Javaは非常に一般的なプラットフォームであり、ビッグデータから始まり、マイクロサービス、モノリス、エンタープライズなどで終わる非常に異なるものが書き込まれます。 そして、原則として、これらはすべてLinuxサーバーにデプロイされます。 同時に、それに応じて、Javaで書く人は、まったく異なるオペレーティングシステムでこれを行うことがよくあります。 そこにあります:
- コードを書く;
- デバッグ、テスト。
- その後、jarにパッケージ化されます。
- Linuxに送信され、動作します。
機能するという事実には特別な魔法はありません。 しかし、これにより、そのような開発者はクロスプラットフォームの世界で少し「砂糖」になり
、実際のオペレーティングシステムで実際にどのように機能する
かを理解したくないという事実につながり
ます 。

一方、サーバーを管理し、サーバーにJVMをインストールし、jarファイルとwarファイルを送信し、Linuxの世界から見ると、次のすべての人がいます。
- エイリアン;
- 専有;
- ソースからは収集されません。
- 一部のjarアーカイブによって配信されます。
- サーバー上のすべてのメモリを「食べる」。
- 一般に、人間として振る舞いません。
Alexey Ragozinの Highload ++に関するレポートの目的は、そのデコードがさらに進んでおり、
Linuxユーザー向けの
Javaの機能、したがって
Java開発 者向けのLinuxの機能について説明することでした。
多くの問題があり、それらはすべて興味深いものであり、シェルが同じ漏斗に2回落ちることはないため、レポートは報告会ではありません。 したがって、すでに知られている「穴」を塞ぐことは敗北主義者の立場です。 代わりに、次のことについて話しましょう。
- JVM実装機能
- Linux実装機能:
- どうしてドッキングできませんか。

Javaには仮想マシンがあり、Linuxは、他の最新のオペレーティングシステムと同様に、本質的に仮想マシンです。 JavaとLinuxの両方に、
メモリ管理 、
スレッド 、および
APIがあり
ます 。
言葉は似ていますが、実際には非常に異なるものがしばしばそれらの下に隠されています。 実際に、これらの点を検討し、記憶に最も注意を払います。
Javaメモリ
JVM HotSpotの実装についてのみ説明します。これらはOpen JDKとOracle JDKです。 つまり、おそらくIBM J9にはいくつかの特性がありますが、残念ながら、それらについては知りません。 HotSpot JVMについて話している場合、世界の状況は次のとおりです。 まず、JavaにはJavaオブジェクトが存在する領域があります。いわゆるヒープ、またはロシア語ではガベージコレクターが動作する場所です。 このメモリ領域は、原則として、プロセス空間の大部分を占めます。 ヒープは、順番に、若いスペースと古いスペース(若い世代/古い世代)に分割されます。 JVMのサイズ設定のダービーに入ることなく、重要なことは、JVMに、ヒープスペースが拡大できる最大サイズを定義する「-Xmx」パラメーターがあることです。
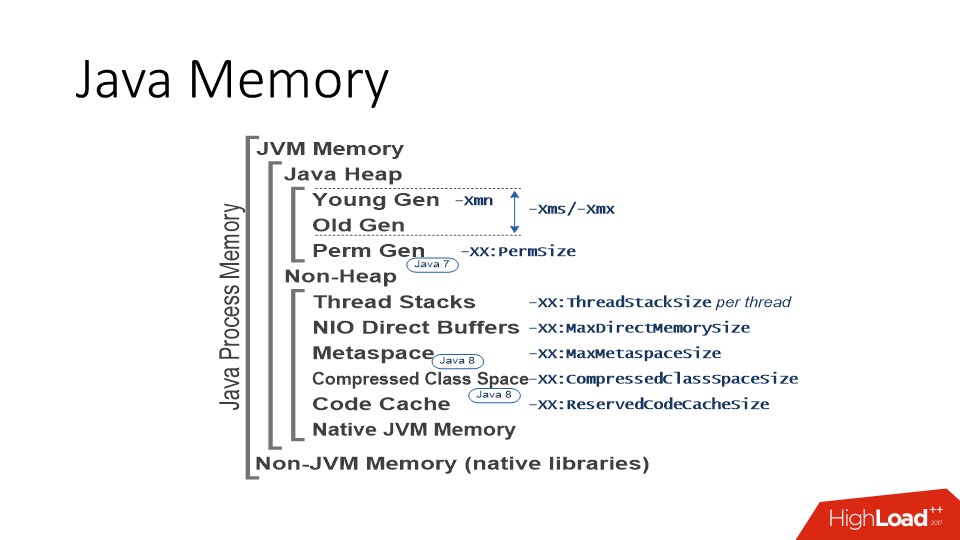
そして、多くのオプションがあります:
- 若い空間の寸法を個別に管理できます。
- 最大ヒープサイズをすぐに設定できます。
- または、彼が徐々に成長できるようにします。
部品が多すぎる-制限があることが重要です。 そして、原則として、これはJVMを使用するすべての領域に対する一般的なアプローチです。 つまり、上の図にリストされているほとんどすべての領域には一定の制限があります。 JVMは、制限に基づい
て アドレススペースを
直ちに予約し、 必要に応じて、この範囲の
実メモリリソースを
要求します。 これは理解することが重要です。
ヒープに加えて、他のメモリ消費者がいます。 これらの中で最も重要なのは、ストリームスタックのメモリ領域です。 Javaのスレッドは通常のLinuxスレッドであり、特定のメモリサイズが予約されているスタックがあります。 スレッドが多いほど、プロセスメモリに割り当てられるスタックが多くなります。 Javaのスレッド数は数百および数千単位で測定できるため、特に200 MBのヒープがあり、50〜100スレッドのThreadPoolがあるステートレスマイクロサービスがある場合は、この数値が非常に重要になることがあります。
さらに、いわゆる
NIO ダイレクト バッファー もあります 。これらはJavaの特別なオブジェクトで
、ヒープ外のメモリを操作できます。 通常、I / Oの操作に使用されます。これは、CコードとJavaコードの両方から直接アクセスできるメモリであるためです。 したがって、この領域にはAPIを介してアクセスでき、最大制限もあります。
残りはメタデータ、ある種の生成されたコード、それらのメモリは通常大きな値には成長しませんが、1つあります。
これらの特別な領域に加えて、JVMがそれぞれC ++で記述されていることを忘れないでください。
- mallocおよび従来のメモリ割り当て。
- JVMにロードされるライブラリ(静的または動的にリンクされ、メモリも使用できます)。
そして、このメモリは私たちのスキームに従って分類されるのではなく、単にCランタイムの標準的な手段によって割り当てられたメモリです。 Cにも問題があり、かなり平らな場所にあります。
たとえば、ここではjar形式でJavaコードを配布しています。 Jarはzipアーカイブであり、zlibライブラリを使用して作業します。 何かを解凍するために、zlibは解凍に使用されるバッファを割り当てる必要があり、もちろんメモリが必要です。 すべては問題ありませんが、1つの大きなjarが作成され、ニュアンスが発生した場合、いわゆるuber-jarのmodがあります。
このようなjarファイルから起動しようとすると、同時に解凍するために多くのzlibスレッドが開かれます。 また、Javaの観点から見ると、すべてが順調です。ヒープは小さく、すべての領域は小さくなっていますが、プロセスのメモリ消費は増大しています。 もちろん、これは「臨床的」なケースですが、そのようなJVMを考慮する必要があります。 たとえば、-Xmxを1 GBに設定し、JavaをDockerコンテナに配置し、コンテナのメモリ制限も1 GBに設定すると、
JVMはそれに適合しません 。 もう少しスローする必要がありますが、その量はスレッド数やコードの動作など、多くの要因に正確に依存します。
これが、JVMがメモリでどのように機能するかです。
さて、いわば、聴衆の別の部分です。
Linuxメモリ
Linuxでは、
ガベージコレクターはありません。
記憶の観点から見ると
、彼の作品
は完全に異なっています。 彼には、
ページ分割された
物理的記憶があります。 独自の
アドレス空間を持つ
プロセスがあり
ます 。 彼は、ページの形式でこのメモリのリソースがプロセス間で何らかの形で分割され、仮想アドレス空間で動作して仕事をするようにする必要があります。

通常、ページサイズは4キロバイトです。 実際、これはそうではありません; x86アーキテクチャでは、大きなページのサポートが非常に長い間存在していました。 Linuxでは、比較的最近登場しましたが、少し奇妙な状況です。 Linuxでラージページ(Transparent Huge Tables)のサポートが登場したとき、多くの人々は、Linuxでラージページを提供する際のニュアンスに起因するパフォーマンスの低下に関連するすくいを踏みました。 そして間もなく、インターネットはそれらを害の道から消すための勧告で一杯になりました。 その後、Linuxでの大きなページの操作に関連するいくつかのバグが修復されましたが、沈殿物は残りました。
しかし、現時点では、例えば、どのバージョンからラージページサポートをデフォルトで有効にでき、心配する必要はないのか、明確な理解はありません。
だから注意してください。 Linuxサーバーでカーネル消費が突然突然増加した場合、問題は、大規模なページがオンになっているだけで、ほとんどのディストリビューションでデフォルトでオンになっていることです。
そのため、カーネルの観点から見ると、Linuxには
多くの管理
ページが
あります 。 プロセスの観点から、アドレス範囲を予約するアドレス空間があります。
予約されたアドレス空間は、リソースではなく、何もありません 。その
中には何もありません 。 このアドレスにアクセスすると、何も存在しないため、セグメンテーション違反が発生します。
ページをアドレススペースに表示するには、わずかに異なるsyscallが必要です。プロセスはオペレーティングシステムに「これらのアドレスに1 GBのメモリが必要です。」と伝えます。 しかし、この場合でも、そこにあるメモリもすぐには表示されず、そのトリックもあります。
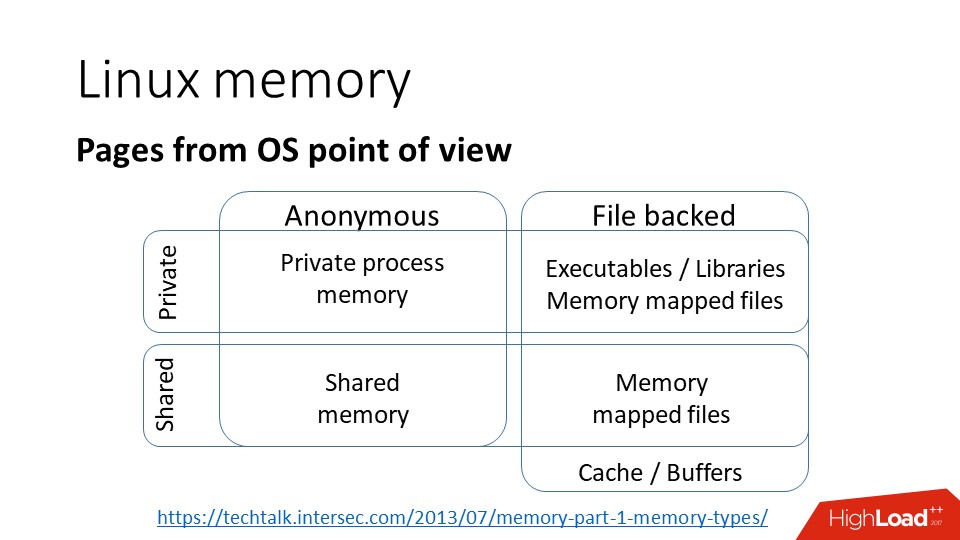
カーネルの観点から見ると、ページの分類は次のとおりです。ページがあります。
a)
private 、つまり、それらが1つのプロセスに属し、1つのプロセスのみのアドレス空間で使用できることを意味します。
b)
匿名 -これはファイルに関連付けられていない通常のメモリです。
c)
メモリマッピングファイル -ファイルをメモリにマッピングします。
d)
shared 、次のいずれかです。
- Copy-On-Write 。つまり、プロセスが分岐すると、書き込まれてページがプライベートになるまで、両方のプロセスでメモリが使用可能になります。
- 共有ファイルを介して、つまり、複数のプロセスが同じファイルをメモリにマップする場合、ページを共有できます。
一般に、オペレーティングシステムの
カーネルの観点から見ると、すべてが非常に単純です。
シンプルですが、完全ではありません。
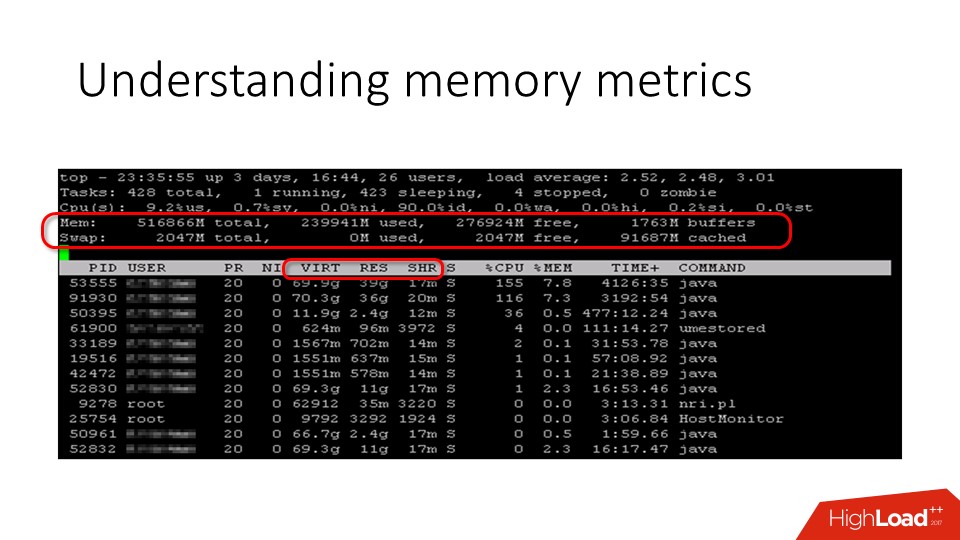
メモリに関してサーバーで何が起こっているのかを理解したい場合は、トップに移動して、そこにいくつかの数値を表示します。 特に、
使用済みメモリと
空きメモリがあります 。 サーバー上の空きメモリの量については、さまざまな意見があります。 これは5%であると考える人もいますが、実際には、
物理メモリの0%も標準です 。これは、空きメモリカウンタとは実際にはすべてが空きメモリではないためです。 それは実際にははるかに大きく、通常はページキャッシュに隠されているだけです。
プロセスに関して
、 topは3つの興味深い列を示しています。
- 仮想メモリ ;
- 常駐メモリ ;
- 共有メモリ 。
リストの最後のメモリは、単に共有されているページです。 しかし、
常駐メモリでは
、すべてが少し複雑です。 これらのメトリックスについて詳しく説明します。

前にも言ったように、使用済みメモリと空きメモリはかなり役に立たないメトリックです。 オペレーティングシステムには
ファイルキャッシュがあるため、サーバーにはまだ使用されていないメモリがあり
ます。メモリページは常にクリアされ、ファイルキャッシュからより重要なタスクに使用されるため、すべての最新のオペレーティングシステムはすべての空きメモリを使用します。 したがって、
すべての空きメモリは徐々にキャッシュに移動し、戻ってきません 。
仮想メモリメトリックは、オペレーティングシステムの観点からはまったくリソースではありません。 100テラバイトのアドレススペースを簡単に割り当てることができます。それだけです。 これを行うと、アドレスXからアドレスYまでスペースが予約されていることを誇りに思うことができますが、それ以上はありません。 したがって、それをリソースとして見て、たとえば、プロセスの仮想サイズがあるしきい値を超えたというアラートを設定することは無意味です。
Javaに戻ると、JVMコードはこれらの領域がアドレス空間の観点から連続していることを期待しているため、すべての特別な領域を事前に予約します。 そのため、アドレスは事前に杭打ちする必要があります。 この点で、256 MBのヒープでプロセスを開始すると、その仮想サイズが2ギガバイトを超えていることが突然わかります。 これらのギガバイトが必要であり、JVMがそれらを利用できるからではなく、単にデフォルトにします。 少なくとも、JVMを書いた人たちはそう思っていました。 ただし、これは、後でサーバーサポートを扱う人々の意見に必ずしも対応するものではありません。
常駐サイズ -現実に最も近いメトリック-これは、スワップではなく、メモリ内のプロセスによって使用されるメモリページの数です。 しかし、彼女も少し独特です。

キャッシュ
キャッシュに戻ります。 前述したように、キャッシュは原則として
空きメモリですが、例外が存在する場合もあります。 キャッシュ内のページがクリーンでダーティであるため(保存されていない変更を含む)。 キャッシュ内のページが変更された場合、別の目的で使用する前に、まずページをディスクに書き込む必要があります。 そして、これは全く異なる話です。 たとえば、JVMは大規模なヒープダンプを書き込みます。 彼女はゆっくりと、プロセスは次のとおりです。
- JVMはメモリにすばやく書き込みます。
- オペレーティングシステムは、ライトビハインドキャッシュの下にあるすべての空きメモリを提供し、このメモリはすべて「ダーティ」です。
- ディスクへの書き込みが遅い。
このダンプのサイズがサーバーの物理メモリのサイズに匹敵する場合、他のすべてのプロセスに空きメモリがないという状況が発生する可能性があります。
つまり、たとえば、新しいsshセッションを開きます。シェルプロセスを開始するには、メモリを割り当てる必要があります。 プロセスは記憶をたどり、コアは彼に「待ってください、今、私は何かを見つけます」と伝えます。 彼はそれを見つけましたが、このページをSSHDに渡す前に、Javaはページフォールトで「ハング」し、空きページが表示されるとすぐに、このメモリをすぐに取得します他のプロセス。 実際には、この状況は、たとえば、監視システムが、sshを介してアクセスできないと、このサーバーが「ライブ」ではないと単純に判断するという事実につながりました。 しかし、これはもちろん極端なケースです。
仮想サイズと常駐サイズに加えて、Linuxプロセスには
コミット済み サイズもあります。これは、プロセスが実際に使用するメモリ、つまりアドレス空間です。アクセスする場合、セグメンテーション違反は発生しません。 。
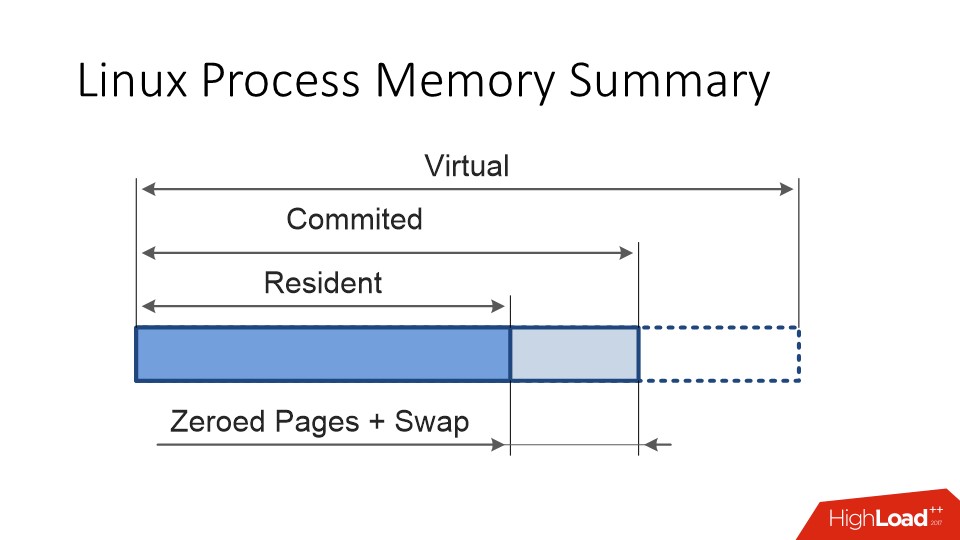
理想的な状況では、
コミットメント と レジデントは同じでなければなりません 。 しかし、最初に、ページは「スワップ」できます。
第二に、Linuxのメモリは常に遅延的に割り当てられます。
- あなたは彼に言います:「お願い、10 GB。」 彼は言う:「それをしてください。」
- 別のプロセス:「10 GBも教えてください」-「お願いします。」
- 3番目のプロセス:「10 GBも提供してください」-「お試しください」。
その後、物理メモリは16個しかないことがわかり、彼はそれをすべての10人に配布しました。そして、「最初にスリッパを取った人、ラッキーではない人は、OMKillerが来るでしょう」と始まります。 これらは、Linuxメモリ管理の機能です。
JVMに関する重要な事実
まず、
JVMは
swapを本当に嫌います。 何らかの理由でJavaアプリケーションの速度が低下していると不平を言う場合、最初に行うことは、サーバーにスワップがあるかどうかを確認することです。 Javaがスワッピングに非常に耐えられない要因は2つあるためです。
- Javaのガベージコレクションは常にページを介して実行され、常駐ページを「ミス」すると、ページがディスクからメモリに、またはその逆に転送されます。
- JVMで少なくとも1つのスレッドがメモリ内にないページに「ステップイン」すると、このJVMのすべてのスレッドがフリーズする可能性があります。
JVMがあらゆる種類のブラックマジックに使用する
セーフポイントメカニズムがあります。たとえば、オンザフライでのコードの再コンパイル、ガベージコレクションなどです。 1つのスレッドがページフォールトにヒットして待機する場合、JVMはメモリページの「到着」を待機しているスレッドから確認を受け取らないため、通常はセーフポイント状態に入ることができません。 そして、他のすべてのフローはすでに停止しており、待機しています。 誰もが立って、この不幸なストリームを待っています。 したがって、ページングを開始するとすぐに、パフォーマンスの大幅な低下が始まる場合があります。
第二に、
Javaはオペレーティングシステムにメモリを決してあきらめません 。 彼女はあなたが許した範囲で使います。たとえこれらのリソースが今本当に必要ないとしても、彼女はそれらを返さないでしょう。 これを行う方法を技術的に知っているが、これを行うことを期待していないガベージコレクターがいます。
ガベージコレクターにはこのロジックがあります。CPU、またはより多くのメモリ。 あなたが彼に10 GBの使用を許可した場合、彼は合理的にCPUリソースを節約できると仮定し、ガベージを含むこれらの10ギガバイトは待機しますが、CPUはそれを改善しますが、メモリをクリーニングするのではなく、有用なことを行います。
この点で、 JVMのサイズを正しく合理的に設定することが重要です。 また、同じコンテナ内に複数のプロセスがある場合、それらの間にメモリリソースを割り当てるのが合理的です。
そうしないと、このコンテナ内のすべてが影響を受けます。
メモリがなくなったとき
これは、「Javists」と「Linuxoids」によって非常に異なって認識される状況のもう1つです。

Javaでは、これは次のように発生します:オブジェクトを割り当てる新しい演算子があります(スライド上には大きな配列です)、ヒープにこの大きな配列にメモリを割り当てるのに十分なスペースがない場合、メモリ不足エラーが発生します。

Linuxでは、状況は異なります。 私たちが覚えているように、Linuxは実際よりも多くのメモリを簡単に約束することができ、それで作業を開始します(上記の条件付きコード)。 また、JVMとは異なり、cgroupsクォータの超過について話している場合、エラーは発生しませんが、選択したOMKillerのプロセスの異常終了またはコンテナ全体の停止が発生します。
JVMでメモリが不足したとき
それでは、もう少し見てみましょう。 Javaには、いわゆる若いオブジェクトの領域と古いオブジェクトの領域があります。 new演算子を呼び出すと、オブジェクトは若いオブジェクトのスペースに割り当てられます。 若いオブジェクトのスペースのスペースがなくなった場合、若い
コレクションが十分でない場合、若い
ガベージコレクションまたは
完全なガベージコレクションが発生します 。 一番下の行は、まず、十分なメモリがない場合、ガベージコレクションが発生することです。 そして、メモリ不足エラーが発生する前に、少なくとも1つの完全なアセンブリがパスします。 10ギガバイトのヒープ全体で急いでいます。 フルGCは特別なケースであるため、場合によっては、1つのストリームにも含まれます。

同時に、ガベージコレクターはおそらく何かをスクラッチします。 しかし、これが
heapのサイズの5%未満である場合 、これは「人生ではなく、単なる苦痛」であるため、エラーがスローされます。 ただし、エラーに関係なく、コード作成者がそのスレッドが動作することを決定したスレッドでこのメモリ不足エラーが発生した場合、例外をキャッチすることでこの苦痛を拡大できます。
一般に、メモリ不足エラーショットの後、JVMはライブと見なされなくなります。 内部状態はすでに破棄されている可能性があり、このプロセスをすぐに
-XX:OnOutOfMemoryError="kill -9 %p"できるオプション(
-XX:OnOutOfMemoryError="kill -9 %p" )があります。 ニュアンスもあります。 JVMのサイズがボックスの物理メモリのサイズに匹敵する場合、このコマンドを呼び出すときにフォークします。 JVMイメージが複製されます。 したがって、Linuxの観点から見ると、JVMのメモリは割り当てる準備ができている最大メモリ制限をわずかに超える可能性があり、このコマンドは機能しません。 この問題は、たとえば、大きなノードがシェルを介してPythonを起動しようとした場合など、Hadoopサーバーに典型的なものです。 当然、この子プロセスはそれほど多くのメモリを必要とせず、フォークだけですべてのコピーを作成し、その後でのみ不要なメモリを解放します。 常に「後で」発生するわけではありません。
別の状況があるかもしれ
ません。ヒープがまだ最大サイズ (-Xmx未満)で
はない可能性があり
ますが、ガベージコレクションが十分なメモリを収集しなかったため、JVMは
ヒープを
増やす必要があると判断しました。 オペレーティングシステムに行き、「もっとメモリをくれ」とOSが言った:「いいえ」。 確かに、私が言ったように、Linuxはそれを言っていないが、他のシステムはそうしている。 JVMの観点からオペレーティングシステムのメモリを割り当てる際のエラーは、クラッシュ、質問なし、実行なし、ログなし、標準クラッシュダンプのみ、プロセスの即時終了です。
いわゆるダイレクトメモリバッファに関連付けられているメモリ不足の2番目のタイプがあります。 これらは、ヒープ外のメモリを参照するJavaの特別なオブジェクトです。 したがって、彼らはまた、それを割り当て、このメモリのライフサイクルを管理します。つまり、そこにはまだ特定のガーベッジコレクションがあります。 そのようなバッファーが無限に大量のメモリーを占有できないように、JVMがそれ自体に設定するバッファーには制限があります。 修正が必要になる場合があります。もちろん、マジック-XXオプションがあります(例
-XX:MaxDirectMemorySize=16g 。 通常のメモリ不足とは異なり、このメモリ不足は特定の場所で発生し、別のタイプのエラーと区別できるため、回復可能です。
Javaでメモリを割り当てます
既に述べたように、すべての
ガベージコレクタヒューリスティックはこれに基づいて構築されているため、最初はJVMで使用できるメモリ量を知ることが重要です。
「グラム単位」で割り当てるメモリ量は難しい質問ですが、主なポイントは次のとおりです。
- メモリ内に永続的に必要な有用なオブジェクトの数を理解する必要があります( ライブ セット )。 これは経験的に最も正確に測定されます。つまり、必要です。
- テストを行います。
- ヒープダンプを行います。
- ヒープの構成要素と、リクエスト数またはデータ量の増加に伴ってヒープがどのように成長するかを確認します。
- 若い世代は 、デフォルトでヒープの割合として取得されるか、動的に設定されます。 たとえば、 G1コレクターチップは、彼自身が若いスペースに適したサイズを選択する方法を知っているという事実に基づいています。 残りのガベージコレクターについては、経験的な考慮事項に基づいて、それを手に入れる方が適切です。
- ガベージコレクターはリザーブを必要とします。これは、ガベージコレクターがメモリー内のどこかにある必要があるためです。 ごみ箱の下にあるメモリが多いほど、1 GBの空きメモリに費やされるCPUが少なくなります。 このバランスを「ゼロに戻す」ことはできません。 リザーブのサイズは、アプリケーションの機能と使用されるガベージコレクターによって異なります。原則として、これは30〜50%です。
- 合計、合計ヒープサイズ(-Xmx)は以下で構成されます。
ヒープに加えて、直接バッファ、ある種のJVMリザーブもあり、これも経験的に決定する必要があります。
したがって、プロセス全体のフットプリントは常に-Xmxを超えますが、これは単なる割合ではなく、スレッド数などのさまざまな要因の組み合わせです。
Linuxのメモリ割り当て
さらに、Linuxには
ulimitのようなものがあります-これは奇妙なデザインで、私の意見ではjavistaです。 プロセスには、オペレーティングシステムによって設定されるクォータのセットがあります。 開いているファイルの数には論理的な制限があり、その他にもいくつかの制限があります。

ulimitsがうまく機能しないのは、リソース管理のためです。コンテナのリソースを制限するために、別のツールが使用されます。 Ulimitsの最大メモリサイズはLinuxでは機能しませんが、
最大仮想メモリサイズもあります。 先ほど言ったように、仮想メモリはリソースではないため、これは非常に興味深いことです。 基本的に、100 TBのアドレススペースを予約するという事実から、オペレーティングシステムはコールドでもホットでもありません。 しかし、OSはおそらく、プロセスに適切なulimitを取得するまでこれを許可しません。
デフォルト値は物理メモリのサイズと見なされることが多いため、デフォルトでは、特に
JVMのサイズが物理メモリに匹敵する場合は特に、この制限により
JVMが起動しなくなります。 たとえば、サーバーに500 GBある場合、400 GBのJVMを起動しようとすると、いくつかの奇妙なエラーが発生してクラッシュします。 それから、JVMは開始時にこれらすべてのアドレススペースを自分自身に割り当て、ある時点でOSが「いいえ、あなたはたくさんのアドレススペースを剃ります。ごめんなさい」と言います。 そして、私が言ったように、この場合、JVMは「死ぬ」だけです。 したがって、これらのパラメーターを構成することを忘れないでください。
サーバー上のJVMに20 GBが割り当てられている場合、仮想アドレス空間のサイズを20 GBに設定する必要があると何らかの理由で判断する臨床状況もあります。 JVMが予約するメモリの一部のセクションは使用されないため、これは問題です。多くのセクションがあります。 したがって、このプロセスのメモリリソースは、思っているよりもはるかに限られています。
したがって、私はLinuxoidsに訴えます、これをしないでください、あなたのやり手に同情してください。
Dockerについて一言
つまり、Docker自体ではなく、コンテナ内のリソース管理に関するものです。 Dockerでは、コンテナのリソース管理は
cgroupsメカニズムを通じて機能します。 これはカーネルメカニズムであり、プロセスツリーがCPUやメモリなどのあらゆる種類のリソースを制限できるようにします。 メモリを含めて、コンテナ全体が占める常駐メモリのサイズ、スワップ数、ページ数などを制限できます。これらの制限は、ulimitとは異なり、コンテナ全体に対する通常の制限です。 プロセスが何らかの子プロセスを分岐する場合、それらは同じリソース制限グループに分類されます。
重要なこと:
- DockerコンテナでJavaを実行する場合、ホスト上の物理メモリの量を調べ、コンテナではなくホスト上の実際の物理メモリの量に基づいて、デフォルトの制限を考慮します。 彼女はあまり与えられていないので、彼女は非常に速く死にます。 したがって、-Xmxは必須です。これがないと、起動しません。
- 常にコンテナの下で、 JVMの 下よりも少し多くのメモリを与える必要があります 。 2 GBのコンテナーを作成し、
-Xmx2048mパラメーターを使用してJVMを起動するとします。メモリーが遅延的に割り当てられるため、何らかの-Xmx2048m動作し-Xmx2048mます。 しかし、少しずつ、これらのすべてのページが何らかの形で使用されるようになり、最初にコンテナーがローカルスワップに移動し始め、それが終了するだけです。 そして、彼は最高の伝統で死ぬ- ただ消えます。
開始したばかりの場合でも、リソースは本当に遅延して割り当てられるため、何も意味がありません。
Javaのスレッド
Javaのスレッドについて
は、オペレーティングシステムの通常のスレッドであることを知っておくことが重要
です 。 最初のJVMでは、いわゆるグリーンスレッドが実装されました。実際、グリーンスレッドは、実際にはJavaスレッドのスタックが何らかの形で生き続け、オペレーティングシステムの1つのスレッドが1つのJavaスレッドを実行し、次に別のスレッドを実行しました。 これはすべて、オペレーティングシステムに通常のマルチスレッドが登場するまで開発されました。 その後、コードはネイティブスレッドでより適切に動作するため、誰もが「グリーン」スレッドを悪夢として忘れていました。
つまり、5000フレームのスタックトレースは、実際にはオペレーティングシステムが割り当てたスタックスペースにあります。 Javaからネイティブコードを呼び出す場合、このコードはJavaコードと同じスタックを使用します。 これは、Linuxで利用可能な診断ツールを使用して、Javaスレッドでも動作できることを意味します。
Javaスレッドを見つける方法

JVMに
psコマンドを使用すると、すべてのスレッドに同じ名前が付けられるため、このようなわかりにくい図が表示されます。 しかし実際には、そこに順番に行きます:
- ガベージコレクタースレッド。
- いわゆる操作スレッドJVM。
- アプリケーションスレッド
しかし、それはランダムです。

ほんと?
jstackコマンドを使用してJVMからスレッドダンプを削除すると、16進数の
「TID」が表示されます 。
これは実際のLinuxスレッドの識別子です 。 つまり、どのJavaスレッドがオペレーティングシステムのどのスレッドに対応するかを理解し、psを解読できます。
唯一のことは、これを行うperlスクリプトをどのように記述するかが既に
わかっている場合、ループ内で
jstackを呼び出さないでください。逆の方が良いです。 jstackを呼び出すたびに、すべてのJVMスレッドがグローバルに一時停止するためです。 通常の状況では、これは0.5ミリ秒未満の高速ですが、これを1秒間に20回実行すると、すでにパフォーマンスに大きな影響を与える可能性があります。
また、独自の診断インターフェースを備えたJVM自体からこの情報をプルすることもできます。 特に、
私のツールを使用し
て 、そこからこの情報を取得し、
JVMのトップ
ストリームを単純に出力できます。
CPUの使用に加えて
、彼はJavaヒープスレッドのメモリ割り当ての強度を出力する方法も知っています。
総流量

Javaスレッドは、通常のオペレーティングシステムスレッドです。 JVMの最新バージョンでは、
PreserveFramePointerキーは、perfなどのツールがJavaスレッドスタックを正しく解析できるようにするJITコンパイラオプションです。
GitHubには、コンパイルされたJavaコードのシンボルをその場でエクスポートし、同じパフォーマンスを使用して、完全に読み取り可能なコールスタックを取得できる
プロジェクトもあります。
そして、ガベージコレクタースレッドがまだあることを少し思い出してください。
2つのCPUを割り当てたコンテナがある場合、ガベージコレクタの並列スレッドの数も2にする必要があります。デフォルトではより多くのスレッドがあり、互いに干渉するだけです。
一方、ガベージコレクターの実行中は、他のすべてのスレッドは何もしません。 したがって、Javaに割り当てるコンテナリソースの100%をガベージコレクタに割り当てることができます。
IOとネットワーキング
Linuxネットワークスタックのチューニングが必要です 。 たとえば、Nginxを使用するフロントエンドサーバーに関係する人は、これを非常によく覚えていますが、アプリケーションサーバーとバックエンドサーバーで同じことを行うといいでしょう。 そして、システムが地理的に分散され、大西洋を横断するデータ転送が開始されるまで、すべてが正常に機能します。 おっと、結局のところ、バッファの制限を増やす必要がありました。

UDP通信を使用する場合は、オペレーティングシステムレベルで個別の構成も必要です。 ソケットのAPIを介してコード自体で設定する必要があるオプションがありますが、オペレーティングシステムの制限レベルで有効にする必要があります。 そうでなければ、単に機能しません。
2番目の興味深い点は、
JVMでリソースを操作する機能に関連しています。
リソースには制限があります-プロセスでソケットが取得するファイル数などの制限。 この制限を超えた場合、次のことはできません。
- 接続を開きます。
- ファイルを開く;
- 接続などを受け入れる
Javaでは、これらのオブジェクトすべてに、それらを明示的に閉じて、それに応じてLinux記述子を解放するためのメソッドがあります。

しかし、怠け者のジャビストがこれを行わなかった場合、ガベージコレクターが来て、彼のためにすべてを閉じます。 そして、このガベージコレクターが予定どおりになった場合はすべてうまくいきますが、彼が適切だと判断したときに彼が来ます。 ソケット全体が開いたソケットでいっぱいになっている場合、ヒープの観点からはペニーです。このソケットのメタデータとオペレーティングシステムからの記述子番号しかないためです。 したがって、Javaコードが参照するような外部リソースの組み合わせがある場合、ガベージコレクターはこの点で適切に動作しないことがあります。
接続とファイルは常に手作業でカバーする必要があります。
とにかく、ソケットでエラーが発生した場合でも、例外をキャッチした後、ソケットを閉じる必要があります。 オペレーティングシステムの観点から、エラーコードが返され、Javaで例外を受け取ったという事実は、ソケットが閉じていることを意味しないためです。 オペレーティングシステムの観点からは、
引き続きオープンであると
見なされ 、オペレーティングシステムは、次の呼び出しをチェックするときにエラーコードを再度返す準備が整います。 したがって、何かを誤って設定し、ソケットが適切に閉じない場合、しばらくするとファイルの制限が終了し、アプリケーションは非常に悪く感じます。
JVMには、明示的に解放できないリソースがいくつかあります。
- メモリマップファイル。
- NIOダイレクトバッファー。
したがって、慎重に作業する必要があります。破棄するのではなく、再利用することをお勧めします。 診断の観点から、このすべての情報を引き出すことができるヒープダンプがあります。
そして最後に、最後の別れの言葉。

正しいJVMサイズを設定します。 JVM自体は、必要なメモリ量を知りません。
ツールの使い方を学びましょう。LinuxにはJavaとうまく機能するツールがあり、JDKにはコマンドラインから多くの情報を取得できるツールがあります。 JavaにはJMX(Java Management Extensions)診断インターフェイスがありますが、それを使用するには、別のJavaプロセスが必要です。これは必ずしも便利ではありません。
特に、ツールの組み合わせを忘れないでください。 たとえば、LinuxコアダンプJVMがある場合、JDKツールを使用してJavaのヒープダンプを抽出し、ライブプロセスから直接このヒープダンプを行う代わりに、通常のJavaアナライザーでそれを確認できます。
最後に、さまざまなトピックへのリンクがいくつかあります。
Javaメモリのチューニングと診断:
Linux Transparent Huge Pagesの読み取り:
プロファイリングとパフォーマンス監視:
連絡先の詳細:
まだ質問がある場合は、適切な
部分にスキップできます
レポート、誰かが既にこれを指定している可能性があります。
あとがき
RIT ++は既に5月28日と29日で、スケジュールはこちらです。これはチケットの購入への直接リンクです。
Highload ++ Siberiaにはもう少し時間があり、6月25日と26日に開催されます。 しかし、 プログラムはすでに活発に形成されているため、ニュースレターを購読して、最新情報を入手できます。