アジアからヨーロッパへの移住についてここに書いたことがありますが、このヨーロッパで私がやっていることを書きたいと思います。 そのような職業がありますDevOps 、またはむしろそうではありませんが、それがまさに今私がやっていることです。 Dockerで実行されるすべてのオーケストレーションに、 ランチャーを使用します。これについても書きました 。 しかし、その後、ひどいことが起こりました。Rancher2.0が登場し、kubernetes(以降、単にk8s)に移行しました。k8sが実際にクラスターを管理するための標準になったため、ブラックジャックと図書館員でインフラストラクチャ全体を再構築したいという要望がありました。 違法行為を追加するのは、会社がさまざまな国からさまざまな伝統を持つさまざまな専門家を常に雇い、誰かがpuppet持ち込み、誰かがansibleもansibleで、誰かが一般的にMakefile + bashがすべてだと考えているというansibleです。 したがって、すべてがどのように機能するかについて明確な意見はありませんが、私は本当にやりたいです。
このような技術とツールの動物園は以前に組み立てられました。

インフラ管理
- ミニクベ
- Rke
- テラフォーム
- コプス
- キューブスプレー
- アンシブル
アプリケーション管理
- クベルネテス
- 牧場主
- クベクトル
- ヘルム
- 確認
- コンポーズ
- ジェンキンス
ロギングとモニタリング
- Elasticsearch
- キバナ
- 流entなビット
- テレグラフ
- Influxdb
- ザビックス
- プロメテウス
- グラファナ
- カパシトール
次に、この動物園の各ポイントについて簡単に説明し、なぜ必要なのか、なぜこのソリューションが選ばれたのかを説明します。 実際、ほとんどすべてのアイテムは数十個の類似物に置き換えることができますが、まだ選択が完全にはわからないため、誰かが意見や推奨事項をお持ちの場合は、喜んでコメントでそれを読みます。
Kubernetesがすべての中心になります。なぜなら、今では本当に代替手段がないソリューションであり、AmazonとMicrosoftからmail.ruまでのすべてのプロバイダーによってサポートされているからです。 代替案がどのように検討されたか
Swarm離陸したことはありませんNomad -捕食者のために見知らぬ人によって書かれているようですCattleはレンジャー1.xのエンジンであり、現在は原則としてすべてが問題ありませんが、牧場主は既にk8を優先して放棄しているため、開発はありません。
インフラ構築
最初に、インフラストラクチャを作成し、その上にk8sクラスターを展開する必要があります。 いくつかのオプションがあり、それらはすべて機能するため、最適なものを選択することは困難です。
Minikubeは、テスト目的で開発者のマシンでクラスターを起動するための優れたオプションです。
Rke -Rancher kubernetesエンジン、ドアと同じくらいシンプル、クラスターを作成するための最小限の設定
nodes: - address: localhost role: [controlplane,worker,etcd]
これですべてです。ローカルマシンでクラスターを起動するのに十分ですが、本番稼働可能なHAクラスターの作成、構成の変更、クラスターのアップグレード、etcdデータベースのダンプなどを行うことができます。
Kops-クラスターを作成できるだけでなく、awsまたはgceでインスタンスを事前作成できます。 また、terraformの構成を生成することもできます。 興味深いツールですが、まだ定着していません。 terraform + rke完全に置き換えられますが、よりシンプルで柔軟です。
Kubespray-実際、k8sクラスターを作成するのは単なる強力な役割であり、強力で、柔軟で、構成可能です。 これは、事実上、k8を展開するためのデフォルトのソリューションです。
Terraformは、aws、azure、またはその他の場所にインフラストラクチャを作成するためのツールです。 柔軟で安定した-お勧めします。
Ansibleは実際にはk8sについてではありませんが、どこでも、ここでも使用しています:構成の調整、ソフトウェアのインストール/更新、証明書の配布。 安くて陽気な。
アプリケーション管理
クラスターができたので、ここで何か有用なものを開始する必要がありますが、それを行う方法の問題だけが残っています。
オプション1:kubectlを使用して、すべてのk8をそのままデプロイしkubectl 。 原則として、このオプションには生命権があります。 Kubectlは、展開、アップグレード、現在の状態の監視、その場での構成の変更、ログの表示、特定のコンテナへの接続など、必要なすべてを実行できる強力なツールです。 しかし、時にはすべてをもう少し便利にしたいので、先に進みます。
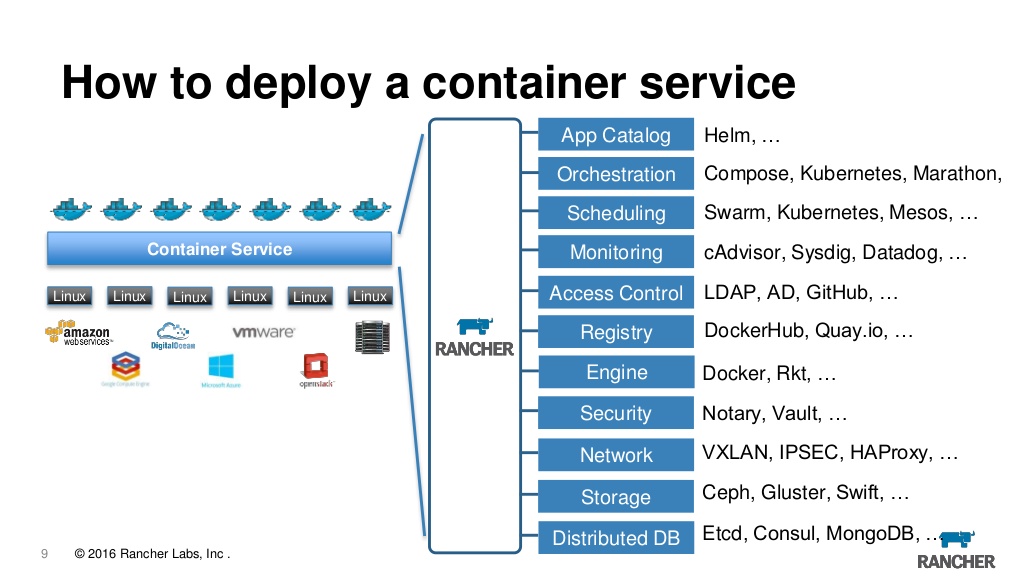
実際、今では牧場主はk8を管理するためのWeb銃口であると同時に、便利さを追加する多くの小さなバンです。 ここでは、ログの表示、コンソールへのアクセス、アプリケーションとロールベースのアクセス制御、組み込みのメタデータサーバー、アラーム、ログリダイレクト、シークレット管理などを構成およびアップグレードできます。 数年前から最初のバージョンランチャーを使用しており、完全に満足していますが、k8sに切り替えると本当に必要かどうかという疑問が生じることを認めなければなりません。 以前に作成したクラスターを牧場主にインポートできること、および任意のプロバイダーからクラスターをインポートできることは素晴らしいことです。つまり、紺KSからローカルに作成されたEKSからクラスターをインポートし、それらを1つの場所から1つのサーバーに移動できます。 さらに、突然疲れた場合、rancherサーバーを単純に解体し、kubecltまたは他のツールを使用してクラスターを直接使用し続けることができます。
コードとしてのあらゆるものの非常に正しい概念が今では人気があります。 たとえば、コードとしてのインフラストラクチャはjenkins pipelineを使用して実装され、コードとしてのアセンブリはjenkins pipeline介して実装されます。 これでアプリケーションの番になりました。 アプリケーションのインストールと構成もマニフェストに記述し、gitに保存する必要があります。 Rancherバージョン1.xは標準のdocker-compose.ymlを使用し、すべてが順調でしたが、k8に切り替えるとhelm chartsに切り替えhelm charts 。 Helmは、私の観点からすると、奇妙な論理とアーキテクチャとの絶対に恐ろしい共有です。 これは、見知らぬ人のために捕食者によって、またはその逆に書かれたという感覚があるプロジェクトの1つです。 唯一の問題は、k8sヘルムの世界では単に代替手段がなく、これが事実上の標準であるということです。 したがって、私たちは泣くために刺されますが、舵を使い続けます。 バージョン3.xでは、開発者はそれを一から書き直すことを約束し、すべての奇妙な点を排除してアーキテクチャを簡素化します。 それは私たちが癒すときですが、今のところは私たちが持っているものを食べます。
また、少なくともここでjenkinsについて言及する必要があります。これは、kubernetisのトピックに直接関係するものではありませんが、アプリケーションをクラスターにデプロイするのに役立ちます。 彼は、彼は働いており、彼は別の記事のトピックです。
モニタリング
現在、クラスタがあり、何らかのアプリケーションを回転させています。息を吐くことができるように見えますが、実際にはすべてが始まったばかりです。 アプリケーションはどれくらい安定していますか? どれくらい速い? 彼は十分なリソースを持っていますか? 一般的にクラスターで何が起こっていますか?
はい、次のトピックは監視とロギングです。 明確な答えは3つだけです。 grafana 、 grafanaそれらを見て、 grafanaでグラフィックをgrafanaます。 他のすべての質問については、多数の正解があります。
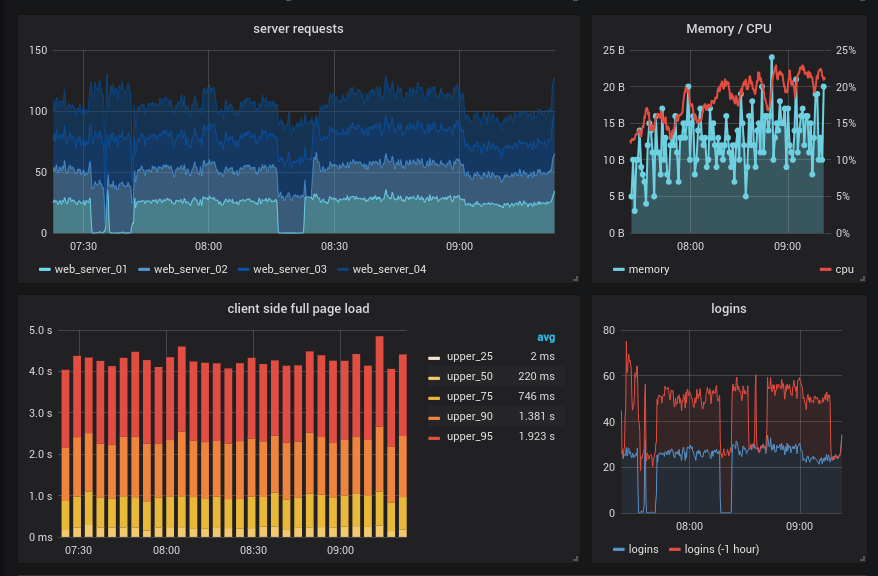
ここでは、 grafana自体から始めますが、実際には何もしませんが、以下に説明するシステムのいずれかに美しい顔のように固定し、美しくクリアなグラフィックを取得することができます。さらに、すぐにアラームを設定できますが、 prometheus alertmanagerような他のソリューションを使用することをお勧めしますprometheus alertmanagerおよびElastAlert 。
私の観点からは、現時点ではこれはログの最適なアグリゲーターおよびルーターであり、さらに、箱から出してすぐにk8sをサポートしています。 Fluentdもありますが、ルーブルで記述されており、従来のコードを多く使用しているため、あまり魅力的ではありません。 したがって、fluent-bitにまだ移植されていないfluentdの特定のモジュールが必要な場合は、それ以外のすべてで使用します。bitが最適な選択です。 より高速で、より安定しており、消費するメモリも少なくなります。 すべてまたは選択したコンテナからログを収集し、それらをフィルタリングし、kubernetis固有のデータを追加することでログを強化し、すべてをelasticsearchまたは他の多くのリポジトリに送信できます。 従来のlogstash + docker-bit + file-bitと比較するとlogstash + docker-bit + file-bitこのソリューションはあらゆる点で間違いなく優れています。 歴史的に、私たちはまだlogspout + logstash使用していますが、 logspout + logstashなビットが間違いなく勝ちます。
マイクロサービスアーキテクチャ専用に作成された監視システム。 さらに、業界のデファクトスタンダードとして、k8s専用に作成されたPrometheus Operatorと呼ばれるプロジェクトがまだあります。 誰もが何を選択するかを決定しますが、彼の仕事の論理を理解するためだけに、裸のプロメテウスから始める方が良いです。それは通常のシステムとはまったく異なります。 また、マシンレベルのメトリックを収集できるnode-exporterと、rancher apiを使用してメトリックを収集できるprometheus-rancher-exporterに言及する必要があります。 一般に、kubernetesにクラスターがある場合、プロメテウスは必須です。
ここでやめることができますが、歴史的には、さらにいくつかの監視システムがあります。 第一に、 zabbixがインフラストラクチャ全体のすべての問題を1つのパネルに表示することzabbix非常に便利です。 自動検出の存在により、新しいネットワーク、ノード、サービス、およびほぼすべてを監視にすばやく見つけて追加できるため、動的インフラストラクチャを監視するための便利なツール以上のものになります。 さらに、バージョン4.0では、プロメテウスエクスポーターからのメトリックのコレクションがzabbixに追加され、これらすべてが1つのシステムに非常に美しく統合できることがわかりました。 zabbixをk8sクラスターにドラッグする必要があるかどうかについての明確な答えはまだありませんが、試してみるのは間違いなく興味深いです。
代替手段として、 TIG (telegraf + influxdb + grafana)使用できます。構成が簡単で、安定して動作します。コンテナ、アプリケーション、ノードなどによってメトリックを集約できますが、プロメテウスの機能を本質的に複製できます。
したがって、役に立つものを始める前に、数十の補助サービスとツールからバインディングをインストールして構成する必要があることがわかりました。 同時に、この記事では、永続的なデータ、秘密、およびその他の奇妙なものを管理する問題を提起しませんでした。これらはそれぞれ別の出版物に取り込むことができます。
そして、理想的なインフラストラクチャをどのように見ていますか?
意見がある場合は、コメントを書いてください。または、私たちのチームに参加して、まとめてください。