Node.jsの登場以来、アプリケーションのデバッグから詳細なパフォーマンス分析まで、いくつかの段階で診断が改善されました。 今回は、コアダンプデバッガ、フレームグラフ、生産エラー、メモリリークなどのツールを使用するための戦略に焦点を当てます。
この資料は、12月のHolyJS 2017モスクワ会議のGrid DynamicsのNikolai Matvienkoによるレポートの転写に基づいています。
診断ツールの進化の現在の段階を理解するには、歴史に目を向けることをお勧めします。 タイムラインで、最も重要なポイントを描きました。
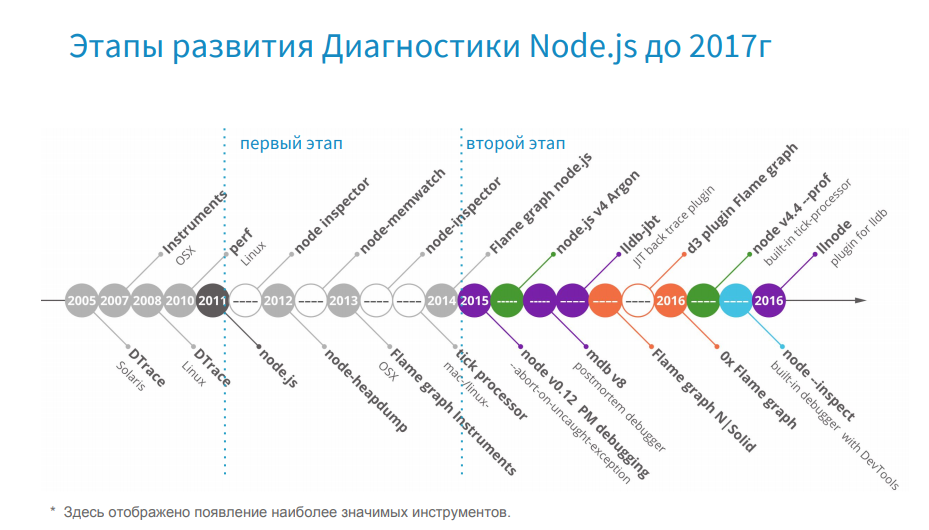
最初に、DTrace、Instruments、perfなどのツールがリリースされました。これらはNode.jsよりもずっと前に登場したシステムプロファイラーであり、現在でも使用されています。 Node.jsの登場により、ノード指向のツールが登場しました。ここでは、ノードインスペクター、node-heapdump、node-memwatchに注目する価値があります。 この期間を灰色でマークし、条件付きで問題時間と呼びます。 コミュニティには分裂があったことを思い出してください。当時、io.jsはNode.jsから分離されており、コミュニティは次に進むべき場所と選択すべきものについて共通の理解を持っていませんでした。 しかし、2015年にio.jsとNode.jsが合併し、Node.js v4 Argonが登場しました。 コミュニティには開発の明確なベクターがあり、実稼働中のNode.jsはAmazon、Netflix、Alibabaなどの大企業を使用し始めました。
そして、本番環境で動作する準備ができている効果的なツールが人気を博しています。
2017年以来、私は条件付きで3番目の段階を区別しています。
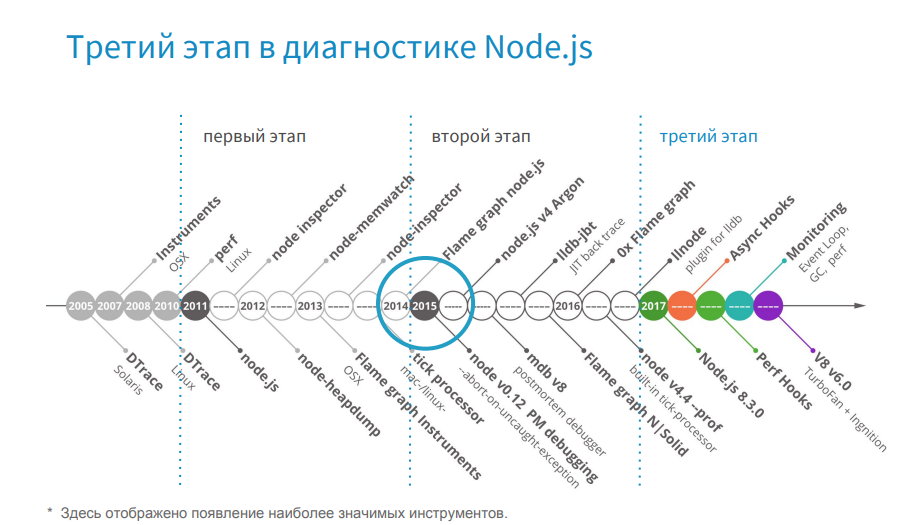
この時点から、Node.jsはすでに定性的に開発されています。 Turbofanへの完全な移行と非同期フックの開発に注目する価値があります。
2015年に、Node.jsバージョン0.12でリリースをリリースし、最初に4番目のバージョンに、その後6番目に徐々に更新しました。 現在、8番目のバージョンへの移行を計画しています。
リリース年には、第一段階のツールを使用しましたが、本番環境での作業には機能しませんでした。 私たちは第2段階のツールを使用した経験が豊富で、現在は第3段階のツールを使用しています。 しかし、Node.jsの新しいバージョンへの移行に伴い、有用なツールのサポートが失われているという事実に直面しています。 実際、私たちは選択に直面しました。 または、新しいバージョンのNode.jsに移行します。これは、以前のバージョンよりも最適化および高速化されていますが、ツールがなく、診断できません。 または、古いバージョンのNode.jsにとどまり、動作が遅くなりますが、そのためのツールがあり、その弱点を知っています。 または、新しいツールが表示されるときに3番目のオプションがあり、それらは、たとえば、Node v4以降をサポートし、以前のツールはサポートしません。
私たちのアプリケーションは、Node.jsアプリケーション(Web UIバックエンドとNode.jsマイクロサービス)がエンタープライズアーキテクチャの中心的な場所を占める大規模なeコマースプロジェクトです。
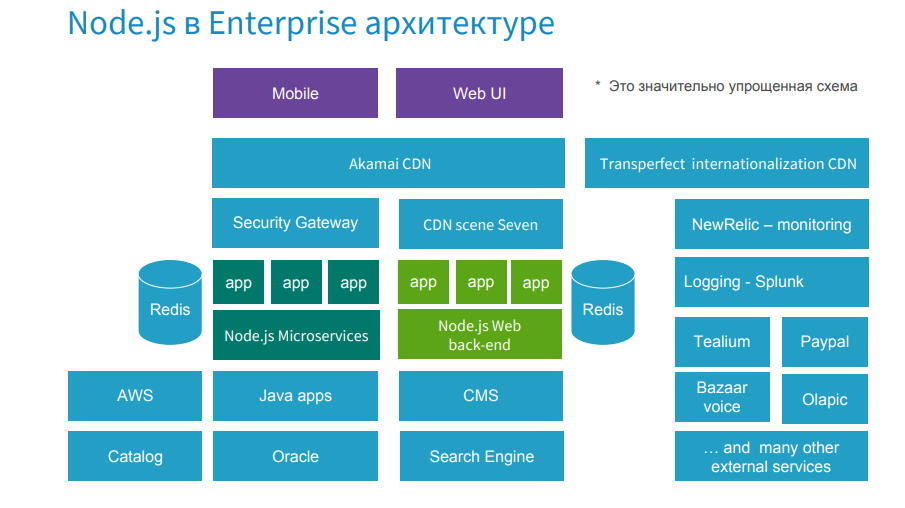
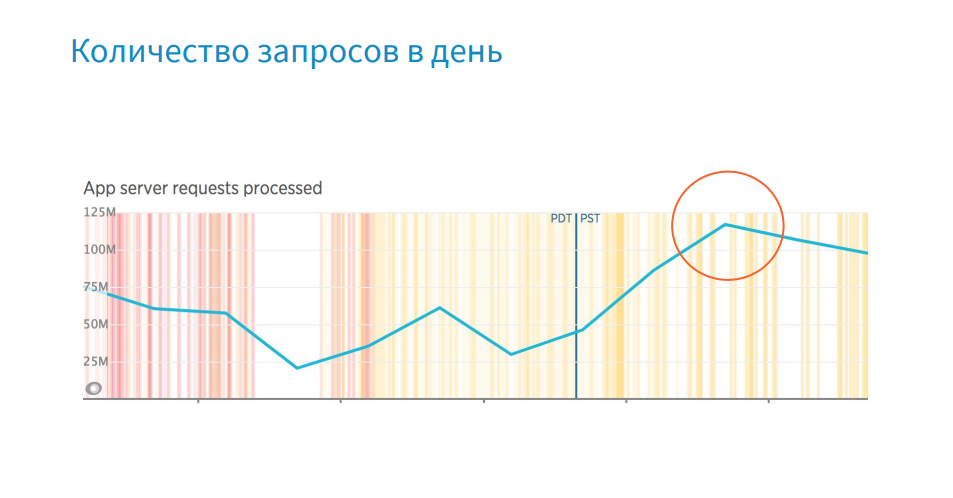
この場所の問題は、あらゆる方向から生じる可能性があります。 ブラックフライデーなどのワークロードが増加している日で、企業が数日で年間利益の60%を稼ぐ場合、高い帯域幅を維持することが特に重要です。 何らかの不具合が発生した場合は、Node.jsの私を含め、システムのすべてのリーダーが参加するローカルコンサルティングが開催されます。 問題がNode.jsの側にある場合、会社は1分あたり数千ドルを失っているため、戦略をすばやく選択し、そのツールを選択して問題を修正する必要があります。
以下に、エラー、メモリリーク、パフォーマンスの低下が発生した場合に本番環境でどのように動作するかを具体的な例を示して説明します。
本番環境でのアプリケーションのデバッグ
本番環境でデバッグするためのメッセージがいくつかあります。

簡単な例を考えてみましょう。製品を予約するサービスです。 コントローラーは、製品のコレクションをREST APIに送信し、データを返し、コントローラーでエラーが発生するサービスを使用します。
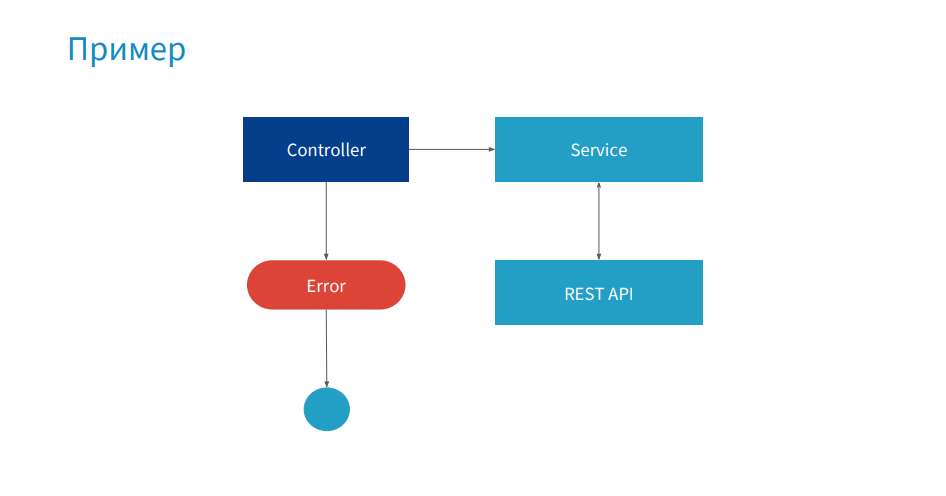

写真にProductControllerのリストが表示されます。 予約方式では、Cookieからプロファイルを取得します。また、ボーナスポイント、ID、およびその他の有用な情報が保存されている報酬アカウントも、Cookieから取得します。 そして、このcookieが欠落しています-未定義。 idが報酬から取得される場合、エラーが発生します。 ローカルでは、ブレークポイント(赤い点)を設定し、すべてのオブジェクトのステータスを取得し、コードがクラッシュする理由を見つけます。

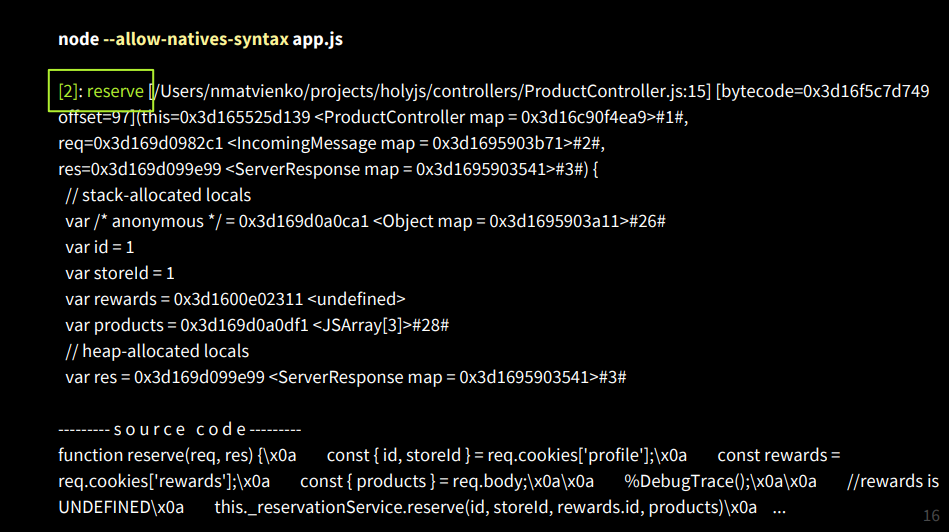
内部でどのように機能するかを示しますので、スタックトレースとは何かを理解できます。 %DebugTrace()コマンド、ネイティブV8コマンドを記述し、Node.jsを--allow-natives-syntaxオプションで実行する、つまりV8でネイティブ構文を有効にすると、スタックトレースで大きなメッセージが表示されます。
2番目のフレームの最上部には、コントローラーメソッドの前に予約関数があり、ProductControllerコンテキストへのリンクが表示されます-これ、要求および応答パラメーター、ローカル変数を取得し、その一部はスタックに格納され、もう1つはヒープ(管理ヒープ) ) また、ソースコードもあります。オブジェクトの状態を取得するためにデバッグする場合は、運用環境でこのようなものを用意しておくといいでしょう。
このようなサポートは、2015年にバージョン0.12から実装されました。 Nodeを--abort-on-uncaught-exceptionフラグを指定して実行すると、コアダンプが作成されます。これは、スタックトレースとヒープダンプを含むプロセス全体のメモリスナップショットです。
忘れてしまった方のために、思い出させてください。メモリは条件付きで呼び出しスタックとヒープで構成されています。
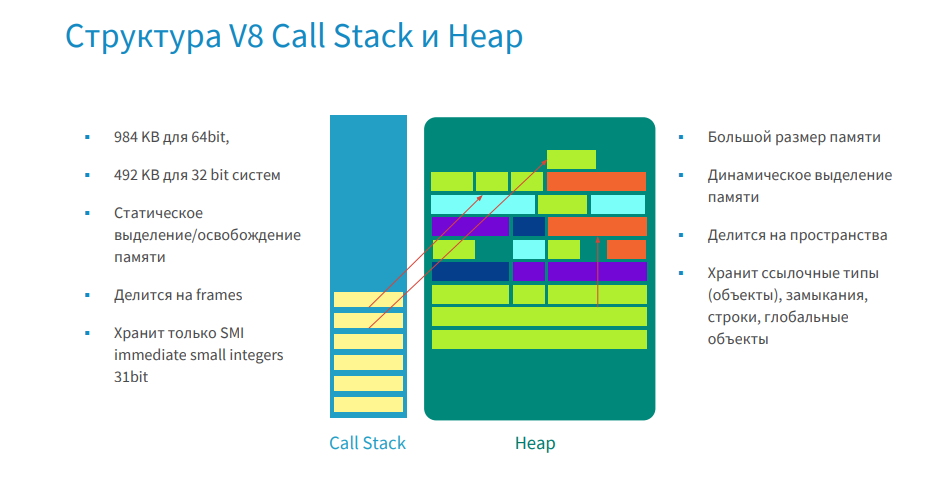
コールスタックでは、黄色のレンガがフレームです。 これらには関数が含まれ、関数には入力パラメーター、ローカル変数、および戻りアドレスが含まれます。 そして、小整数(SMI)を除くすべてのオブジェクトは、アドレスがあるマネージヒープに格納されます。
コアダンプの構成を把握しました。次に、作成のプロセスに進みましょう。
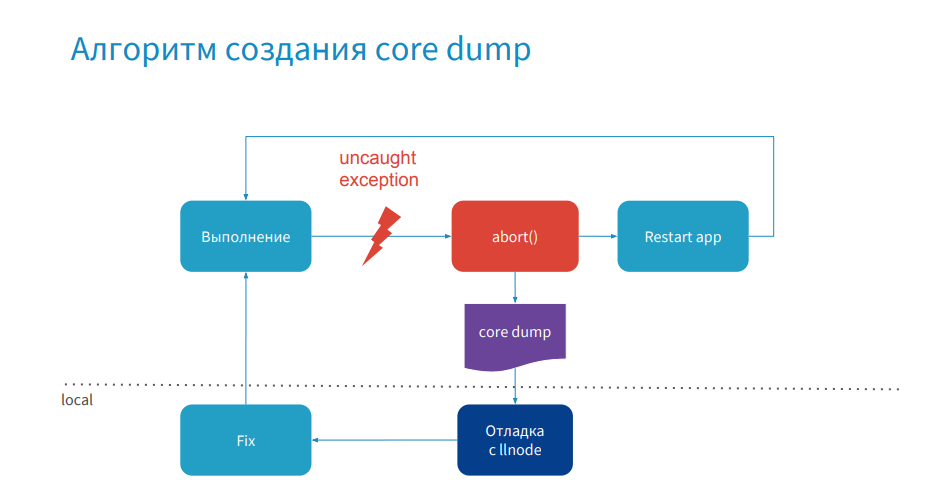
ここではすべてが簡単です。アプリケーションプロセスが実行され、エラーが発生し、プロセスがクラッシュし、コアダンプが作成されてから、アプリケーションが再起動します。 次に、実稼働環境にリモート接続するか、このコアダンプをローカルコンピューターにプルし、デバッガーでデバッグし、修正プログラムを作成して公開します。 このプロセスがどのように見えるかを理解したので、使用できるデバッガーを見つける必要があります。
それらはすべてNode.jsの前に現れました。 JS Stack Traceを読み取るために、さまざまな時点でいくつかのプラグインが作成されました。 それらのほとんどはすでに古くなっており、Node.jsの最新バージョンではサポートされていません。 ほとんどすべてを試しましたが、このレポートではllnodeを強調します。 クロスプラットフォーム(Windowsを除く)で、4番目以降のNode.jsの最新バージョンで動作します。 このデバッガを使用して生産エラーをデバッグする方法を示します。
上記の例-製品予約を検討してください。

環境を設定し、コアダンプを作成する機能を設定し、フラグ--abort-on-uncaught-exceptionを指定してNodeアプリケーションを実行します。 次に、プロセスpidを取得し、Cookieの報酬を持たないユーザーにリクエストを行い、reserveメソッドのProductControllerにエラーが表示されたことを示すメッセージを取得します。

次に、コアダンプが作成されたというメッセージ-メモリのキャストを取得します。 コアダンプまたはそれにアクセスした後、可用性を確認します-重さは1.3 GBです。 たくさん。
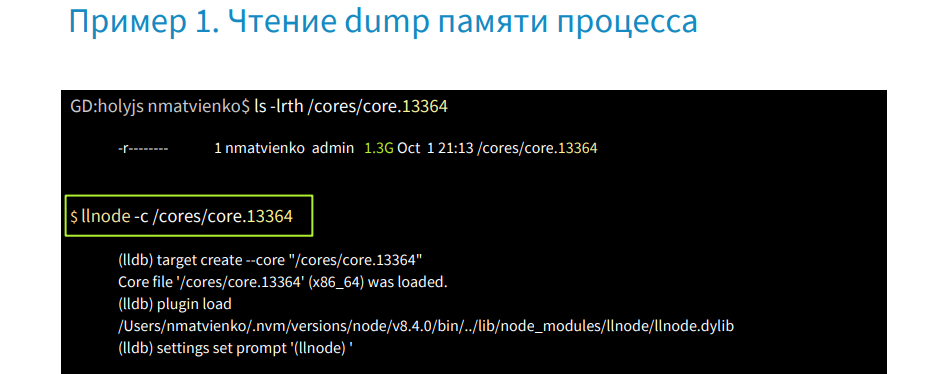
llnodeコマンドを使用してデバッガーでこのコアダンプを実行すると、btコマンドを使用してスタックトレースを取得できます。
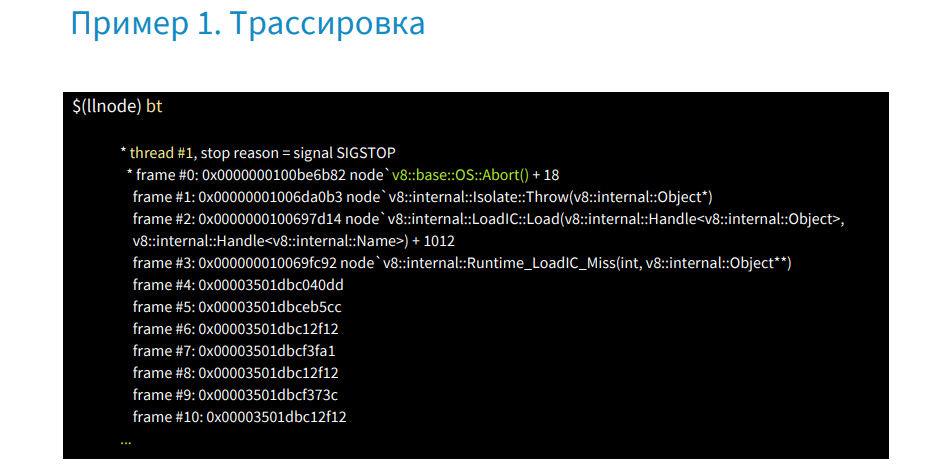
この画像は、フレーム4〜20に情報がないことを示しています(上下に詳細に表示)。

実際のところ、これはJSスタックトレースであり、C ++デバッガーは読み取ることができません。 それを読むには、プラグインを使用するだけです。

V8 btコマンドを実行すると、JS Stack Traceが取得されます。6番目のフレームには予約機能があります。 フレームには、このProductControllerのコンテキストへのリンク、パラメーター:IncomingMessage-Request、ServerResponseが含まれ、メモリ内の関数のアドレスは青で強調表示されています。 このアドレスでは、コアダンプからソースコードを取得できます。
次に、v8 inspect --print-source [address]コマンドを記述し、メモリから関数のソースコードを取得します。

スタックトレースに戻って、リクエストとレスポンスのパラメータがあり、リクエストの内容を確認しましょう。
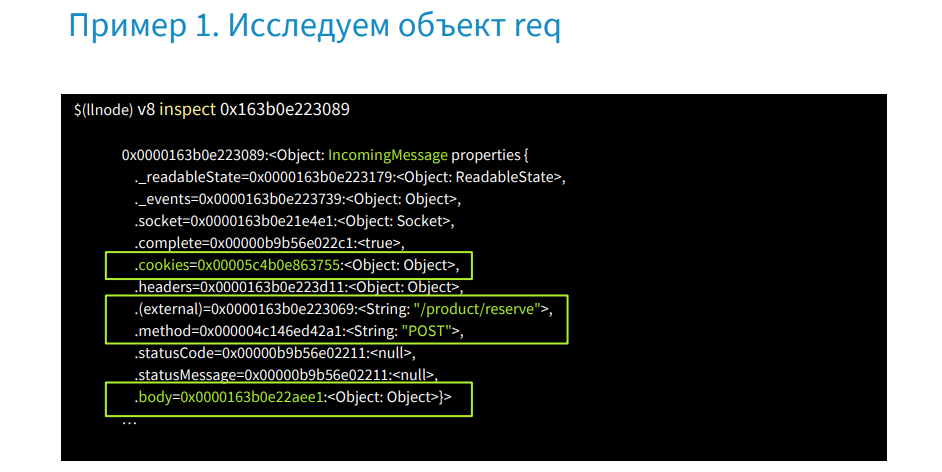
画像では、アドレスを指定したv8 inspectコマンドが表示されています。 実行後、リクエストオブジェクトの状態を受け取ります。 ここでは、プロパティCookie、URL、POSTメソッド、および本文に関心があります。 サーバーに転送された製品を確認します。
コマンドv8 inspect [body address]を書きましょう。

productsプロパティの3つの要素で配列が構成されているオブジェクトを取得します。 そのアドレスを取得して検査し、idから配列を取得します。

ここで問題はありません。 req.cookiesオブジェクトの内容を見てみましょう。

これは、プロファイルと報酬-未定義の2つのプロパティのオブジェクトです。 報酬アカウントを持っていないユーザーを見つけます。
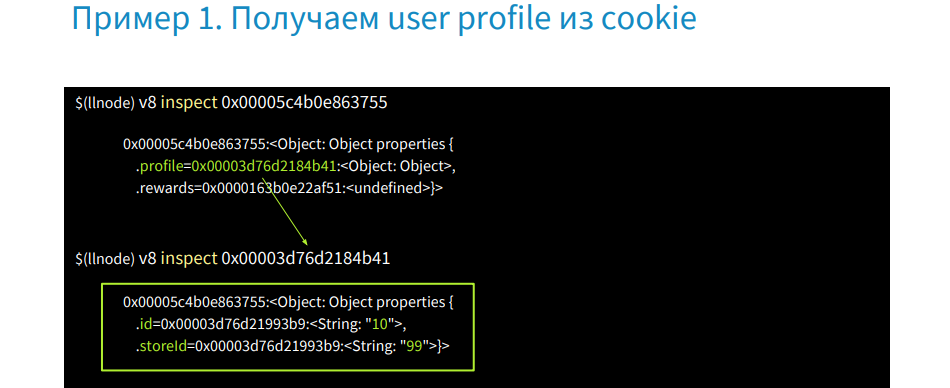
コマンドv8 inspect [address profile]を作成して、そのIDとstoreidを取得しましょう。 したがって、ソースコードを取得せずにユーザーセッションを復元するために、ソースコードを使用せずに本番環境で作業することができました。
ここは非常に便利なケースで、ErrorHandlerミドルウェアを含むフレームワークを使用する場合、スタックトレースからコンテキストthis、request、responseへのリンクがある前の例とは異なり、ErrorHandlerを書き換えない場合は、スタックトレースには、Express自体からの最新の呼び出しが含まれ、何も機能しません。 リンクはありません。
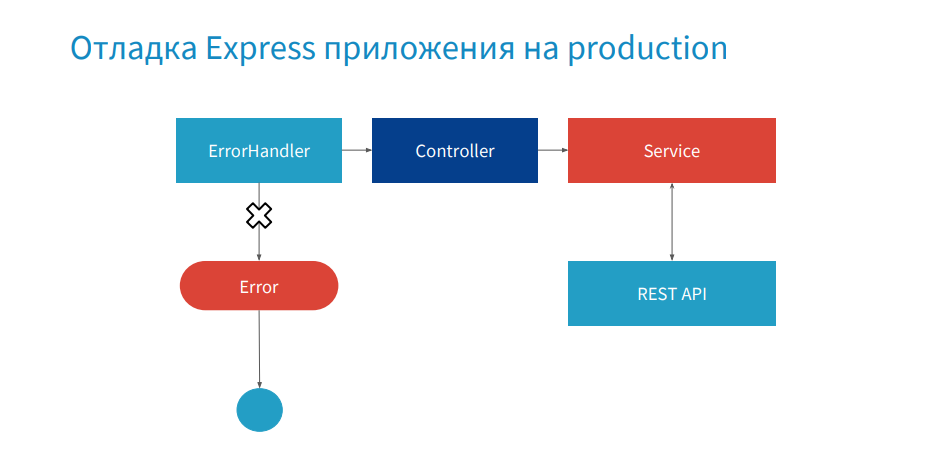
これがどのように起こるか例を示します。

reserveメソッドを使用した同じ例ですが、非同期モードで動作するサービスですでにエラーが発生しています。 それをキャッチするために、unhadledRejectionプロセスのイベントをサブスクライブし、process.abort()を実行してコアダンプを作成します。

以下は、この場合のバックトレースの様子を示しています。
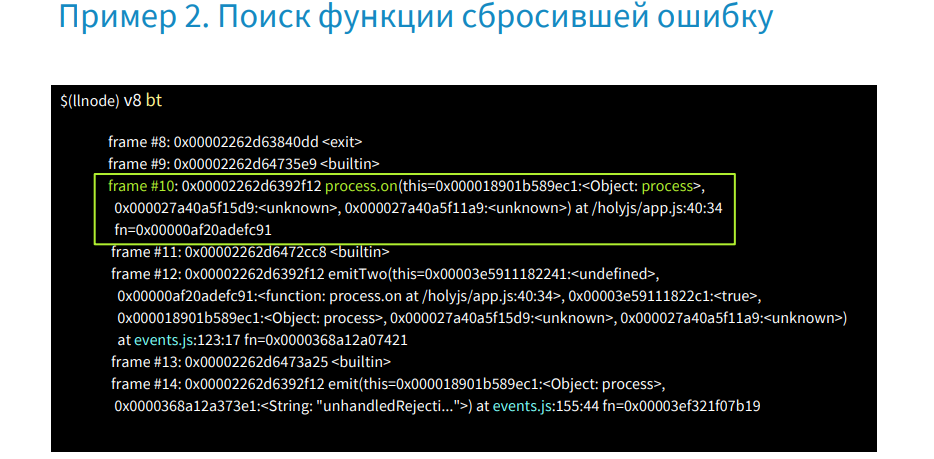
ProductControllerに関する情報、予約に関する情報はありません。 このフレームにはprocess.onの呼び出しがあり、他には何も役に立ちません。 このようなケースは、エラーがキャッチされず、スタックトレースに情報がないときに、本番環境で発生します。 さらに、スタックトレースなしでマネージヒープのみを使用して、すべてのオブジェクトを見つける方法を示します。
タイプIncomingMessageによってオブジェクトのすべてのインスタンスを取得できます。 これは送信されたすべてのリクエストの大きなリストになりますが、プロセスをクラッシュさせたものを見つける必要があります。
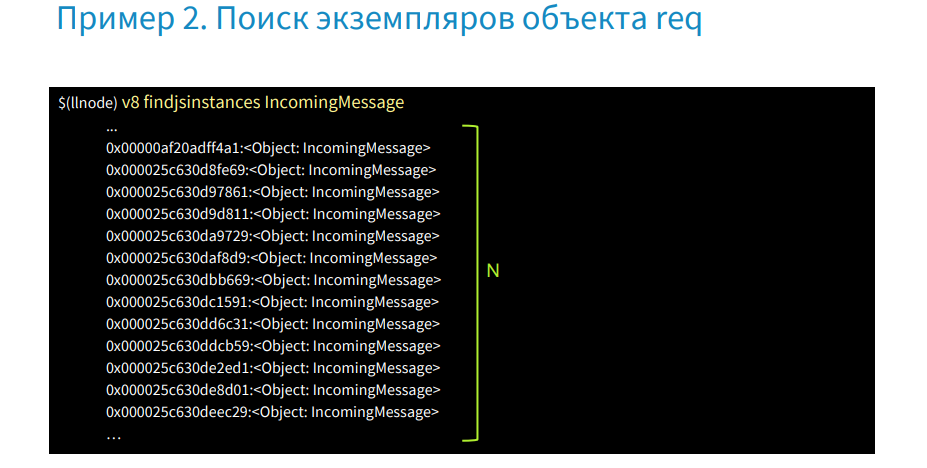
この場合、ログが必要であり、その中にid request'aを取得する必要があります-これはX-Transaction-IDです。

llnodeでは、メモリ内で文字列の値によって、それを参照するリンクを見つけることができます。 コマンドv8 findrefs --string [string value]を作成すると、X-Transaction-IDプロパティを持つオブジェクトが見つかり、この文字列を参照します。 このオブジェクトが何であるかを調べてください。

v8 inspect [address]コマンドを記述した後、ヘッダーオブジェクトを取得します。 次に、このオブジェクトを参照するものを見つけ、IncommingMessageオブジェクトを取得します。 したがって、スタックトレースとアドレスがなくても、ユーザーセッションを復元できました。

ローカル変数を取得する必要がある場合、より複雑な例を調べてみましょう-それらはサービス内にあります。 エラーがどこかに深く落ちており、データがほとんどないと仮定します。 この場合、REST APIが使用されます。 オブジェクトはデータベースから取得され、それらはすべてsomeLocalValueと呼ばれるローカル変数に割り当てられます。 そして、someLocalValueを参照するオブジェクトはありません。 メモリからローカル変数を取得する方法は? ログから取得した場合、たとえばid値でこのオブジェクトを見つけることができますが、プロパティの名前でメモリからオブジェクトを取得することもできます。 v8 findrefs nameコマンドを使用すると、userAccount、preferredStoreプロパティを持つオブジェクトを検索できるため、必要なローカル変数を取得できます。
それでは、実際のケースを取り上げましょう-本番環境でのエラーです。
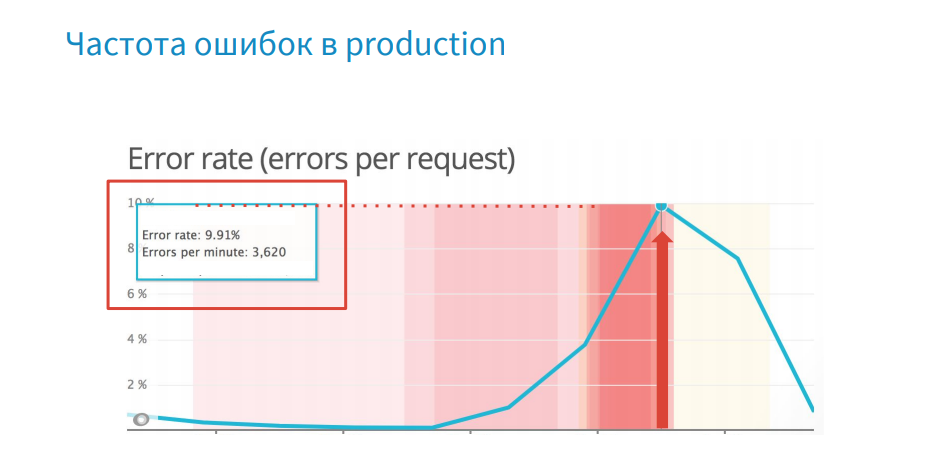
エラーごとに、コアダンプを作成します。 しかし、ここで何が問題なのでしょうか? 多くのエラーがあります-1分あたり3620、コアダンプの重量は1.3 GBで、システムに作成してマージするのにかかる時間は約15〜20秒です。 コアダンプ作成を選択するためのロジックが明らかに不十分です。
たとえば、アプリケーションを実行しているときにエラーが発生した場合や、再現が難しいエラーをキャッチした場合です。 次に、プロセスはErrorHandlerに入ります。ここで、ロジックがあります-このエラーに対してprocess.abortを実行してコアダンプを作成する必要があるのか、それともプログラムの実行を継続するのか。
エラーが一意であり、処理する必要がある場合、node-reportを使用してレポートが生成され、process.abortが呼び出されてコアダンプが作成され、プロセスが再起動されます。 サーバーは再び動作し、トラフィックを処理します。その後、レポート、コアダンプ、ログにアクセスし、デバッガを使用してデバッグし、修正プログラムを作成して公開します。
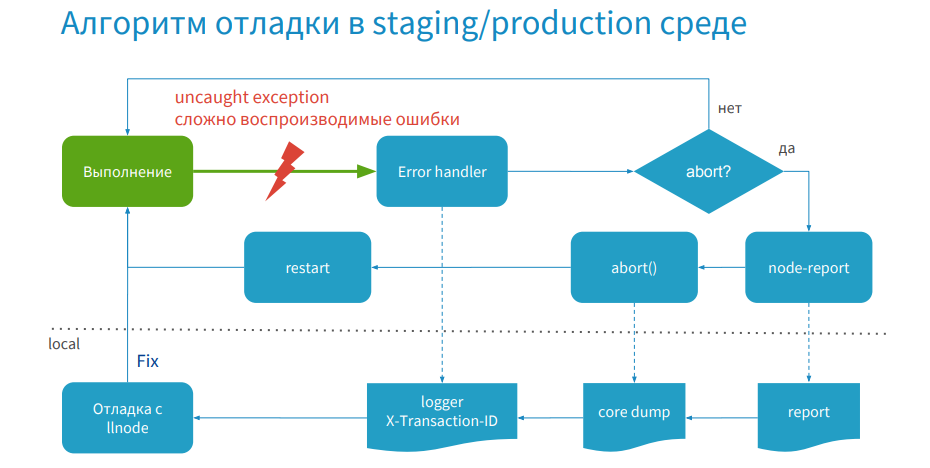
以下の画像は、選択を行うロジックの例を示しています。 私はそれをエラーのレジストリと呼びます。 コアダンプの作成を制限します。
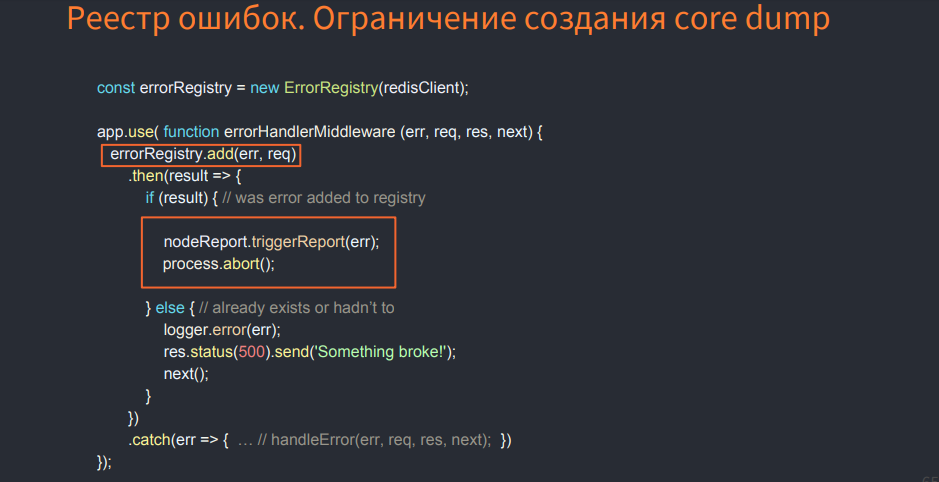
これはIn-Memory Databasesが使用するクラスであり、エラーが見つかった場合は、レジストリに登録されているかどうかを確認します。 そうでない場合は、登録する必要があるかどうかを確認します。 その場合、プロセスをリセットし、コアダンプを作成します。 この場合、繰り返されるエラーのコアダンプは作成しません。 それらを選択します。 これにより、デバッグプロセスが高速化されます。
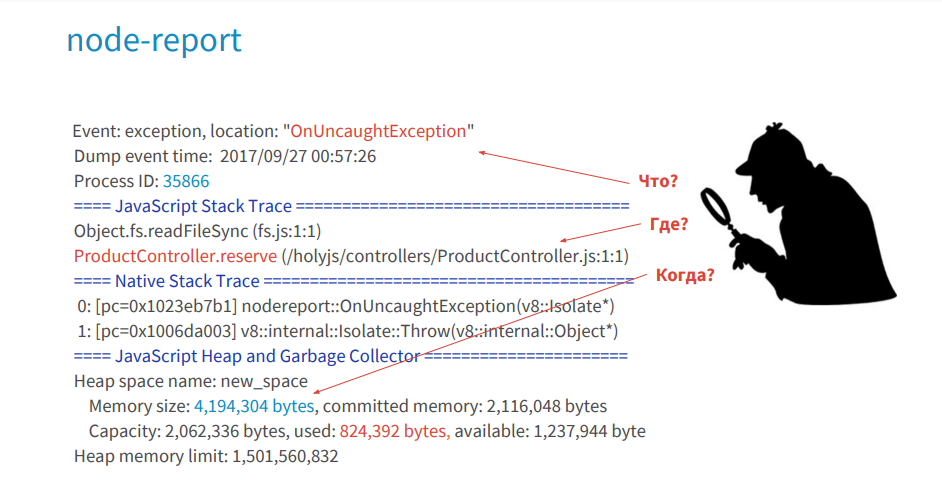
実稼働環境でのデバッグプロセスは、ノードレポートで何が起こったのか、どこで、どのような状況でJSスタックトレースプロセスに対して犯されたのかを示す、ある種の探偵調査だと思います。 ログは、リード、証拠、貴重な情報を提供します。 デバッガーを使用すると、犯罪時、つまりこれらの関数で発生したオブジェクトを見つけることができます。
これが、本番およびデバッグエラーでの作業方法です。
メモリリークを検索する
メモリリークの検出に進みましょう。
メモリリークを検出するには多くの方法があります(上記の画像で説明されているものもあります)。
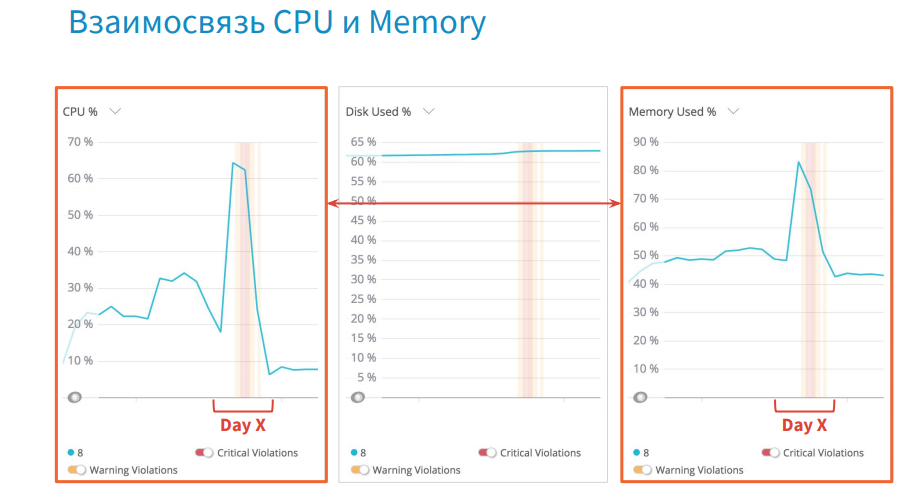
たとえば、プロセッサの負荷とメモリのグラフでは、特定の相関関係を確認できます。 また、メモリリークが発生する状況では、ガベージコレクターが読み込まれるため、より多くのプロセッサ時間がかかります。
リークの例を考えてみましょう。
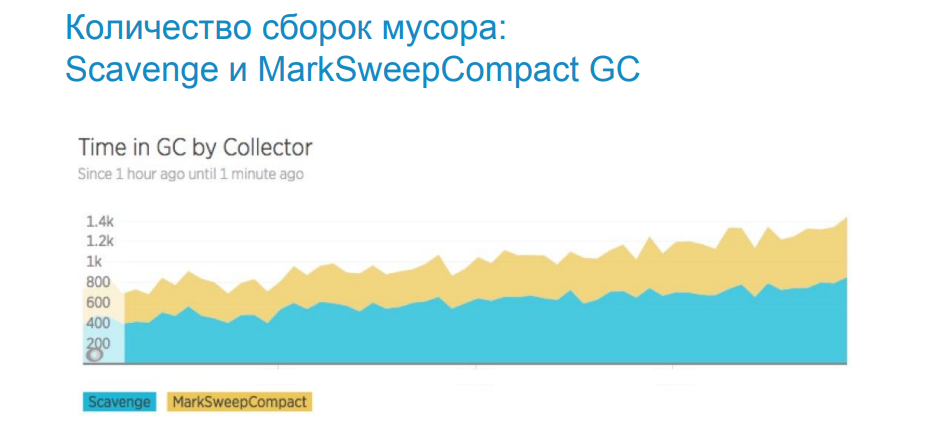
上の画像は、ガベージコレクターのスケジュールを示しています。 Scavenge-若いオブジェクトの空間で動作します。 MarkSweep-古いオブジェクトのスペース。 グラフは、ガベージコレクションの数が増加していることを示しています。つまり、メモリがリークしており、より頻繁にガベージコレクションが必要になっています。 どこで、どのスペースで漏れているかを理解するために、ガベージコレクターのゴミを使用します。

上の画像は、ガベージコレクションの各反復でのステータスを表示するメモリ領域のリストを示しています。 古いスペース、新しいスペースなどがあります。 コアダンプからソースコードを受け取ったとき、コードスペースから取得しました。

経験から、メモリが新しいオブジェクトのスペースにリークした場合、高価なクローン作成、マージなどが原因であると言えます。 古いオブジェクトの大きなスペースにメモリが流れる場合、これらは見逃されたクロージャー、タイマーです。 また、ガベージコレクターが機能しない大きなスペースでメモリリークが発生した場合、これは大きなJSONのシリアル化/逆シリアル化です。
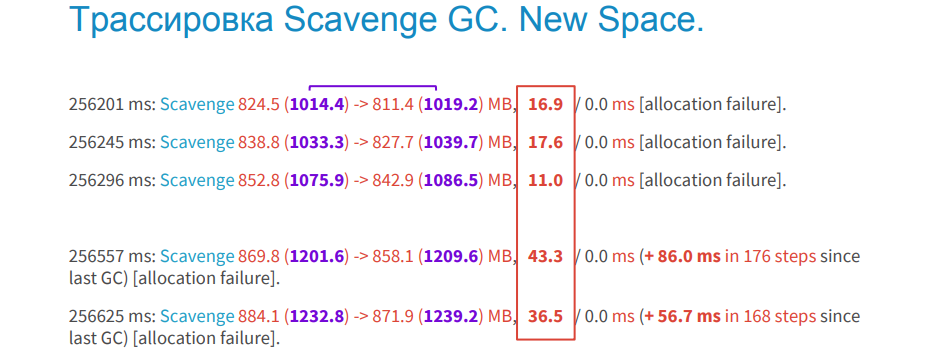
以下の画像は、若いオブジェクトの領域で機能するスカベンジトレースの例を示しています。 メモリリークはありません。
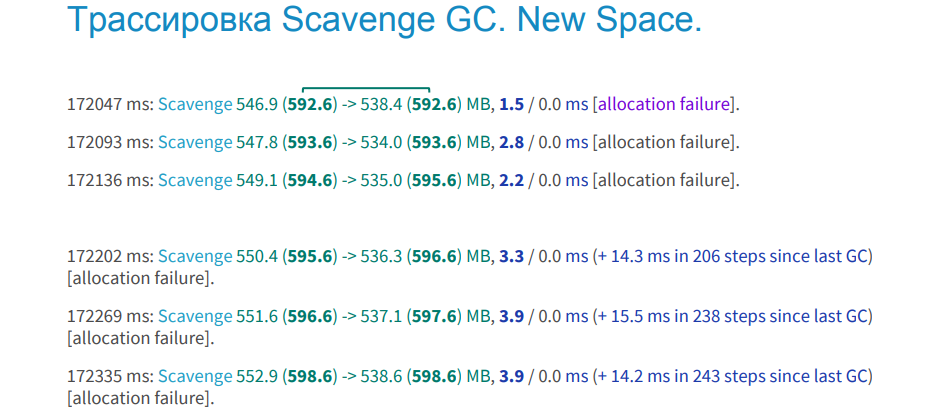
どうやってこれを見つけることができますか? 太字の緑の列が2つあります。 アセンブリの前と後のプロセスに割り当てられたこのメモリ。 値は等しく、これは、ガベージコレクションの後、割り当てられたメモリが増加しなかったことを示唆しています。 青いフォントは、ガベージコレクションに費やされた時間を示します。 ドキュメントには、デフォルトで1ミリ秒かかると記載されています。 私たちのプロジェクトでは、これは約3秒であり、これを標準と考えています。 下の上部の画像には3行が表示されていますが、これもガベージコレクションですが、反復的です。つまり、メモリのすべてがスキャンされて消去されるわけではなく、断片的に表示されます。 また、反復回数も表示されます。
以下の画像は、同じスペースでのメモリリークの例を示しています。 ライラックの列は、占有メモリの量が増加していることを示しています。つまり、ガベージコレクションの後、毎回増加しています。
古いオブジェクトの空間はどうですか?
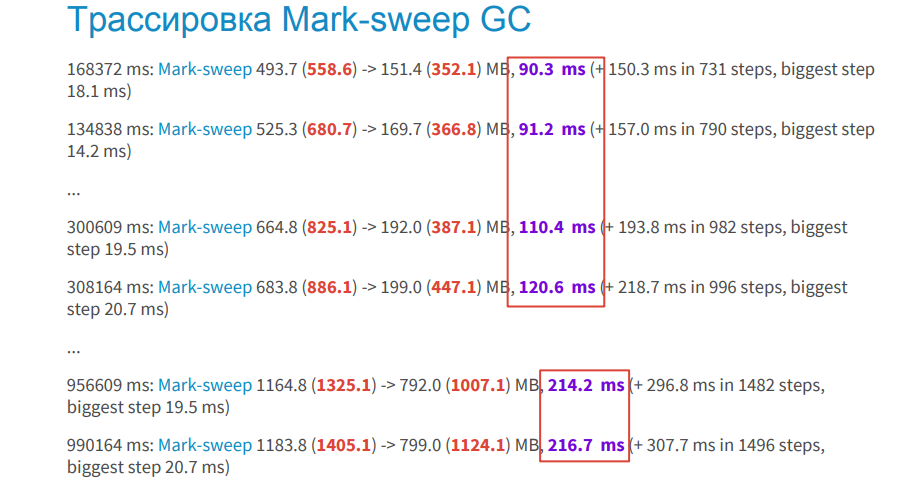
ここでは、プロセスに時間がかかることがわかります:90ms、110msなど。 これはたくさんあります。 さらに、それはまだ反復的であり、バックグラウンドスレッドでも時間がかかります。
内部では、Node.jsにはいくつかのスレッドがあります。 1つはプロファイリング用、複数はガベージコレクション用、そしてアプリケーション自体を実行するためのスレッドです。
メモリリークを検出する方法を理解するには、以下の例を検討してください。

リクエストを処理するミドルウェアは、最初に実行の開始時間を取得し、リクエストが終了すると、実行後の時間を修正します。これは、処理する何らかの関数が呼び出される-someProcessOperationです。 この関数にリクエストを渡します。 閉鎖があります。 要求オブジェクトは、送信後に保持されました。 さらに、他のリンクがまだある可能性があり、多くのオブジェクトをプルします。 この場合、何をすべきですか? 要求オブジェクト全体は必要ありません。 idとurlのみを渡すことができます。 これにより、メモリリークを回避できます。

どうすればわかりますか?
llnodeデバッガーでこれを行う方法を示します(Fatallエラーの場合、メモリ不足のためにアプリケーションがクラッシュした後にNode.jsがコアダンプを作成するとき)。 前のケースでは、例外が落ちてプロセスが終了したときにコアダンプが発生しました。 今回は、もちろん、実行中のアプリケーションでprocess.abort()を呼び出してコアダンプを取得しませんでしたが、インフラストラクチャレベルでプロセスIDを照会し、必要に応じてコアダンプを取得できるgcoreツールを用意しました。 ただし、ここではインフラストラクチャの制約に直面しているため、他のオプションを探す必要がありました。
1か月前、gen-coreというライブラリが公開されました。 このツールを使用すると、プロセスをフォークし、メインプロセスに悪影響を与えることなくプロセスを終了し、コアダンプを取得できます。
以下の画像は、gen-coreの仕組みの例を示しています。
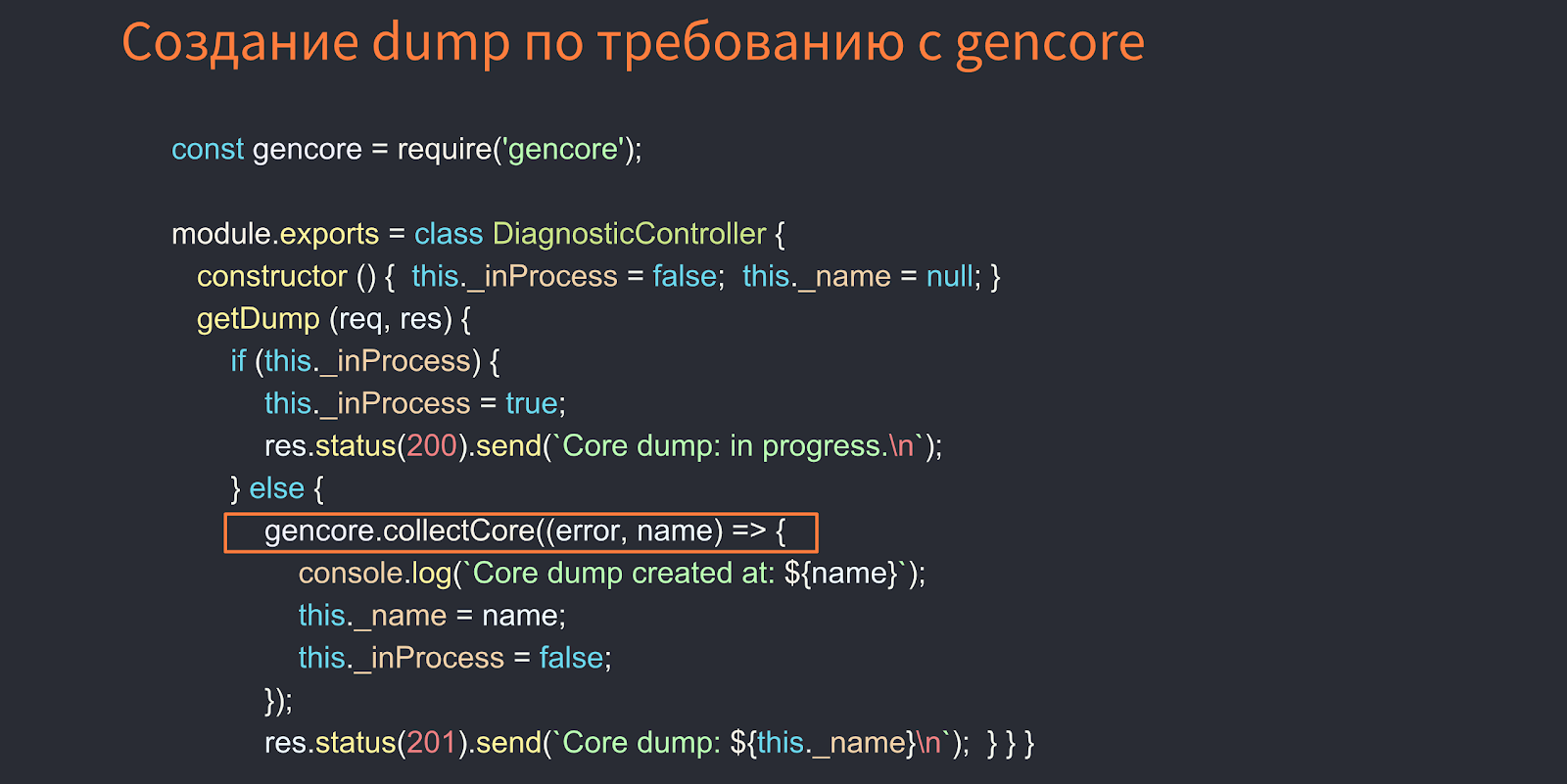
ここで、REST APIによるDiagnosticControllerはコアダンプを実行できます。
llnodeを使用してメモリリークを検索する方法
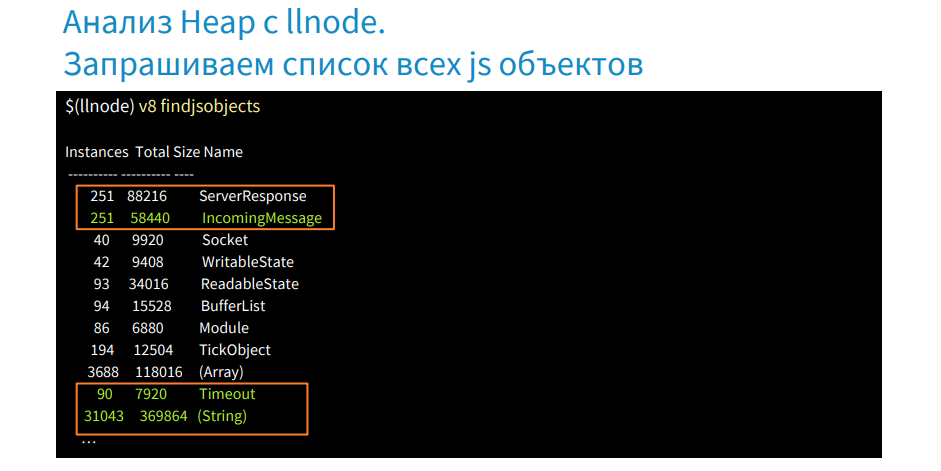
findjsobjectsコマンドがあります。これを使用して、ヒープ全体をスキャンし、タイプごとにグループ化し、各タイプのオブジェクトインスタンスの数、メモリ内のサイズなどのレポートを取得できます。 上の画像は、ServerResponseとIncomingMessageのインスタンスが多数あることを示しています。TimeoutオブジェクトとStringオブジェクトもあります。 文字列自体は非常に大きく、多くのメモリを占有します。 多くの場合、ガベージコレクターが機能しない大きなスペースにあります。
なぜリクエストオブジェクトがたくさんあるのかを見てみましょう。 要求オブジェクトはミドルウェアに保持されていたことを思い出してください。
findjsinstances [type]コマンドがあり、それを使用してリクエストオブジェクトのリストを取得します。
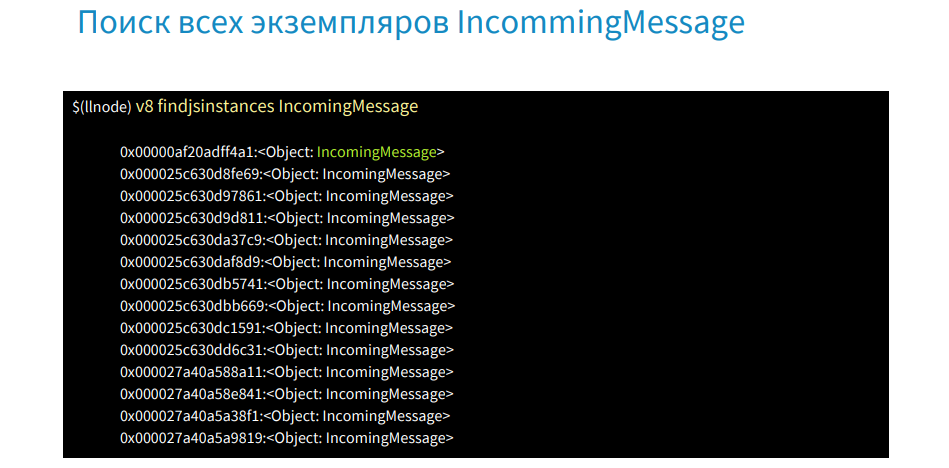
最初のオブジェクトのアドレスを取得し、v8 findrefs -vコマンドを使用して、メモリにリンクがあるオブジェクトを探します。

これらは2つのオブジェクトです。 最初は18要素の配列で、2番目はリクエストオブジェクトです。 この配列が何であるか、そしてそれがリクエストオブジェクトを保持する理由を見つけます。
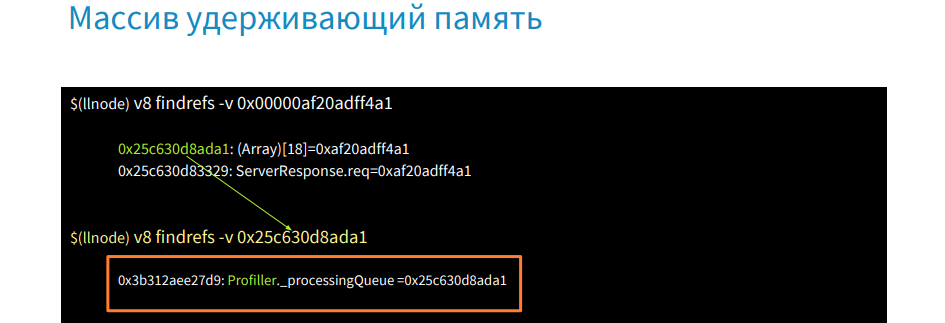
v8 findrefs -v [この配列のアドレス]コマンドを使用すると、この配列がProfiller型のオブジェクトとprocessingQueueプロパティにあることがわかります。 したがって、リクエストオブジェクトがメモリのどこに保持されているかを知ることができました。 次に、ソースコードに移動するか、そこから取得してprocessingQueueが呼び出される場所を確認します。
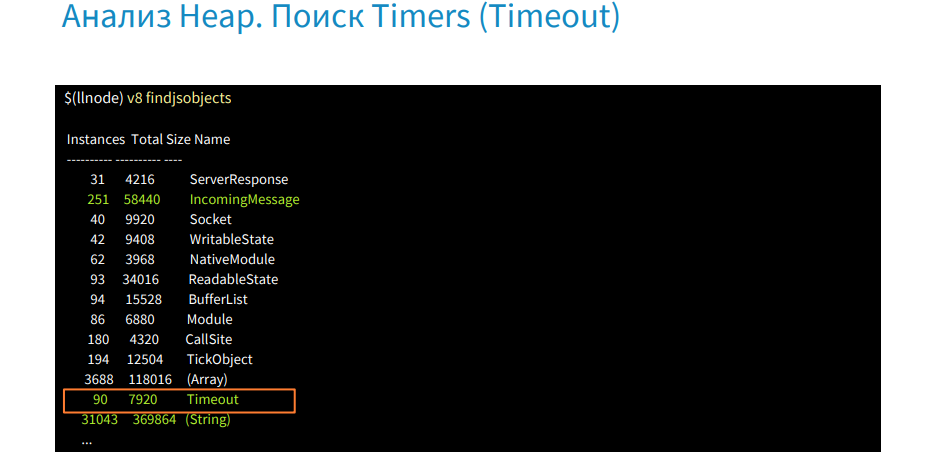
findjsinstancesコマンド[タイプタイムアウト]を使用して、すべてのタイムアウトのリストを取得し、それらが使用されている場所を探します。
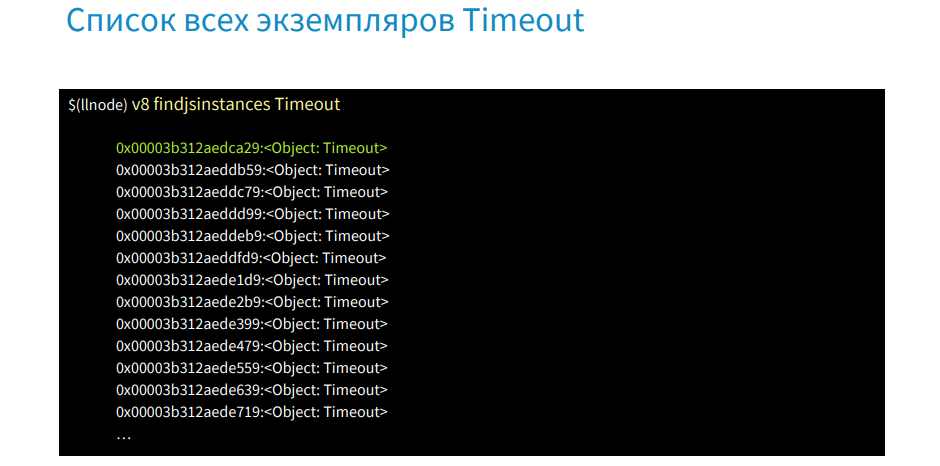
v8 iコマンドを使用すると、最初のタイムアウトが発生します。

onTimeoutプロパティでは、setInterval関数が呼び出され、ファイルの場所を含むアドレスが表示されます。 したがって、忘れられたタイマーがどこにあるのか、なぜ実行されているのかをすぐに見つけました。
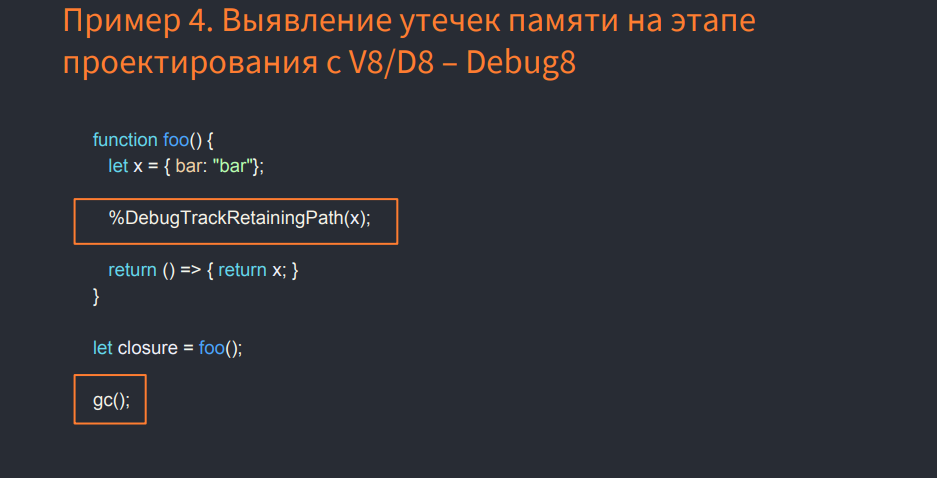
アプリケーションの設計段階でメモリリークを識別する方法
V8で最近追加された%DebugTrackRetainingPath(x)コマンド(Node.jsはまだサポートしています)を使用し、V8ソースをダウンロードし、V8デバッガーをビルドして使用し、上記のJSイメージを実行すると、必要なリンクが取得されますルートオブジェクトまでの変数。 ガベージコレクターの呼び出しを忘れないでください。 例では、これはgc()の呼び出しです。
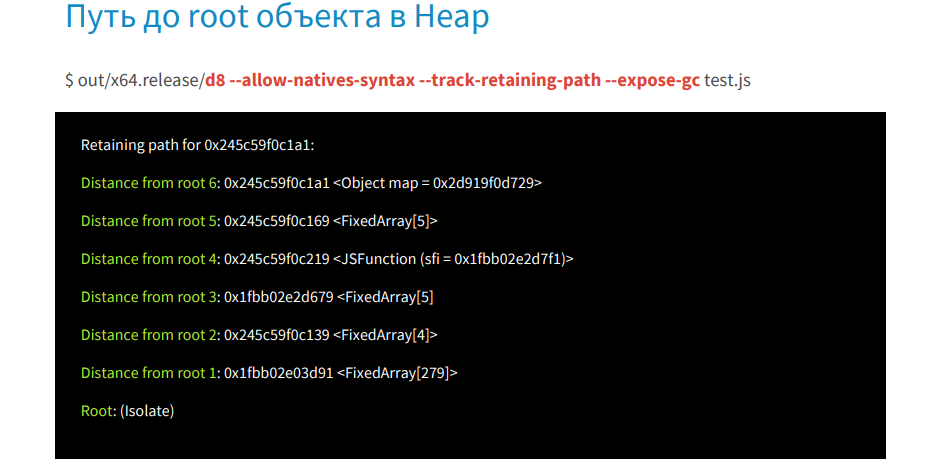
フラグ--allow-natives-syntax、-track-retaining-path、-expose-gc、およびファイルtest.jsを指定してdebug8を実行します。 リストでは、オブジェクトをルートに保持しているユーザーと対象を段階的に取得します。
そのため、実稼働環境でのメモリリークの検索を検討しました。
アプリケーションパフォーマンスプロファイリング
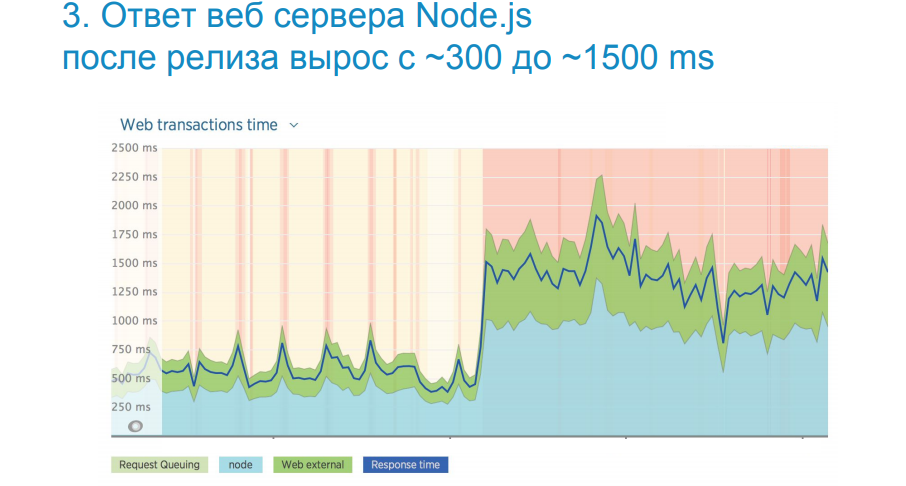
上の画像では、次のリリース後にパフォーマンスが5倍低下した実際の例を見ることができます。 Web UIアプリケーションのロード時間が劇的に増加しました。
そのような場合には、アクションのシンプルで効果的なアルゴリズムがあります。これを以下に示します。

2013年にNode.jsにプロファイラーが追加されましたが、昨年はtick-processor(V8のログとレポートを処理するツール)のみが登場しました。 その前に、ティックプロセッサを備えたV8プロファイラを使用するか、V8自体をダウンロードしてビルドし、そこでツールでプロセッサをアクティブ化する必要がありました。
プロファイラーは高レベルの情報を提供し、問題の性質を判断し、どの機能が最も長く実行されたかを確認するのに役立ちます。
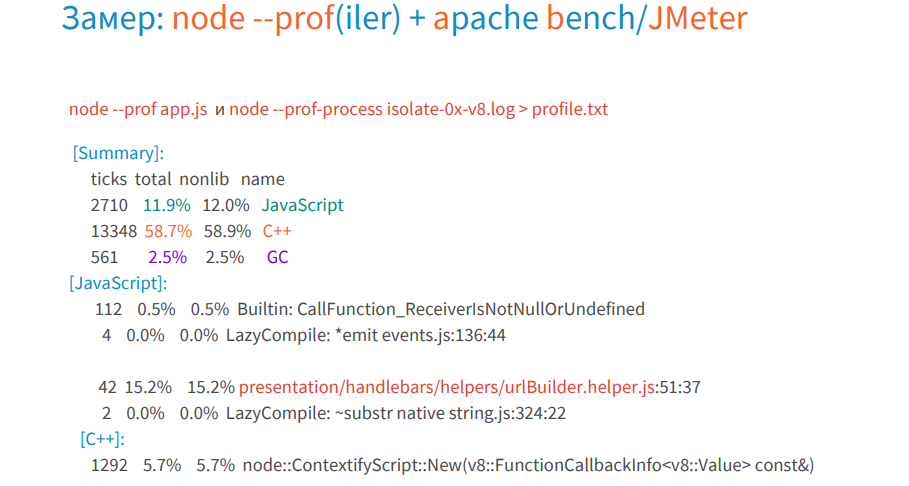
このログのデータはグラフィカル形式で便利に表示され、フレームグラフと呼ばれます。 2013年にブレンダングレッグによって開発されました。
2015年にグラフを取得することは本当に頭痛の種でしたが、現在は0xを使用して1つのチームによって作成されています。
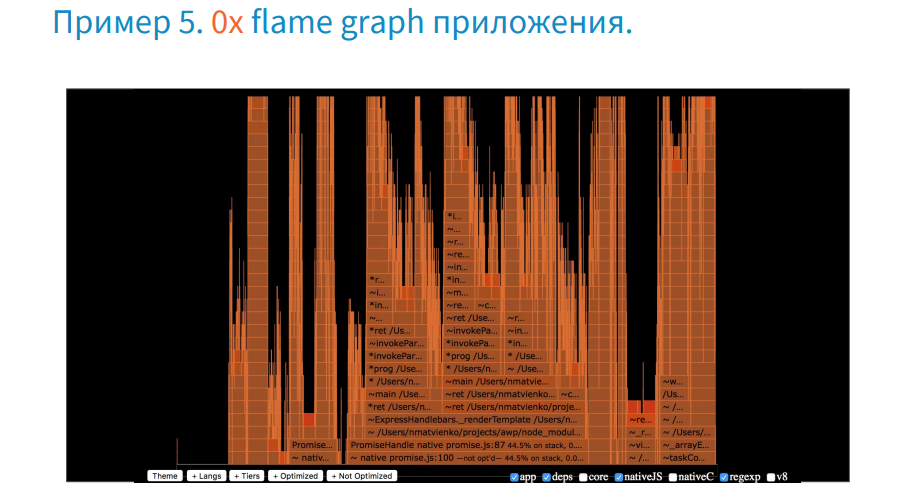
次に、それをどのように使用するかを考えてみましょう。
アプリケーションのプロファイルを強調するには、下のボタンで不要なものをすべて削除します。 その結果、アプリケーションは総実行時間のほんの一部しか占めないことがわかります。
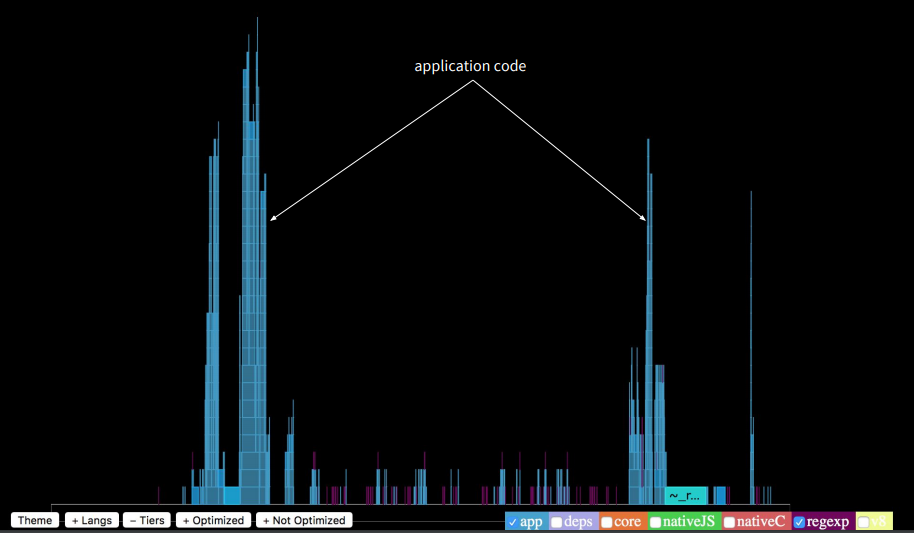
関数呼び出しシーケンスのスタックトレースは有限であり、画面に収まります。 その後、何が長い時間がかかりますか? npmパッケージの強調表示をオンにすると、アプリケーション自体よりも9倍長く実行されることがわかります。 これはたくさんあります。
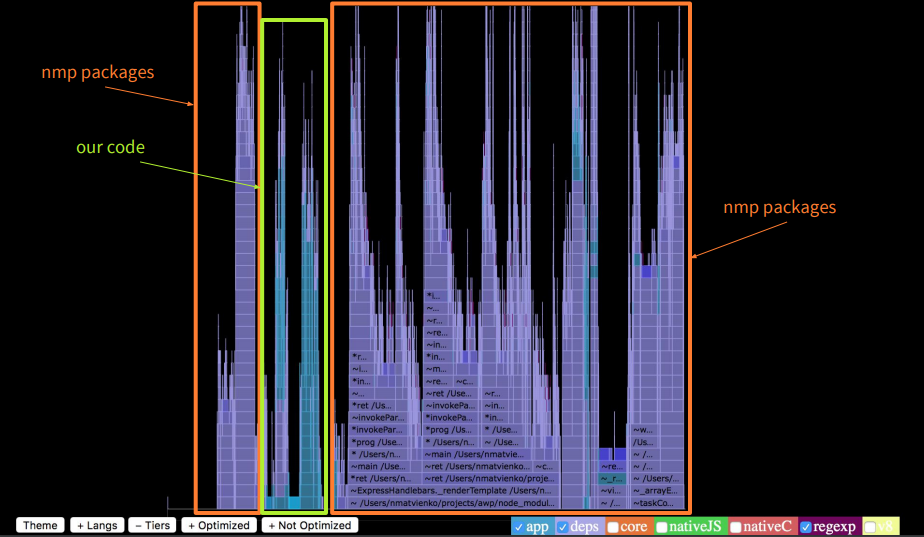
最適化された関数を強調すると、それらの関数が非常に少ないことがわかります。 呼び出しの約90%は最適化されていません。
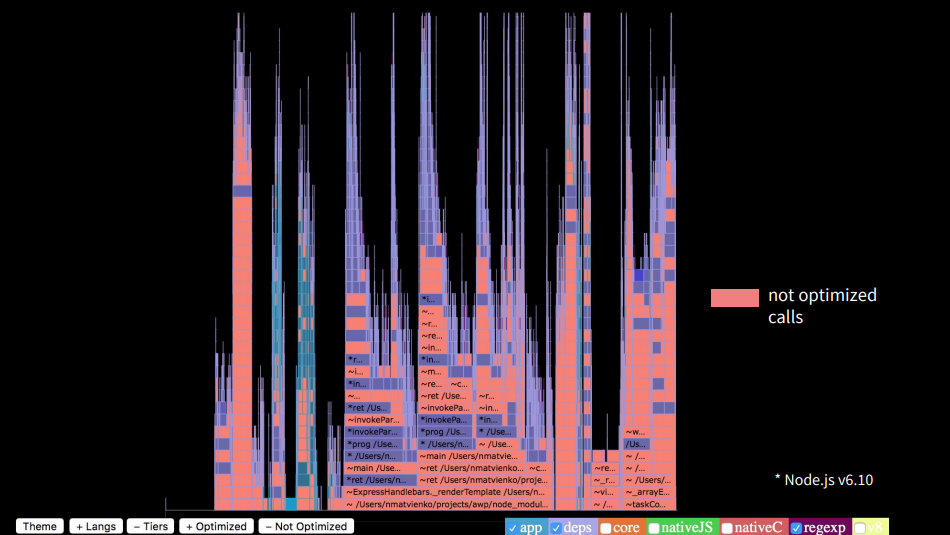
呼び出しの上部を見ると、アプリケーションでは多くのスタックがハンドルバーにあったことがわかります。さらに、マージオブジェクトを作成するlodashマージがあり、サードパーティのユーティリティも時間がかかりました。
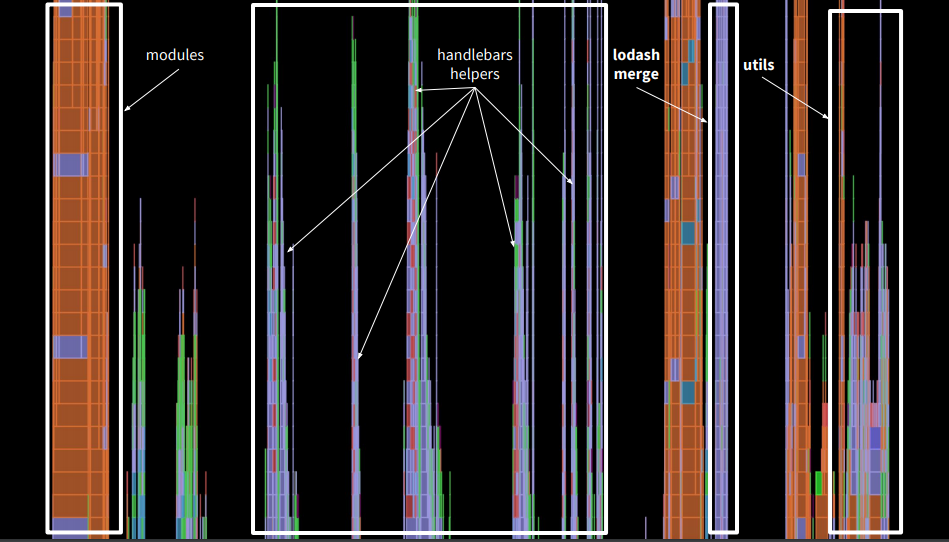
, , , . . — .
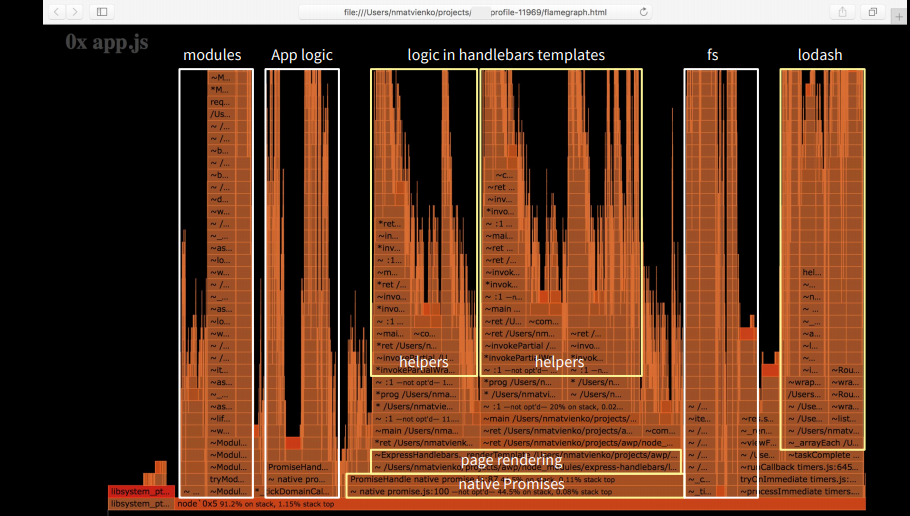
?
- CPU : merge, JSON, string parse
- view templates
- npm-
- Node.js ( V8 optimization killers) —
, .

, handlebars helpers. view , — . , . , ,- .
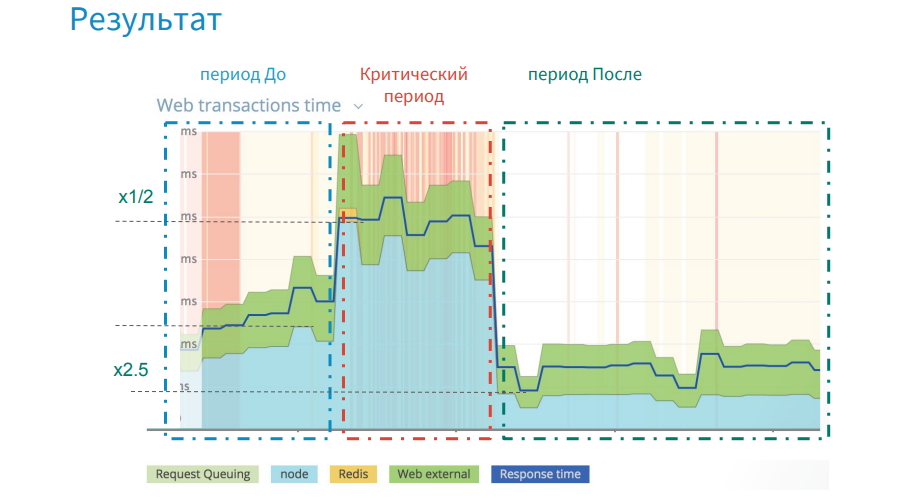
, , . . 3,5 , .
, ( JSON) , . , .
おわりに
- staging/pre-production environments
, . ,
HolyJS 2018 Piter ,
Main Thread Node.js . JS, :