こんにちは、Habr! 「最初のニューラルネットワークのトレーニング:基本分類」の記事の翻訳を紹介します 。

これは、スニーカーやシャツなどの衣服の画像を分類するためのニューラルネットワークモデルのトレーニングガイドです。 ニューラルネットワークを作成するには、pythonとTensorFlowライブラリを使用します。
TensorFlowをインストールする
作業には、次のライブラリが必要です。
- numpy(書き込むコマンドラインで:pip install numpy)
- matplotlib(コマンドラインで:pip install matplotlib)
- keras(作成するコマンドラインで:pip install keras)
- jupyter(コマンドラインで:pip install jupyter)
pip:を使用して、コマンドラインでpip install tensorflowを記述します
エラーが発生した場合は、.whlファイルをダウンロードし、 pipを使用してインストールできます 。pipinstall file_path \ file_name.whl
TensorFlow公式インストールガイド
Jupyterを起動します。 コマンドラインから開始するには、jupyter Notebookを作成します。
はじめに
このガイドでは、10カテゴリの70,000グレースケール画像を含むFashion MNISTデータセットを使用します。 画像は衣類の個々のアイテムを低解像度(28 x 28ピクセル)で示しています。

ネットワークのトレーニングに60,000個の画像を使用し、10,000個の画像を使用して、ネットワークが画像を分類するためにどれだけ正確に学習したかを評価します。 データをインポートおよびダウンロードするだけで、TensorFlowからFashion MNISTに直接アクセスできます。
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
データセットをロードすると、4つのNumPy配列が返されます。
- 配列train_imagesおよびtrain_labelsは、モデルがトレーニングに使用するデータです
- 配列test_imagesおよびtest_labelsは、モデルをテストするために使用されます。
画像は0〜255の範囲のピクセル値を持つ28x28 NumPy配列です。ラベルは0〜9の整数の配列です。これらは衣服のクラスに対応しています。
| ラベル | クラス |
| 0 | Tシャツ(Tシャツ) |
| 1 | ズボン(パンツ) |
| 2 | プルオーバー(セーター) |
| 3 | ドレス |
| 4 | コート(コート) |
| 5 | サンダル |
| 6 | シャツ |
| 7 | スニーカー(スニーカー) |
| 8 | バッグ |
| 9 | ショートブーツ(ショートブーツ) |
クラス名はデータセットに含まれていないため、独自に規定します。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
データマイニング
モデルをトレーニングする前に、データセットの形式を検討してください。
train_images.shape
データの前処理
モデルを準備する前に、データを前処理する必要があります。 トレーニングセットの最初の画像を確認すると、ピクセル値が0〜255の範囲にあることがわかります。
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False)

これらの値を0〜1の範囲にスケーリングします。
train_images = train_images / 255.0 test_images = test_images / 255.0
トレーニングセットの最初の25個の画像を表示し、各画像の下にクラス名を表示します。 データが正しい形式であることを確認してください。
plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]])

モデル構築
ニューラルネットワークを構築するには、モデルのレイヤーを調整する必要があります。
ニューラルネットワークの主要な構成要素はレイヤーです。 深層学習のほとんどは、単純なレイヤーを組み合わせることです。 tf.keras.layers.Denseなどのほとんどのレイヤーには、トレーニング中に学習されるパラメーターがあります。
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation=tf.nn.relu), keras.layers.Dense(10, activation=tf.nn.softmax) ])
ネットワークの最初のレイヤーtf.keras.layers.Flattenは、画像形式を2d配列(28 x 28ピクセル)から28 * 28 = 784ピクセルの1d配列に変換します。 このレイヤーには調査するパラメーターはなく、データを再フォーマットするだけです。
次の2つのレイヤーはtf.keras.layers.Denseです。 これらは、密接に接続された、または完全に接続された神経層です。 最初の高密度レイヤーには、128個のノード(またはニューロン)が含まれます。 2番目(および最後)のレベルは、10個のノードtf.nn.softmaxを持つレイヤーで、合計が1である10個の確率推定の配列を返します。各ノードには、現在の画像が10クラスの1つに属する確率を示す推定が含まれます。
モデルのコンパイル
モデルのトレーニングの準備ができる前に、さらにいくつかの設定が必要になります。 これらは、モデルのコンパイルフェーズで追加されます。
- 損失関数-トレーニング中のモデルの精度を測定します
- オプティマイザーは、表示されるデータと損失関数に基づいてモデルが更新される方法です。
- メトリック(メトリック)-トレーニングとテストの段階を制御するために使用
model.compile(optimizer=tf.train.AdamOptimizer(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
モデルトレーニング
ニューラルネットワークモデルを学習するには、次の手順が必要です。
- モデルトレーニングデータの送信(この例では、train_imagesおよびtrain_labels配列)
- モデルは、画像とタグを関連付けることを学習します。
- モデルにテストスイート(この例ではtest_images配列)について予測するように依頼します。 ラベル配列(この例ではtest_labels配列)からラベル予測の適合性を確認します
トレーニングを開始するには、model.fitメソッドを呼び出します。
model.fit(train_images, train_labels, epochs=5)
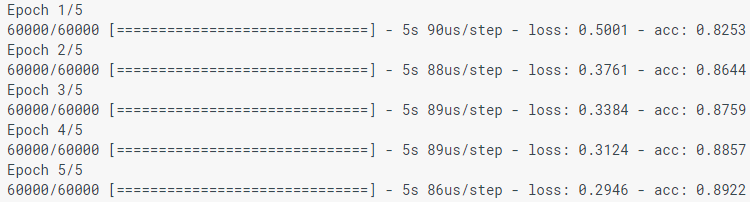
モデルをモデル化すると、損失(損失)および精度(acc)のインジケーターが表示されます。 このモデルは、トレーニングデータによると約0.88(または88%)の精度を達成します。
精度評価
テストデータセットでのモデルの動作を比較します。
test_loss, test_acc = model.evaluate(test_images, test_labels) print('Test accuracy:', test_acc)

テストデータセットの精度は、トレーニングデータセットの精度よりもわずかに低いことがわかります。 トレーニングの精度とテストの精度の間のこのギャップは、再トレーニングの例です。 再トレーニングとは、機械学習モデルがトレーニングデータよりも新しいデータの方がうまく機能しない場合です。
予測
モデルを使用して、いくつかの画像を予測します。
predictions = model.predict(test_images)
ここで、モデルはテストケースの各画像のラベルを予測しました。 最初の予測を見てみましょう:
predictions[0]

予測は10個の数字の配列です。 それらは、画像が衣服の10の異なるアイテムのそれぞれに対応するというモデルの「自信」を説明しています。 どのラベルの信頼度が最も高いかを確認できます。
np.argmax(predictions[0])
したがって、モデルは、このイメージが足首ブーツ(足首ブーツ)またはclass_names [9]であることを最も確信しています。 そして、テストラベルをチェックして、これが正しいことを確認できます。
test_labels[0]
これらの予測を視覚化する関数を作成します。
def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
0番目の画像、予測、および予測の配列を見てみましょう。
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)

予測を使用していくつかの画像を作成しましょう。 正しい予測ラベルは青で、間違った予測ラベルは赤です。 彼が非常に自信があるときでさえ、これは間違っているかもしれないことに注意してください。
num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels)

最後に、訓練されたモデルを使用して、単一の画像に関する予測を行います。
Tf.kerasモデルは、パッケージ(バッチ)またはコレクション(コレクション)の予測を行うために最適化されています。 したがって、単一の画像を使用しますが、リストに追加する必要があります。
画像の予測:
predictions_single = model.predict(img) print(predictions_single)

plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)

np.argmax(predictions_single[0])
前と同様に、モデルはラベル9を予測します。
質問がある場合は、コメントまたはプライベートメッセージに書いてください。