Profi.ruでのクライアントルーティング/セマンティック検索の構築および任意の外部コーパスのクラスタリング
TLDR
これは、Profi.ru DS部門で約2か月で何をしたかについての非常に短いエグゼクティブサマリー(またはティーザー)です(もう少し長くいましたが、自分自身とチームをオンボーディングすることは別のことでした最初に行われます)。
予測される目標
- クライアントの入力/意図を理解し、それに応じてクライアントをルーティングします(最終的には入力品質にとらわれない分類子を選択しましたが、先行入力文字レベルモデルと言語モデルも考慮しました。簡易ルール)。
- まったく新しいサービスと既存のサービスの同義語を見つけます。
- (2)のサブゴールとして-任意の外部コーパスで適切なクラスターを構築することを学ぶ。
達成された目標
明らかに、これらの結果の一部は私たちのチームだけでなく、いくつかのチームによっても達成されました(つまり、ドメインコーパスと手動注釈のスクレイピング部分は明らかにしませんでしたが、スクレイピングはチームでも解決できると信じていますが、十分なプロキシ+セレンのおそらくいくつかの経験)。
ビジネス目標:
88+% (vs〜60 88+%対エラスティック検索)クライアントルーティング/インテント分類の精度( 5kクラス);- 検索は入力品質(ミスプリント/部分的な入力)に依存しません。
- 分類子は一般化され、言語の形態学的構造が活用されます。
- 分類子は、さまざまなベンチマークで弾性検索を大幅に下回ります(以下を参照)。
- 安全のために-少なくとも
1,000新しいサービスが見つかった+少なくとも15,000同義語(対5,000の現在の状態+ 30,000 )。 この数字は、トリプルの2倍になると予想しています。
最後の箇条書きは概算ですが、保守的なものです。
また、ABテストが続きます。 しかし、これらの結果には自信があります。
「科学的な」目標:
- ダウンストリーム分類タスク+ KNNとサービス同義語のデータベースを使用して、現代の文埋め込み技術の多くを徹底的に比較しました。
- UNSUPERVISEDメソッドを使用して、このベンチマーク(以下の詳細を参照)で、弱監視(基本的に分類子はn-gram)の弾性検索に勝ちました 。
- 適用されたNLPモデルを構築する新しい方法を開発しました(プレーンバニラbi-LSTM +埋め込みのバッグ、基本的に高速テキストはRNNに適合)-これはロシア語の形態を考慮し、一般化します。
- 最先端の教師なしアルゴリズム(UMAP + HDBSCAN)と組み合わせた最終的な埋め込み手法(最高の分類器からのボトルネックレイヤー)が星のクラスターを生成できることを実証しました。
- 実際に、以下の可能性、実現可能性、使いやすさを実証しました。
- 動的増強を使用したテキストベースの分類子のトレーニングは、より大きな静的データセットの生成と比較して、収束時間を大幅に短縮しました(つまり、CNNは、極端に少ない増強された文で示される誤りを一般化することを学習します);
全体的なプロジェクト構造
これには最終分類子は含まれません。
また、最終的に、分類器のボトルネックを支持して、偽のRNNモデルとトリプレット損失モデルを放棄しました。

現在NLPで機能しているのは何ですか?
鳥瞰図:

また、NLPが現在Imagenetの瞬間を経験していることを知っているかもしれません。
大規模なUMAPハック
クラスターを構築するときに、基本的にUMAPを100m +ポイント(または場合によっては10億)のサイズのデータセットに適用する方法/ハックを見つけました。 基本的にFAISSで KNNグラフを作成し、GPUを使用してメインUMAPループをPyTorchに書き換えるだけです。 私たちはそれを必要とせず、概念を放棄しました(結局10〜15mポイントしかありませんでした)が、詳細についてはこのスレッドに従ってください。
最適なもの
- 教師付き分類の場合、ファストテキストはRNN(bi-LSTM)+厳選されたn-gramのセットを満たします。
- 実装-n-gramのプレーンPython + PyTorch埋め込みバッグレイヤー。
- クラスタリングの場合-このモデルのボトルネックレイヤー+ UMAP + HDBSCAN。
最高の分類器ベンチマーク
手動で注釈が付けられた開発セット
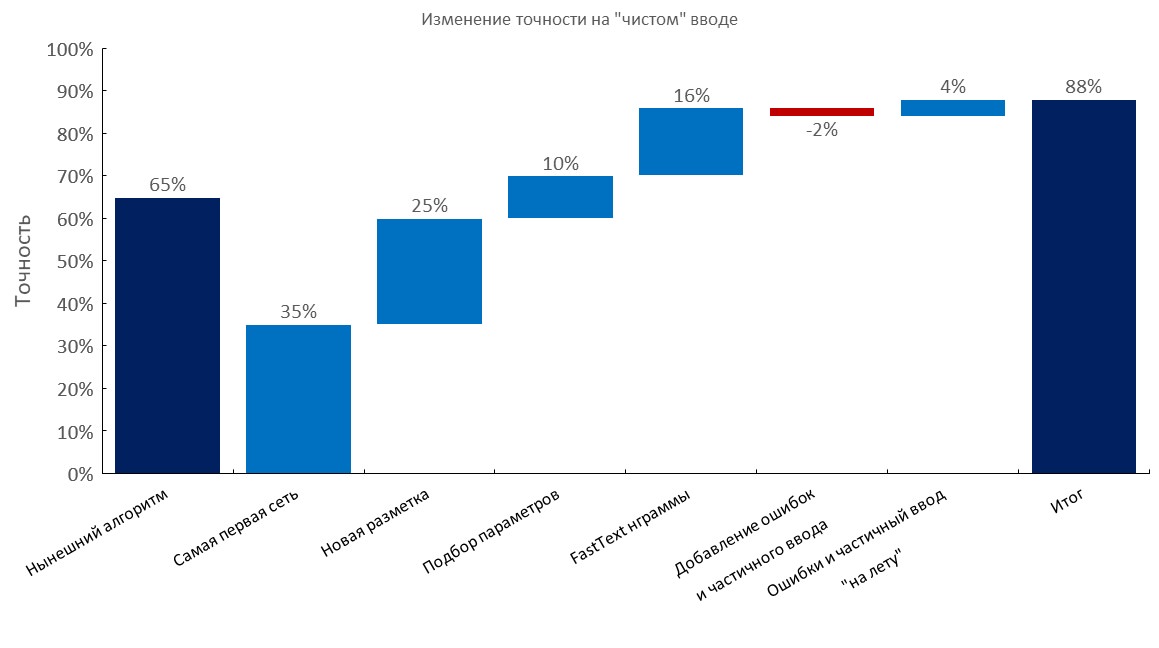
左から右:
(トップ1の精度)
- 現在のアルゴリズム(弾性検索);
- 最初のRNN;
- 新しい注釈。
- チューニング
- 高速テキスト埋め込みバッグレイヤー。
- タイプミスと部分的な入力の追加。
- エラーと部分的な入力の動的な生成( トレーニング時間が10倍に短縮 );
- 最終スコア;
手動注釈付きの開発セット+クエリごとに1〜3個のエラー

左から右:
(トップ1の精度)
- 現在のアルゴリズム(弾性検索);
- 高速テキスト埋め込みバッグレイヤー。
- タイプミスと部分的な入力の追加。
- エラーと部分的な入力の動的な生成。
- 最終スコア;
手動注釈付きの開発セット+部分入力
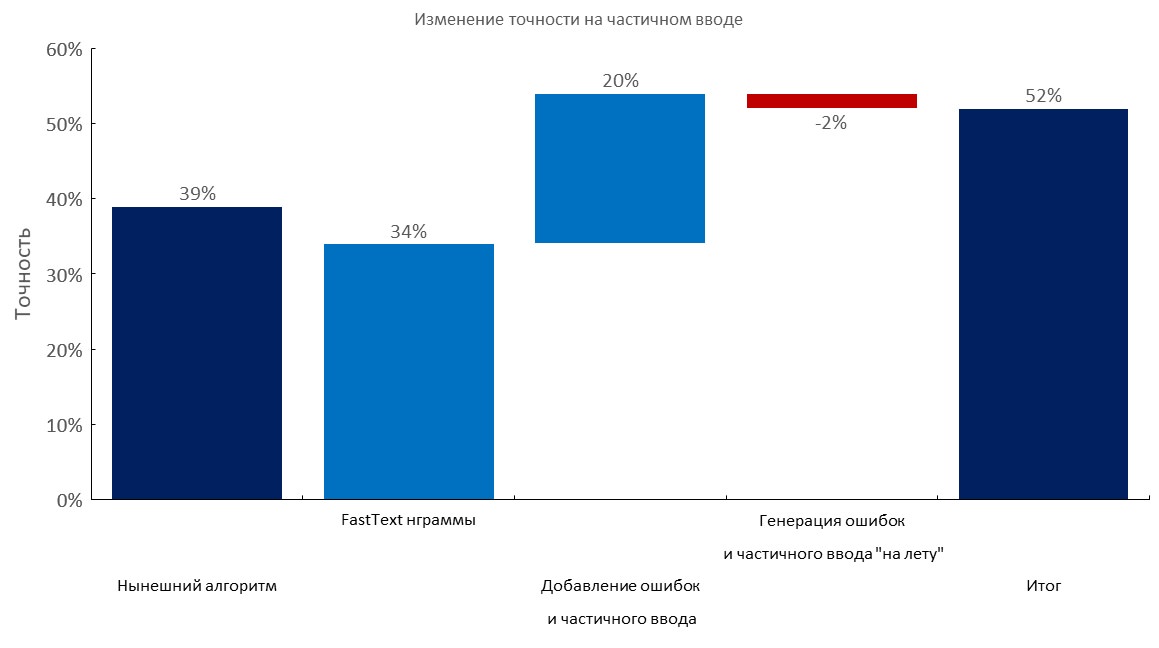
左から右:
(トップ1の精度)
- 現在のアルゴリズム(弾性検索);
- 高速テキスト埋め込みバッグレイヤー。
- タイプミスと部分的な入力の追加。
- エラーと部分的な入力の動的な生成。
- 最終スコア;
大規模コーパス/ N-gram選択
- ロシア語の最大のコーパスを収集しました:
- 1TBのクロールを使用して1 億語の単語辞書を収集しました。
- また、このハックを使用して、このようなファイルをより高速に(一晩)ダウンロードします。
- 分類器に最適な
1m n-gramのセットを選択して、ベストを一般化しました(ロシア語版ウィキペディアでトレーニングされた高速テキストから最も人気のあるn-gram +ドメインデータで最も人気のあるn-gram
100万語彙での100万n-gramのストレステスト:

テキスト拡張
一言で言えば:
- エラーのある大きな辞書(例:10〜100mの一意の単語)を取得します。
- エラーを生成します(文字をドロップ、計算された確率を使用して文字を交換、ランダムな文字を挿入、キーボードレイアウトを使用するなど)。
- 新しい単語が辞書にあることを確認してください。
私たちはこのようなサービスに多くのクエリを強引に強制し(本質的にデータセットをリバースエンジニアリングするために)、内部には非常に小さな辞書があります(また、このサービスはn-gram機能を備えたツリー分類器によって強化されています)。 彼らが私たちがいくつかのコーパスで持っていた単語の30-50%しかカバーしていないのを見るのはちょっと面白かったです 。
大規模なドメイン語彙にアクセスできる場合、私たちのアプローチははるかに優れています 。
最良の教師なし/半教師ありの結果
KNNは、さまざまな埋め込み方法を比較するためのベンチマークとして使用されました。
(ベクターサイズ)テストされたモデルのリスト:
- (512)200 GBの一般的なクロールデータでトレーニングされた大規模な偽文検出器。
- (300)サービスからウィキペディアのランダムな文を伝えるように訓練された偽の文検出器。
- (300)ここから取得した高速テキスト。アラネウム体で事前にトレーニング済み。
- (200)ドメインデータでトレーニングされた高速テキスト。
- (300)200GBの共通クロールデータでトレーニングされた高速テキスト。
- (300)Wikipediaのサービス/同義語/ランダム文で訓練されたトリプレット損失を伴うシャムネットワーク。
- (200)埋め込みバッグRNNの埋め込みレイヤーの最初の反復、文は埋め込みバッグ全体としてエンコードされます。
- (200)同じですが、最初に文が単語に分割され、次に各単語が埋め込まれ、次に平均が取られます。
- (300)上記と同じですが、最終モデル用です。
- (300)上記と同じですが、最終モデル用です。
- (250)最終モデルのボトルネック層(250ニューロン);
- 弱く監督された弾性検索ベースライン。
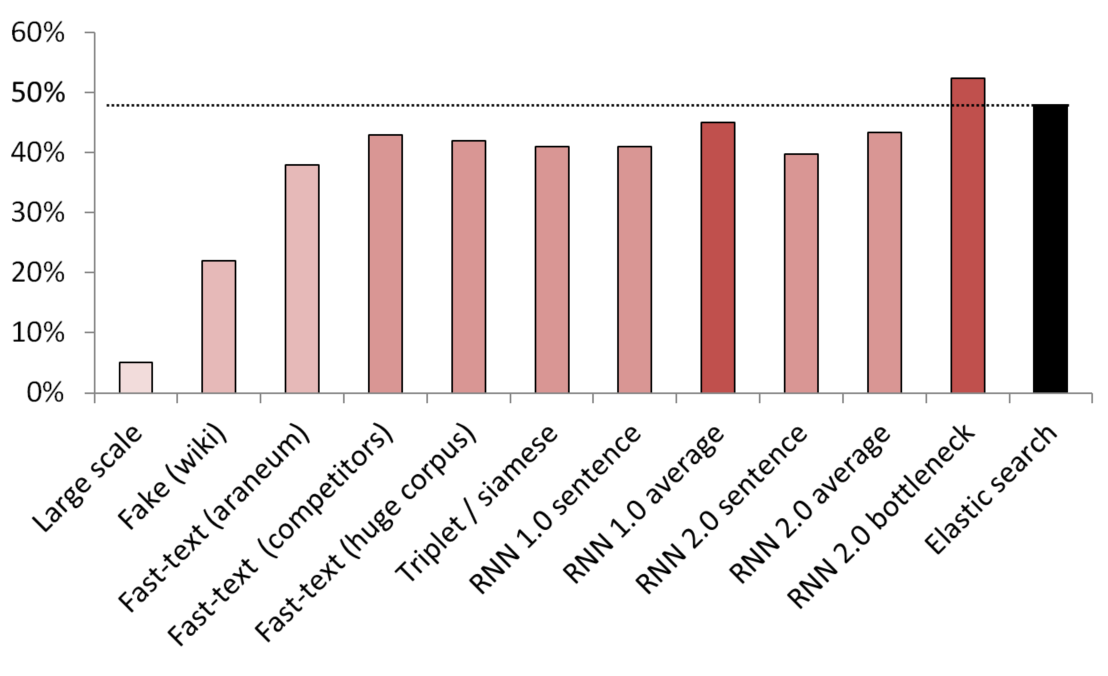
リークを避けるために、すべてのランダムな文がランダムにサンプリングされました。 彼らの言葉の長さは、彼らが比較されたサービス/同義語の長さと同じでした。 また、ボキャブラリーを分離することでモデルが学習するだけではないことを確認するための対策が講じられました(埋め込みは凍結され、Wikipediaは各ウィキペディアの文に少なくとも1つのドメインワードがあることを確認するためにアンダーサンプリングされました)。
クラスターの可視化
3D

2D

クラスター探索「インターフェース」
緑-新しい単語/同義語。
灰色の背景-おそらく新しい単語。
灰色のテキスト-既存の同義語。

アブレーションテストと何が機能するのか、何を試したのか、何をしなかったのか
- 上記のチャートをご覧ください。
- 高速テキスト埋め込みの単純平均/ tf-idf平均-非常に手ごわいベースライン 。
- Fast-text>ロシア語のWord2Vec。
- 偽の文章検出による文章の埋め込みは一種の作品ですが、他の方法と比較すると見劣りします。
- BPE(センテンスピース)は、ドメインの改善を示しませんでした。
- charレベルのモデルは、Googleからの紙切れにもかかわらず、一般化するのに苦労しました。
- マルチヘッドトランスフォーマー(分類子と言語モデリングヘッドを使用)を試しましたが、手元にある注釈では、プレーンバニラLSTMベースのモデルとほぼ同じ性能を発揮しました。 悪いアプローチの埋め込みに移行したときに、LMヘッドと埋め込みバッグレイヤーの両方を使用するトランスの実用性と実用性が低いため、この一連の研究を放棄しました。
- BERT-やりすぎのようです。また、変圧器は文字通り何週間も訓練すると主張する人もいます。
- ELMO -AllenNLPのようなライブラリを使用することは、私がここで提供しない理由のために、研究/制作および教育環境の両方で私の意見では逆効果であると思われます。
展開する
使用済み:
- シンプルなWebサービスを備えたDockerコンテナ。
- 推論にはCPUのみで十分です。
- CPUでのクエリごとに〜2.5
2.5 ms 、バッチ処理は実際には必要ありません。 1GB RAMメモリフットプリント。PyTorch 、 numpy 、 PyTorch (およびWebサーバーofc)をPyTorch 、依存関係はほとんどありません。- このような高速テキストn-gram生成を模倣します。
- バッグレイヤー+インデックスを辞書に保存されたとおりに埋め込みます。