合、Search HeadにDeployment Serverを構成し、インストール中にそのIPアドレスを指定しました。
フォワーダーを設定してクラスターにデータをロードするには、次の内容の別の
outputs.confファイルが必要です。
[tcpout]
defaultGroup=my_LB_peers
[tcpout:my_LB_peers]
autoLBFrequency=40
server=IP_indexer_1:9997, IP_indexer_2:9997
useACK=trueoutputs.confファイルで、クラスターインデクサーのIPアドレスを指定する必要があります。
ForwarderとDeployment Serverをセットアップしたら、データをダウンロードし、Search Headで検索を実行できます。 インデックスのリストのSHでは、インデックスのテストは行われませんが、このインデックスの検索が実行されることに注意してください。
おわりに
したがって、データをレプリケートするクラスターを展開し、その中に新しいインデックスを作成し、クラスターへのデータ送信の構成方法を指示しました。
ご注意ください :
展開プロセス中にエラーが発生した場合は、次の点を確認してください。
1.すべてのポートがファイアウォール用に開いている必要があります(8089、8080、9997)
2. Splunkで使用されるマシンの名前は一致してはなりません。 これらは..splunk /etc/system/local/server.confディレクトリで変更できます
[general]
serverName = Indexer1
pass4SymmKey = $1$0rPdsD/7byyPこのトピックまたはSplunk全般に興味がある場合は、コメントを書いてください。回答させていただきます。 また
、ブログにはSplunkに関連する他の多くの記事があり、実装されたケース、機能、その他について興味深いことをたくさん学ぶことができます。 新しい記事に遅れないようにしたい場合は、
VKグループと
電報チャンネルを購読してください。 また、
ウェブサイトのフォームからリクエストを作成することもできます。
