[パート1/2]

Hikeブログは2012年12月12日に登場し、当時は読者がほとんどいませんでした。 2016年までに、1か月あたりの登録ユーザー数は1億人、メッセージ数は400億に達しました。 しかし、このような成長は、インフラストラクチャの規模拡大の問題を浮き彫りにしました。 それをなくすには、手頃な価格で高性能のプラットフォームが必要でした。 2016年と2017年に、私たちは仕事で多くの中断に遭遇しました、私たちは緊急にこれで何かをしなければならなかったので、私たちはさまざまなオプションを検討し始めました。
スケーラブルで信頼性の高いクラウド環境でアプリケーションを迅速に作成、テスト、展開できるクラウドプラットフォームが必要でした。 一見、すべての主要なクラウドプラットフォームは多くの点で類似しているように見えますが、いくつかの根本的な違いがあります。
この出版物を2つの部分に分けます。
- GCPを選択する理由
- ダウンタイムなしでGCPに切り替える
概念実証
まず、コンセプトの正しさを証明することから始めました。このコンセプトでは、既存のインフラストラクチャとGoogle Cloudクラウドプラットフォームが提供するサービスとの互換性を調べ、将来の開発のための要素も計画しました。
コンセプト検証の主要領域:
⊹ロードバランサー
⊹計算機
⊹ネットワーキングとファイアウォール
⊹セキュリティ
⊹クラウドの可用性
⊹ビッグデータ
⊹請求
コンセプトの確認には、仮想マシン/ネットワーク/ロードバランサーの帯域幅のテストとチェック、安定性、スケーラビリティ、セキュリティ、監視、課金、ビッグデータ、機械学習サービスが含まれます。 2017年6月に、インフラストラクチャ全体をGoogle Cloudクラウドプラットフォームに移行するという重要な決定を下しました。
私たちは、遭遇した無数の課題に対処できるクラウドプラットフォームを選択したかったのです。
⊹ロードバランサー:
毎日数千万のアクティブなユーザー接続を処理するためのローカルHAProxyクラスターの管理に関連する多くの問題がありました。 グローバルロードバランサー(GLB)は、多くの問題を解決しました。

グローバルGCPロードバランシングを使用すると、単一のエニーキャストIPアドレスは、「事前に温める」必要なく、マネージドインスタンスグループ(MIG)などのさまざまなGCPサーバーに毎秒最大100万のリクエストを転送できます。 GLBでは、複数のソースにトラフィックを分散できるプール実装を使用しているため、全体的な応答時間は1.7〜2倍改善されました。
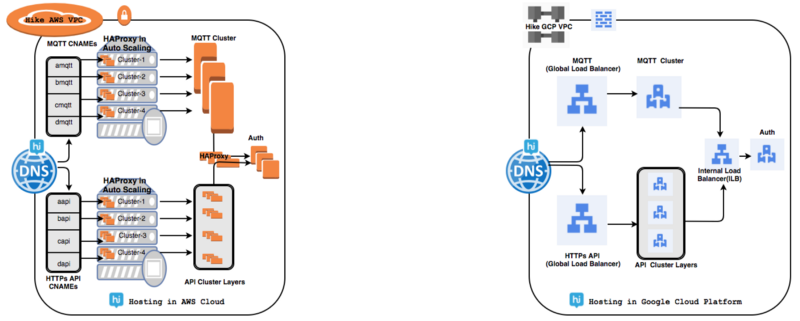
⊹コンピューティングマシン:
コンピューター自体に大きな問題はありませんでしたが、手頃な価格で高性能のプラットフォームが必要でした。 Google仮想マシンの合計スループットは1.3〜1.5倍増加し、実行中の仮想マシンインスタンスの総数を減らすことができました。
Redisテストは、6コピーのクラスター(8コア、各30 GB)で実施されました。 以下の結果に基づいて、GCPはほとんどのREDIS操作で最大48%(平均)のパフォーマンスの改善を、特定のREDIS操作で最大77%のパフォーマンスの改善をもたらすと結論付けています。
redis-benchmark -h -p 6379 -d 2048 -r 15 -q -n 10000000 -c 100

Google Compute Engine(GCE)クラウドコンピューティングサービスは、以下を使用してインフラストラクチャを管理する上で追加の利点を提供します。
● マネージドインスタンスグループ(MIG): MIGは、各ゾーンにリソースを割り当てる代わりに、マルチゾーン機能を備えた堅牢な環境でアプリケーションサービスを維持するのに役立ちます。 MIGは、グループ内の動作不能インスタンスを自動的に識別して修正し、すべてのインスタンスの最適な動作を保証します。
● 動的移行:動的移行は、ソフトウェアやハードウェアの更新などのホスト障害が発生した場合でも、仮想マシンインスタンスを維持するのに役立ちます。 以前のクラウドパートナーと協力して、スケジュールされたメンテナンスイベントに関する通知を受け取り、稼働中の仮想マシンに切り替えるために仮想マシンの停止と起動を強制されました。
● カスタム仮想マシン: GCPのフレームワーク内で、プロセッサの処理能力と特定のワークロードに必要なメモリ量を備えた独自の仮想マシンを作成できます。
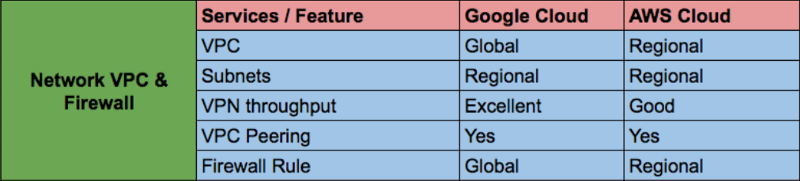
⊹ネットワークとファイアウォール:
複数のネットワークとファイアウォールルールを管理することは簡単ではなく、リスクにつながる可能性があります。 GCP Network VPCはデフォルトでグローバルであり、追加の設定やネットワーク帯域幅の変更なしに地域間通信を提供します。 ファイアウォールルールは、タグルール名を使用するプロジェクトにVPCの柔軟性を提供します。
低遅延で高帯域幅のネットワークでは、10ギガビット/秒の帯域幅を持つ高価なインスタンスを選択せざるを得ず、これらのインスタンスで拡張ネットワークをアクティブにしました。
⊹セキュリティ:
セキュリティは、クラウドサービスプロバイダーにとって最も重要な側面です。 過去には、セキュリティはほとんどのサービスで利用できなかったか、または追加オプションのみでした。
Googleクラウドサービスはデフォルトで暗号化されています。 GCPは、いくつかのレベルの暗号化を使用してデータを保護します。 いくつかのレベルの暗号化を使用すると、バックアップデータが保護され、Identity-Aware Proxyサービスを使用してデフォルトで非アクティブなデータを暗号化するなど、アプリケーション要件に基づいて最適なアプローチを選択できます。
さらに、GCPは、最新のプロセッサ(Meltdown、Spectre)の大部分での投機的実行に基づいて、最近の壊滅的な脆弱性を解決します。 GoogleはRetpolineと呼ばれる新しいバイナリ変更メソッドを開発しました 。これにより、この問題を回避し、ユーザーに見えないように作業インフラストラクチャ全体を透過的に変更できます。
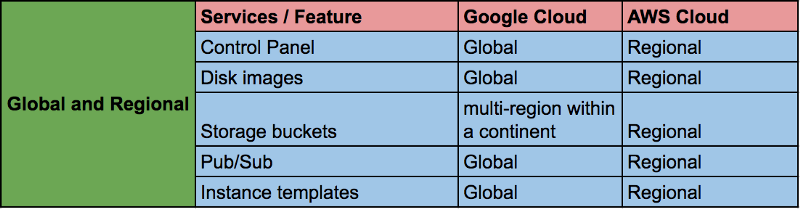
⊹クラウドの可用性:
GCPリソースの可用性は他のクラウドソリューションプロバイダーの可用性とは異なります。これは、コントロールパネルを含むほとんどのGCPリソースがゾーンまたは地域のいずれかであるためです。 プライベート接続のためにVPCまたはVPN接続をピアリングする必要がある個別のアカウントから、個々のプロジェクトの複数のVPCを管理する必要がありました。 また、画像のコピーを別のアカウントに保管する必要がありました。
Google Cloudでは、ほとんどのリソースはグローバルまたはリージョナルです。 このようなリソースには、コントロールパネル(プロジェクトのすべての仮想マシンを1つの画面で表示できる)、ディスクイメージ、データを格納するコンテナー(大陸内のいくつかの地域)、VPC(ただし、個別のサブネットは地域)、グローバルロードバランシング、パブリケーションが含まれますサブスクリプションなど
⊹ビッグデータ:
モノリシックで管理が困難な分析構成から完全に管理されたBQシステムに移行し、次の3つの領域で改善が行われました。
●クエリ処理速度が最大50倍に向上。
●自動スケーリングを備えた完全に管理されたデータ処理システム。
●データ処理時間は数時間から15分に短縮されました。
⊹充電中:
さまざまなクラウドサービスプロバイダーを比較することは困難でした。これは、多くのサービスが類似または比較できず、異なる使用シナリオで異なり、固有の使用シナリオに依存していたためです。
GCPの利点:
● 長期使用割引:特定のしきい値に達したときに仮想マシンの使用を増やして適用されます。 会計月のほとんどの期間に実行されるワークロードに対して、最大30%の割引を自動的に受けることができます。
● 分単位の課金: GCEで仮想マシンを割り当てる場合、最低10分間料金が請求されます。その後、仮想マシンの実際の使用に対する分単位の課金が開始されます。 これにより、マシンインスタンスが1時間未満で実行されている場合でも、1時間を支払う必要がないため、コストが大幅に削減されます。
● 優れた機器、インスタンスの削減: GCPを使用すると、ほぼすべてのレベルとアプリケーションで、同じワークロードを同じパフォーマンスでより少ないインスタンスで実行できることがわかりました。
● 冗長性よりもコミットメント:もう1つの要因は、仮想マシンインスタンスの価格に対するGCPのアプローチです。 AWSでは、仮想マシンインスタンスのコストを削減する主な方法は、1〜3年間リザーブドインスタンスを購入することです。 ワークロードで仮想マシンの構成を変更する必要がある場合、またはこのインスタンスが不要な場合は、予約済みインスタンスの市場で低価格で販売する必要がありました。 GCPには、プロセッサとメモリのリソースを予約するときに適用される「コミットメント使用割引」があり、使用する仮想マシンインスタンスは関係ありません。
結論:
この詳細な分析に基づいて、GCPに切り替えることを決定し、移行スキームとチェックリストの作業を開始しました。 次の記事では、このプロジェクトの実施中に学んだことについて話します。