
みなさんこんにちは!
ディープ ラーニングのトピックの研究を続けて、私たちはかつて
、羊がニューラルネットワークのいたるところにあるように見える理由についてお話したいと思いました。 このトピックは、フランソワショルの本の第9章で
説明されています。
したがって、
Habréで
発表された Positive Technologiesの素晴らしい研究と、「悪意のある機械学習」は障害であり問題であるだけでなく、素晴らしい診断ツールであると考えている2人のMIT従業員の素晴らしい研究に行きました。
次-カットの下。
過去数年にわたり、悪意のある干渉の事例がディープラーニングコミュニティで深刻な注目を集めています。 この記事では、この現象を広く見て、機械学習の信頼性のより広いコンテキストにどのように適合するかを議論したいと思います。
悪意のある介入:興味深い現象議論の空間を概説するために、そのような悪意のある干渉の例をいくつか示します。 モスクワ地域に関係するほとんどの研究者が同様の写真に出くわしたと思います。
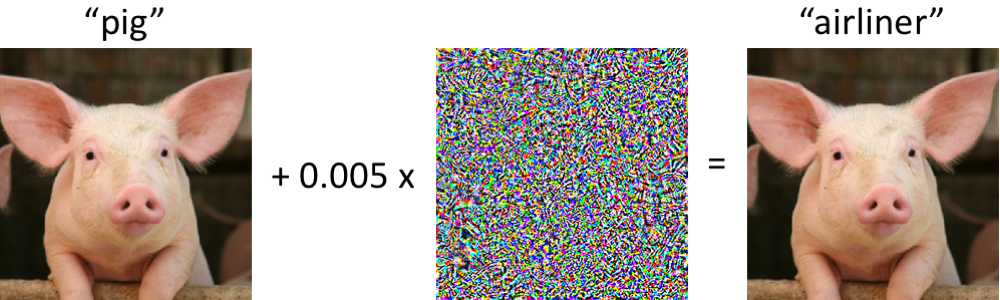
左側にはピギーがあり、現代の畳み込みニューラルネットワークによってピギーとして正しく分類されています。 画像に最小限の変更を加えた場合(すべてのピクセルは[0、1]の範囲にあり、各変更は0.005以内になります)-そして今、ネットワークはクラス「airliner」を高い信頼性で返します。 訓練された分類器に対するこのような攻撃は少なくとも2004年から知られており(
リンク )、最初の画像分類器への悪意のある干渉に対する取り組みは2006年(
リンク )に遡ります。 その後、この現象は、ニューラルネットワークがこの種の攻撃に対して脆弱であることが判明した2013年頃からかなり注目を集め始めました(
こちらと
こちらをご覧ください)。 それ以来、多くの研究者は、悪意のある例を構築するためのオプションと、そのような病理学的妨害に対する分類器の抵抗力を高める方法を提案しています。
ただし、このような悪意のある例を観察するためにニューラルネットワークを掘り下げる必要はないことを覚えておくことが重要です。
悪意のある例はどの程度回復力がありますか?おそらく、コンピューターが子豚を旅客機と混同する状況は、最初は不安になるかもしれません。 ただし、この場合に使用される分類器(
Inception-v3ネットワーク )は、一見すると壊れやすいとは限りません。 歪んだ子豚を分類しようとすると、おそらくネットワークが誤っていますが、これは特別に選択された違反の場合にのみ発生します。
ネットワークは、同等の大きさのランダムな妨害に対してはるかに耐性があります。 したがって、主な問題は、ネットワークの脆弱性を引き起こすのは悪意のある妨害かどうかです。 マルウェア自体が各入力ピクセルの制御に決定的に依存している場合、現実的な条件下で画像を分類する場合、このような悪意のあるサンプルは深刻な問題ではないようです。
最近の研究では、そうでないことが示されています。特定の物理シナリオでさまざまなチャネル効果に対する摂動の安定性を確保することが可能です。 たとえば、悪意のあるサンプルは通常のオフィスプリンターで印刷できるため、スマートフォンのカメラで撮影した画像
は依然として正しく分類されません 。 ニューラルネットワークがさまざまな実際のシーンを誤って分類しているため、ステッカーを作成することもできます(たとえば、
link1 、
link2および
link3を参照 )。 最後に、最近、研究者は3Dプリンターで3Dタートルを印刷しましたが、標準のインセプションネットワークでは、ほぼすべての視野角で
ライフルを誤っ
て認識しています。
誤った分類攻撃の準備このような悪意のある妨害を作成する方法は? 多くのアプローチがありますが、最適化により、これらのさまざまな方法をすべて一般化された表現に減らすことができます。 ご存じのように、分類器のトレーニングは、多くの場合、モデルパラメーターを見つけることとして定式化されます。
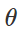
与えられた例のセットの経験的損失関数を最小化する

:
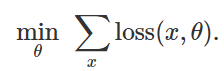
したがって、固定モデルの誤った分類を引き起こすために
および「無害」な入力
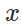
自然に限られた妨害を見つけようとする

そのような損失

最大であることが判明しました:
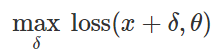
この定式化に基づいて、悪意のある入力を作成するための多くの方法は、さまざまな制約のセット(小さな勾配ステップ、投影勾配降下など)のさまざまな最適化アルゴリズムと見なすことができます(小さい
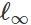
-通常の妨害、ピクセルの小さな変化など)。 次の記事には多くの例が記載されています:
link1 、
link2 、
link3 、
link4および
link5 。
上記で説明したように、悪意のあるサンプルを生成する多くの成功した方法は、固定されたターゲット分類子で機能します。 したがって、問題は重要です。これらの外乱は特定のターゲットモデルのみに影響しませんか? 興味深いことに、いいえ。 多くの摂動法を使用する場合、結果の悪意のあるサンプルは、分類器から、初期乱数値の異なるセットまたは異なるモデルアーキテクチャでトレーニングされた分類器に転送されます。 さらに、ターゲットモデルへのアクセスが制限されている悪意のあるサンプルを作成することもできます(この場合、「ブラックボックス攻撃」と呼ばれることもあります)。 たとえば、次の5つの記事を参照してください:
link1 、
link2 、
link3 、
link4および
link5 。
写真だけでなく悪意のあるサンプルは、画像の分類だけでなく検出されます。 同様の現象は、
音声認識 、
質疑応答システム 、
強化学習 、その他の問題の解決で知られています。 既にご存じのとおり、悪意のあるサンプルの調査は10年以上にわたって行われています。
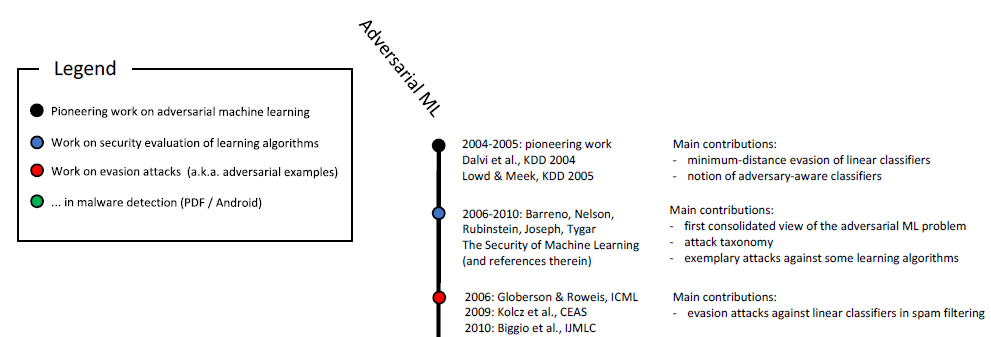
悪意のある機械学習の時系列スケール(開始)。 フルスケールは図に示されています。
この研究の 6。
さらに、セキュリティ関連のアプリケーションは、機械学習の悪意のある側面を研究するための自然な環境です。 攻撃者が分類器をだまし、悪意のある入力(スパムやウイルスなど)を無害なものとして渡すことができる場合、機械学習に基づくスパム検出器またはウイルス対策スキャナーは
無効になります。 これらの考慮事項は純粋に学術的なものではないことを強調する必要があります。 たとえば、2011年のGoogleセーフブラウジングチームは、攻撃者がマルウェア検出システムを回避しようとした方法
に関する複数年にわたる調査を公開しました。 また、GMailメールでのスパムフィルタリングのコンテキストでのマルウェアサンプルに関するこの
記事も参照してください。
安全だけでなく悪意のあるサンプルの研究に関する最新の研究はすべて、セキュリティを確保するための鍵として非常に明確に維持されています。 これは合理的な観点ですが、このようなサンプルはより広い文脈で検討されるべきだと考えています。
信頼性まず第一に、悪意のあるサンプルはシステム全体の信頼性の問題を提起します。 安全性の観点から分類器のプロパティを合理的に説明する前に、メカニズムが高い分類精度を提供することを確認する必要があります。 最終的に、トレーニング済みのモデルを実際のシナリオに展開する場合、これらの変更が悪意のある干渉または単なる自然な変動によるものであるかどうかに関係なく、基本データの分布を変更するときに高度な信頼性を実証する必要があります。
これに関連して、悪意のあるサンプルは、機械学習システムの信頼性を評価するための有用な診断ツールです。 特に、マルウェアに敏感なアプローチにより、訓練された分類器が慎重に選択された(通常は静的な)テストセットで実行される標準の評価プロトコルを超えることができます。
したがって、驚くべき結論に達することができます。 たとえば、高度な最適化手法を使用しなくても、悪意のあるサンプルを簡単に作成できることがわかりました。
最近の研究では
、最先端の画像分類器が小さな病理学的変化またはターンに対して驚くほど脆弱
であることを示しています。 (このトピックに関する他の作品については、
こちらと
こちらをご覧ください。)

したがって、たとえℓ∞ℓ∞放電からの摂動を重要視していなくても、回転と遷移による信頼性の問題がしばしば発生します。 より広い意味で、真の信頼性の高いコンポーネントとしてより大きなシステムに統合する前に、分類器の信頼性指標を理解する必要があります。
分類子の概念訓練された分類器がどのように機能するかを理解するには、明らかに成功または失敗した操作の例を見つける必要があります。 この場合、悪意のあるサンプルは、訓練されたニューラルネットワークが特定の概念を「学習」することの意味を直感的に理解していないことが多いことを示しています。 これは、成功が人間の成功に劣らない生物学的にもっともらしいアルゴリズムとネットワークがしばしば主張されるディープラーニングで特に重要です(たとえば、
ここ 、
ここ、または
ここを参照 )。 悪意のあるサンプルは、多くの状況で明らかにこれを疑っています。
- 画像を分類するとき、ピクセルのセットが最小限に変更されるか、画像がわずかに回転する場合、これにより、人が正しいカテゴリに割り当てることを妨げることはほとんどありません。 それにもかかわらず、そのような変更は最新の分類器によって完全に遮断されます。 オブジェクトを珍しい場所(たとえば、 木の上の羊 )に配置する場合、ニューラルネットワークが人間とシーンをまったく異なるように解釈することも簡単に確認できます。
- テキストパッセージで必要な単語を置き換えると、 質問と回答のシステムを深刻に混乱させる可能性がありますが、人の観点からは、そのような挿入によってテキストの意味は変わりません。
- この記事全体で、慎重に選択されたテキスト例は、Google翻訳の限界を示しています。
3つのケースすべてにおいて、悪意のある例は、現代のモデルの強度をテストし、どのような状況でこれらのモデルが個人の行動とはまったく異なる動作をするかを強調するのに役立ちます。
安全性最後に、悪意のあるサンプルは、機械学習が「無害な」教材で特定の精度をすでに達成している分野で本当に危険をもたらします。 ほんの数年前、画像分類などのタスクは依然として非常に不十分に実行されていたため、この場合のセキュリティ問題は二次的なもののようでした。 最終的に、機械学習システムのセキュリティの程度は、このシステムが「無害な」入力を十分な品質で処理し始めたときにのみ重要になります。 そうでなければ、私たちは彼女の予測をまだ信頼できません。
現在、さまざまな主題分野で、このような分類子の精度が大幅に向上しており、安全性を考慮することが重要な状況で分類子を展開するのは時間の問題です。 これに責任を持ってアプローチしたい場合、セキュリティのコンテキストでそれらのプロパティを正確に調査することが重要です。 しかし、セキュリティの問題には全体的なアプローチが必要です。 いくつかの機能(たとえば、ピクセルのセット)を偽造することは、たとえば、他の感覚モダリティ、カテゴリ機能、またはメタデータよりもはるかに簡単です。 最後に、セキュリティを確保する場合、変更が困難またはほとんど不可能な兆候に正確に依存することが最善です。
結果(失敗するには早すぎますか?)近年見られた機械学習の目覚しい進歩にもかかわらず、自由に使えるツールの機能の限界を考慮する必要があります。 さまざまな問題(正直、プライバシー、またはフィードバック効果に関連する問題など)があり、信頼性が最大の関心事です。 人間の知覚と認知は、さまざまな背景の環境干渉に耐性があります。 ただし、悪意のあるサンプルは、ニューラルネットワークがまだ同等の回復力とはほど遠いことを示しています。
したがって、悪意のある例を調べることの重要性は確信しています。 機械学習におけるそれらの適用可能性は、セキュリティの問題に限定されるものではありませんが、訓練されたモデルを評価するための
診断基準として役立ちます。 悪意のあるサンプルを使用するアプローチは、潜在的に明らかでない欠陥を識別するという点で、標準の評価手順および静的テストと比較して有利です。 最新の機械学習の信頼性を理解したい場合、攻撃者の観点から調査するために最新の成果が重要です(悪意のあるサンプルを正しく選択する)。
トレーニングとテスト分布の間の最小限の変更でも分類器が失敗する限り、満足のいく保証された信頼性を達成することはできません。 最終的に、信頼できるだけでなく、問題を「研究」することの意味についての直感的なアイデアと一致するモデルの作成に努めています。 その後、安全で信頼性が高く、さまざまな環境に簡単に展開できます。