ご注意 perev。 A:元の記事はVMwareの人々によって設立されたBlueDataの代表者によって書かれました。 彼女は、さまざまな環境でビッグデータ分析と機械学習のためのソリューションを簡単に(簡単、高速、安価に)展開することを専門としています。 BlueK8sと呼ばれる会社の最近のイニシアチブは、著者が「ステートフルアプリケーションをデプロイしてKubernetesで管理する」ためにオープンソースツールのギャラクシーを組み立てることを望んでおり、これに貢献することも求められています。 著者は、Kubernetesで特別なトレーニングを受けておらず、K8sでSpark、Cassandra、Hadoopなどのアプリケーションを展開しているビッグデータの分野の愛好家を支援しています。 これを行う方法の簡単な説明は、記事に記載されています。 ただし、プロジェクトの初期準備状況はアルファ以前であることに注意してください。
KubeDirectorは、Kubernetesの複雑でスケーラブルなステートフルアプリケーションからのクラスターの起動を簡素化するように設計されたオープンソースプロジェクトです。 KubeDirectorは、
カスタムリソース定義 (CRD)フレームワークを使用して実装され、ネイティブKubernetes API拡張機能を使用し、その哲学に依存しています。 このアプローチは、Kubernetesのユーザーおよびリソース管理と、既存のクライアントおよびユーティリティとの透過的な統合を提供します。
最近発表された KubeDirectorプロジェクトは、BlueK8sと呼ばれるKubernetes向けのより大きなオープンソースイニシアチブの一部です。 これで、初期の(アルファ版以前の)
KubeDirectorコードが利用可能になったことをお知らせします。 この投稿では、その仕組みを示します。
KubeDirectorは次の機能を提供します。
- Kubernetesのネイティブクラウド以外のステートフルアプリケーションを実行するためにコードを変更する必要はありません。 つまり、既存のアプリケーションを分解してマイクロサービスアーキテクチャパターンに一致させる必要はありません。
- アプリケーション固有の構成と状態を保存するためのネイティブサポート。
- Kubernetesの新しいステートフルアプリケーションの起動時間を最小化する、アプリケーションに依存しない展開パターン。
KubeDirectorを使用すると、Hadoop、Spark、Cassandra、TensorFlow、Caffe2などの集中的なデータ処理を行う分散アプリケーションに慣れているデータサイエンティストは、Goでコードを記述する必要なく、Kubernetesでそれらを実行できます。 これらのアプリケーションがKubeDirectorによって制御される場合、それらは単純なメタデータと関連する構成セットによって定義されます。 アプリケーションメタデータは、
KubeDirectorAppリソースとして定義されます。
KubeDirectorのコンポーネントを理解するには、次のようなコマンドを使用し
てGitHubのリポジトリを複製します。
git clone http://<userid>@github.com/bluek8s/kubedirector.
Spark 2.2.1アプリケーションの
KubeDirectorApp定義は、
kubedirector/deploy/example_catalog/cr-app-spark221e2.json 。
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
アプリケーションクラスター構成は、
KubeDirectorClusterリソースとして定義されます。
Spark 2.2.1クラスターを使用したサンプルの
KubeDirectorClusterの定義は、
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml入手できます。
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
KubeDirectorを使用してKubernetesでSparkを起動する
KubeDirectorを使用してKubernetesでSparkクラスターを起動するのは簡単です。
まず、
kubectl versionコマンドを使用してKubernetesが実行されていることを確認します(バージョン1.9以降)。
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
次のコマンドを使用して、KubeDirectorサービスとサンプル
KubeDirectorAppリソース
KubeDirectorAppをデプロイします。
cd kubedirector make deploy
その結果、KubeDirectorで開始されます。
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
kubectl get KubeDirectorApp実行して、KubeDirectorにインストールされているアプリケーションのリストを表示します。
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
これで、
KubeDirectorClusterのサンプルファイルと
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yamlを使用して、Spark 2.2.1クラスターを起動できます。 開始したことを確認します。
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
Sparkは実行中のサービスのリストにも登場しました。
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
ブラウザでポート31533にアクセスすると、Spark Master UIが表示されます。
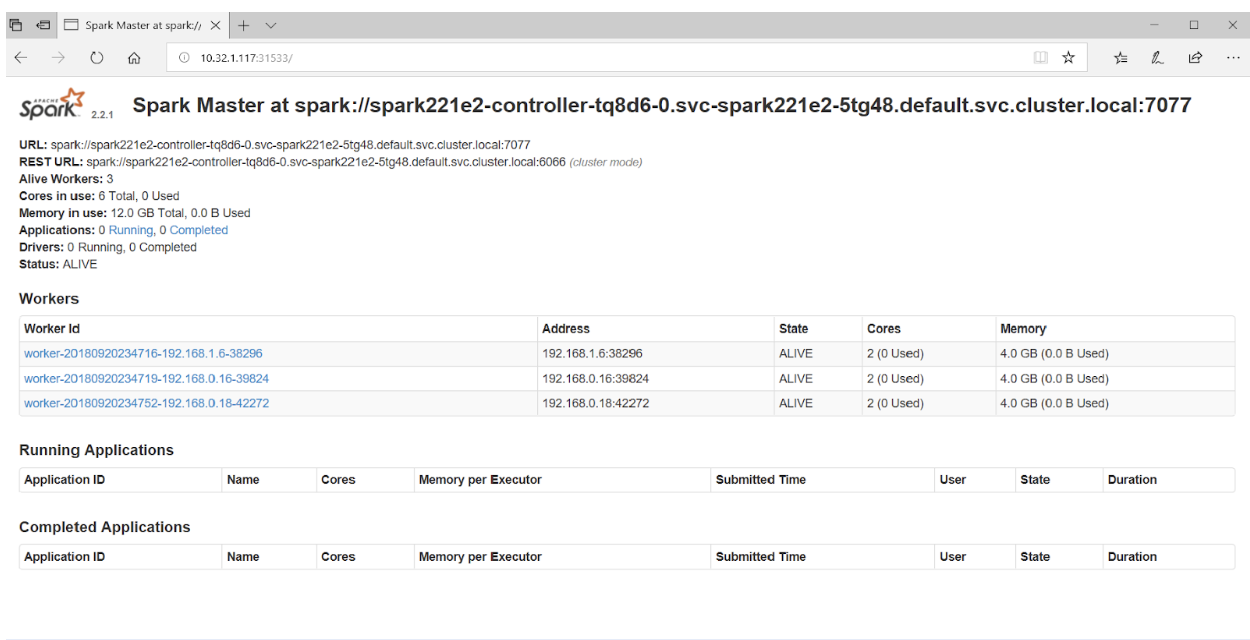
以上です! 上記の例では、Sparkクラスターに加えて、
Jupyter Notebookもデプロイし
ました 。
別のアプリケーション(Cassandraなど)を起動するには、
KubeDirectorApp別のファイルを指定するだけ
KubeDirectorApp 。
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Cassandraクラスターが開始したことを確認します。
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
Kubernetesは、Sparkクラスター(Jupyterノートブックを使用)とCassandraクラスターを実行するようになりました。 サービスのリストは、
kubectl get serviceコマンドで
kubectl get service 。
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
翻訳者からのPS
KubeDirectorプロジェクトに興味がある場合は、
そのwikiにも注意を払う必要があり
ます 。 残念ながら、パブリックロードマップを見つけることはできませんでしたが、
GitHubの問題は、プロジェクトの進行状況と主要な開発者の見解に光を当てました。 さらに、KubeDirectorに興味がある人のために、著者は
Slackチャットと
Twitterへのリンクを提供しています。
ブログもご覧ください。