クラウドプラットフォーム開発チームのインフラストラクチャエンジニアとして、ヘッダーに示されているものを含め、多くの分散ストレージシステムで作業する機会がありました。 彼らの長所と短所を理解しているようで、これについての私の考えを共有したいと思います。 つまり、ハッシュ関数をより長く持っている人を見てみましょう。

免責事項:このブログの前半で、GlusterFSに関する記事を見ることができました。 これらの記事とは何の関係もありません。 これは、クラウドのプロジェクトチームの著者のブログであり、各メンバーはそれぞれのストーリーを伝えることができます。 それらの記事の著者は私たちの運用グループのエンジニアであり、彼は彼自身のタスクと経験を共有しています。 突然意見の相違が見られる場合は、これを考慮に入れてください。 この機会にこれらの記事の著者に敬意を表します!
議論されること
GlusterFSとCephFSに基づいて構築できるファイルシステムについて話しましょう。 これら2つのシステムのアーキテクチャについて説明し、それらを異なる角度から見ていきます。最終的には、結論を出すリスクさえあります。 RBDやRGWなどの他のCeph機能は影響を受けません。
用語
記事をすべての人が理解しやすいものにするために、両方のシステムの基本的な用語を見てみましょう。
Cephの用語:
RADOS (Reliable Autonomic Distributed Object Store)は自己完結型のオブジェクトストレージであり、Cephプロジェクトの基礎となっています。
CephFS 、 RBD (RADOSブロックデバイス)、 RGW (RADOSゲートウェイ)-RADOSのさまざまなインターフェースをエンドユーザーに提供するRADOSの高レベルガジェット。
特に、CephFSはPOSIX準拠のファイルシステムインターフェイスを提供します。 実際、CephFSデータはRADOSに保存されます。
OSD (Object Storage Daemon)は、RADOSクラスター内の個別のディスク/オブジェクトストレージを提供するプロセスです。
RADOSプール (プール)-レプリケーションポリシーなどの共通のルールセットによって結合されたいくつかのOSD 。 データ階層の観点から見ると、プールはオブジェクトのディレクトリまたは個別の(サブディレクトリなしのフラットな)名前空間です。
PG (Placement Group)-PGの概念については、後で詳しく説明するためにコンテキストで紹介します。
RADOSはCephFSが構築される基盤であるため、よく説明しますが、これはCephFSに自動的に適用されます。
GlusterFSの用語(以下gl):
ブリックは、RADOSの用語でOSDの類似物である単一のディスクを提供するプロセスです。
ボリューム -ブリックが結合されるボリューム。 ボリュームはRADOSのプールに類似しており、ブリック間に特定の複製トポロジもあります。
データ配信
より明確にするために、両方のシステムで実装できる簡単な例を考えてみましょう。
例として使用するセットアップ:
- 2台のサーバー(S1、S2)、それぞれに同じボリューム(sda、sdb、sdc)の3つのディスクがあります。
- 複製のあるボリューム/プール2。
どちらのシステムでも、通常の操作には少なくとも3つのサーバーが必要です。 しかし、これは単なる記事の一例であるため、目をそらします。
glの場合、これは3つのレプリケーショングループで構成される分散複製ボリュームになります。

各レプリケーショングループは、異なるサーバー上の2つのブリックです。
実際、3つのRAID-1を組み合わせたボリュームが判明しました。
マウントし、目的のファイルシステムを取得してファイルへの書き込みを開始すると、書き込む各ファイルが全体としてこれらのレプリケーショングループのいずれかに分類されることがわかります。
これらの分散グループ間でのファイルの分散は、本質的にハッシュ関数であるDHT (Distributed Hash Tables)によって処理されます(後で説明します)。
「図」では、次のようになります。
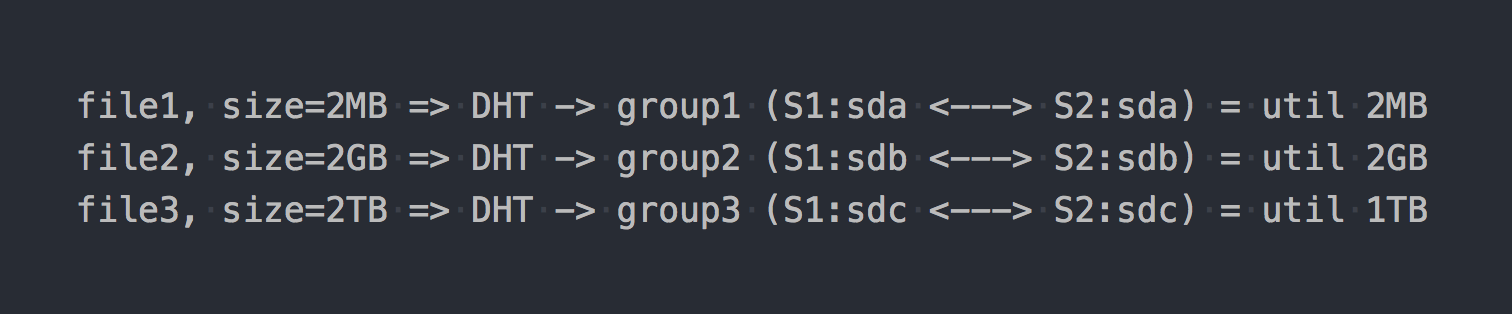
最初のアーキテクチャー機能がすでに現れているかのように:
- グループ内の場所は不均等に処理され、ファイルサイズに依存します。
- 1つのファイルを書き込むとき、IOは1つのグループのみに行き、残りはアイドル状態です。
- 単一のファイルを書き込むときに、ボリューム全体のIOを取得することはできません。
- グループにファイルを書き込むのに十分なスペースがない場合、エラーが発生し、ファイルは書き込まれず、別のグループに再配布されません。
たとえば、Distributed-Striped-ReplicatedまたはDispersed(Erasure Coding)などの他のタイプのボリュームを使用する場合、1つのグループ内のデータ分散の仕組みのみが根本的に変わります。 また、DHTはファイルを完全にこれらのグループに分解し、最終的にはすべて同じ問題が発生します。 はい、ボリュームが1つのグループのみで構成される場合、またはほぼ同じサイズのすべてのファイルがある場合、問題はありません。 しかし、さまざまなサイズのファイルを含む数百テラバイトのデータの下にある通常のシステムについて話しているため、問題があると考えています。
では、CephFSを見てみましょう。 上記のRADOSが登場します。 RADOSでは、各ディスクは個別のプロセス(OSD)によって提供されます。 セットアップに基づいて、各サーバーに3つずつ、そのうち6つだけを取得します。 次に、データ用のプールを作成し、このプールにPG番号とデータ複製係数を設定する必要があります(この場合は2)。
8 PGのプールを作成したとしましょう。 これらのPGは、OSD全体にほぼ均等に分散されます。
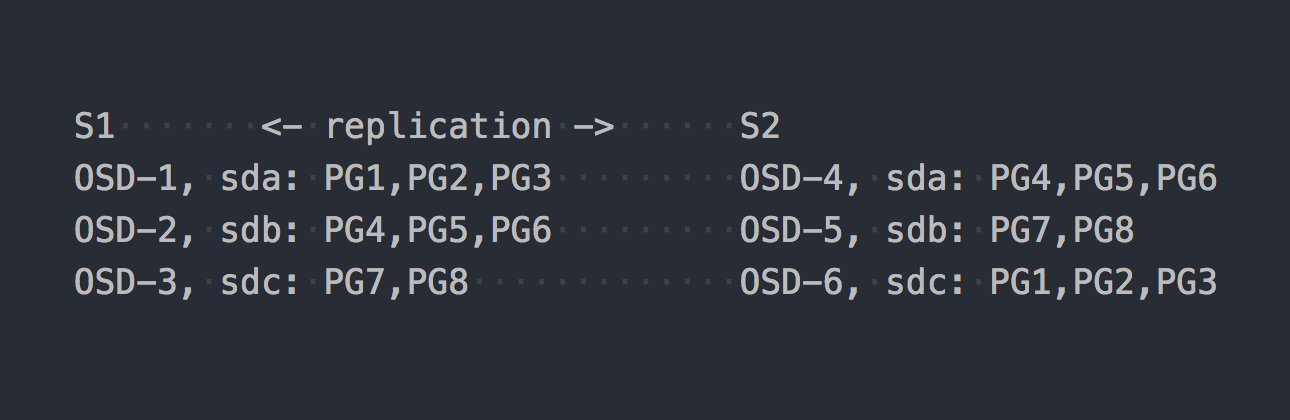
PGは、多数のオブジェクトを結合する論理グループであることを明確にするときです。 レプリケーションファクト2を設定したため、各PGは別のサーバー上の他のOSDにレプリカを持っています(デフォルト)。 たとえば、サーバーS1のOSD-1にあるPG1には、OSD-6のS2にツインがあります。 PG(またはレプリケーション3の場合はトリプル)の各ペアには、記録されているPRIMARY PGがあります。 たとえば、PG4のPRIMARYはS1にありますが、PG3のPRIMARYはS2にあります。
RADOSの仕組みがわかったので、次に新しいプールへのファイルの書き込みに進みます。 RADOSは本格的なストレージですが、ファイルシステムとしてマウントしたり、ブロックデバイスとして使用したりすることはできません。 データを直接書き込むには、特別なユーティリティまたはライブラリを使用する必要があります。
上記の例と同じ3つのファイルを作成します。
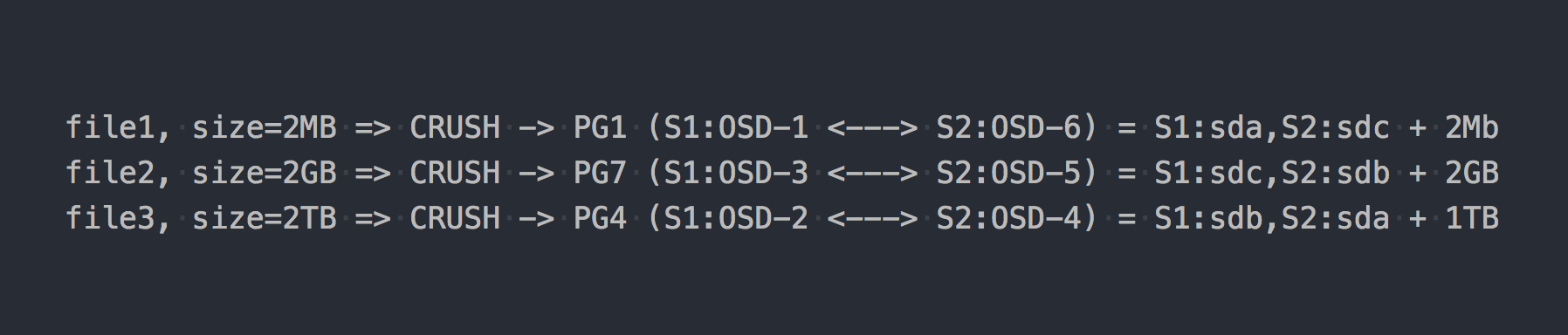
RADOSの場合、すべてが何らかの形でより複雑になっています、同意します。
その後、CRUSH(スケーラブルハッシュの下での制御されたレプリケーション)がチェーンに登場しました。 CRUSHは、RADOSが依存するアルゴリズムです(後で説明します)。 この特定のケースでは、このアルゴリズムを使用して、どのPGにファイルを書き込むかが決定されます。 ここでCRUSHはglのDHTと同じ機能を実行します。 このPG上のファイルの擬似ランダム配布の結果として、より複雑なスキームでのみglと同じ問題が発生しました。
しかし、私は1つの重要な点について意図的に黙っていました。 RADOSを純粋な形で使用している人はほとんどいません。 RADOSとの便利な作業のために、次のレイヤーが開発されました:RBD、CephFS、RGW。
これらのすべてのトランスレーター(RADOSクライアント)は異なるクライアントインターフェイスを提供しますが、RADOSでの作業は似ています。 最も重要な類似点は、それらを通過するすべてのデータが断片に分割され、個別のRADOSオブジェクトとしてRADOSに入れられることです。 デフォルトでは、公式クライアントは入力ストリームを4MBに分割します。 RBDの場合、ボリュームの作成時にストライプサイズを設定できます。 CephFSの場合、これはファイルの属性(xattr)であり、個々のファイルまたはすべてのカタログファイルのレベルで管理できます。 RGWには対応するパラメーターもあります。
ここで、前の例で取り上げたRADOSプールの上にCephFSを積み重ねたとします。 現在、問題のシステムは完全に対等な立場にあり、同一のファイルアクセスインターフェイスを提供しています。
テストファイルを新しいCephFSに書き戻すと、OSD上でまったく異なる、ほぼ均一なデータの分布が見つかります。 たとえば、2GBサイズのfile2は512個に分割され、異なるPGに分散され、その結果、異なるOSDにほぼ均一に分散されます。これにより、上記のデータ分散の問題が実際に解決されます。
この例では、8個のPGのみが使用されていますが、1つのOSDに最大100個のPGを含めることをお勧めします。 また、CephFSを機能させるには2つのプールが必要であり、RADOSを機能させるにはいくつかのサービスデーモンも必要です。 すべてがそんなに単純だとは思わないでください。本質から逸脱しないように、私は特に多くを省略します。
それで、今ではCephFSがもっと面白そうですね。 しかし、私は別の重要な点、今回はglについて言及しませんでした。 Glには、ファイルをチャンクに分割し、それらのチャンクをDHTで実行するためのメカニズムもあります。 いわゆるシャーディング(シャーディング)。
5分間の履歴
2016年4月21日、Ceph開発チームは「Jewel」をリリースしました。これは、CephFSが安定していると見なされる最初のCephリリースです。
CephFSについて叫んでいます。 そして、3〜4年前にそれを使用することは、少なくとも疑わしい決定です。 私たちは他のソリューションを探しましたが、上記のアーキテクチャのglは良くありませんでした。 しかし、CephFSよりもそれを信じており、リリースに備えてシャーディングが行われるのを待っていました。
そして、ここはX日です。
2015年6月4日-Glusterコミュニティは本日、GlusterFS 3.7オープンソフトウェアデファインドストレージソフトウェアの一般提供を発表しました。
3.7-glの最初のバージョン。シャーディングは実験的な機会として発表されました。 彼らは、CephFSが安定してリリースされるほぼ1年前に、表彰台に足を踏み入れました...
したがって、シャーディングは意味します。 glのすべてのものと同様に、スタック上のDHT(トランスレーター)の上にある別のトランスレーター(トランスレーター)に実装されます。 DHTはDHTよりも高いため、DHTは入力で既製のシャードを受け取り、それらを通常のファイルとしてレプリケーショングループに分散します。 シャーディングは個々のボリュームレベルで有効になります。 破片のサイズは、デフォルトで、Cephローションのように4MBに設定できます。
最初のテストを実施したとき、私は喜びました! glが今や一番のものであり、私たちは生きることだとみんなに言いました! シャーディングを有効にすると、1つのファイルの記録が異なるレプリケーショングループと並行して行われます。 「書き込み時」圧縮に続く解凍は、シャードレベルまで増分できます。 ここでキャッシュシューティングが行われると、すべてが正常になり、ファイル全体ではなく個別のシャードがキャッシュに移動されます。 一般的に、私は喜びました、なぜなら 彼は非常にクールなツールを手に入れたようです。
最初のバグ修正と「プロダクションの準備完了」のステータスを待つために残った。 しかし、すべてがそれほどバラ色ではないことが判明しました...シャーディングに関連する重大なバグのリストで記事を広げないために、次のバージョンで時々発生します、私は次の説明で最後の「主要な問題」と言うことができます:
断片化されたGlusterボリュームを拡張すると、ファイルが破損する可能性があります。 通常、シャードボリュームはVMイメージに使用されます。そのようなボリュームが拡張または縮小される場合(つまり、ブリックの追加/削除とリバランス)、VMイメージが破損するというレポートがあります。
2018年1月20日、リリース3.13.2で終了しました...これが最後ではないのでしょうか?
いわば、これに関する私たちの記事の1つについての解説です。
RedHatは、現在のRedHat Gluster Storage 3.4のドキュメントで、サポートしているシャーディングケースはVMディスクのストレージのみであると述べています。
シャーディングには、サポートされているユースケースが1つあります。RedHat Gluster StorageをRed Hat Enterprise Virtualizationのストレージドメインとして提供するコンテキストで、ライブ仮想マシンイメージのストレージを提供します。 シャーディングは、以前の実装よりも大幅にパフォーマンスが向上するため、このユースケースの要件でもあることに注意してください。
なぜこのような制限があるのかはわかりませんが、あなたは認めなければなりません、それは驚くべきことです。
今、私はあなたのためにすべてをここに持っています
どちらのシステムもハッシュ関数を使用して、ディスク全体に擬似ランダムにデータを分散します。
RADOSの場合、次のようになります。
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
Glは、いわゆる整合性ハッシュを使用します。 各ブリックは、「32ビットハッシュスペース内の範囲」を取得します。 つまり、すべてのブリックは、範囲や穴を交差させることなく、線形アドレスハッシュスペース全体を共有します。 クライアントは、ハッシュ関数を使用してファイル名を実行し、受信したハッシュがどのハッシュ範囲に入るかを決定します。 したがって、レンガが選択されます。 レプリケーショングループに複数のブリックがある場合、それらはすべて同じハッシュ範囲を持ちます。 このようなもの:
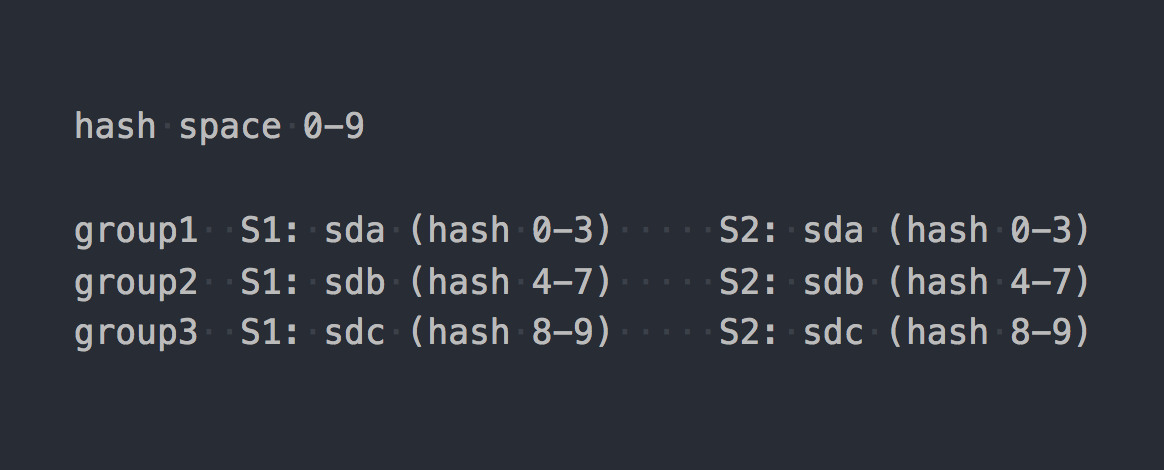
2つのシステムの動作を特定の統一された論理形式にすると、次のようになります。
file -> HASH -> placement_unit
RADOSの場合のplacement_unitはPGであり、glの場合は複数のブリックの複製グループです。
そのため、ハッシュ関数なので、これはファイルを配布、配布し、突然、1つのplacement_unitが他のよりも多く使用されていることがわかります。 これがハッシュ分配システムの基本的な特徴です。 そして、データの不均衡を解消するという非常に一般的なタスクに直面しています。
Glは再構築できますが、上記のハッシュ範囲を使用したアーキテクチャにより、好きなだけ再構築を実行できますが、ハッシュ範囲(およびその結果としてのデータ)は揺れ動きません。 ハッシュ範囲を再配布するための唯一の基準は、ボリューム容量の変更です。 そして、1つのオプションが残っています-レンガを追加します。 また、レプリケーションのあるボリュームについて話している場合は、レプリケーショングループ全体、つまりセットアップに2つの新しいブリックを追加する必要があります。 ボリュームを拡張した後、再構築を開始できます。新しいグループを考慮してハッシュ範囲が再配布され、データが配布されます。 レプリケーショングループが削除されると、ハッシュ範囲が自動的に割り当てられます。
RADOSには可能性があります。 Cephの記事で 、PGの概念について多くの不満を述べましたが、ここでは、もちろんglに比べて、馬に乗ったRADOSを取り上げました。 各OSDには独自の重みがあり、通常はディスクのサイズに基づいて設定されます。 同様に、PGはOSDの重みに応じてOSDによって配布されます。 すべて、OSDの重みを上下に変更するだけで、PGは(データとともに)他のOSDに移動し始めます。 また、各OSDには調整重みが追加されており、1つのサーバーのディスク間でデータのバランスを取ることができます。 これはすべて、クラッシュに固有のものです。 主な利点は、データの不均衡を改善するためにプール容量を拡張する必要がないことです。 また、ディスクをグループに追加する必要はありません。OSDを1つだけ追加でき、PGの一部がそこに転送されます。
はい、プールを作成するときに十分なPGが作成されず、各PGのボリュームが非常に大きくなり、どこに移動しても不均衡が続く可能性があります。 この場合、PGの数を増やすことができ、それらはより小さなものに分割されます。 はい、クラスターがデータでいっぱいの場合、それは痛いですが、私たちの比較の主なことは、そのような機会があるということです。 現在、PGの数の増加のみが許可されており、これにはさらに注意する必要がありますが、Ceph-Nautilusの次のバージョンでは、PGの数の削減(pgマージ)がサポートされます。
データ複製
テストプールとボリュームのレプリケーション係数は2です。興味深いことに、問題のシステムは異なるアプローチを使用してこの数のレプリカを実現しています。
RADOSの場合、記録スキームは次のようになります。
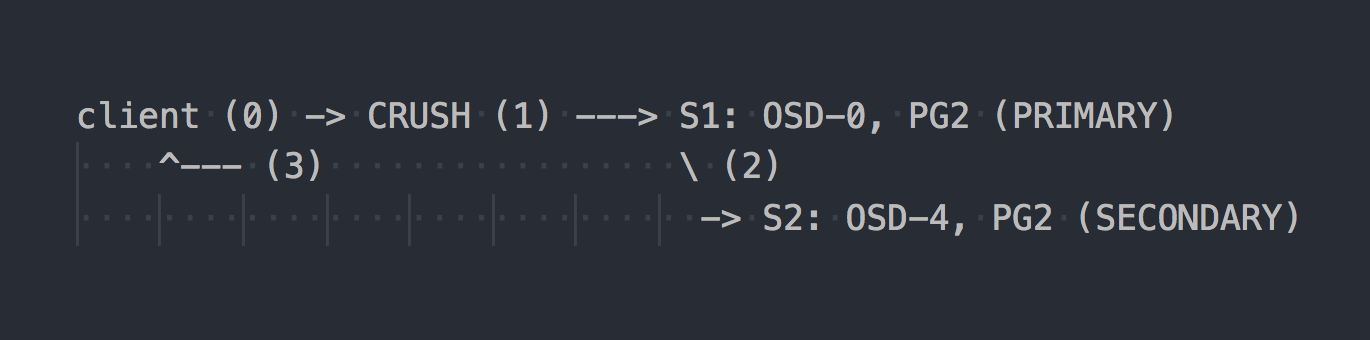
クライアントはクラスター全体のトポロジを認識し、CRUSH(ステップ0)を使用して書き込み用の特定のPGを選択し、OSD-0のPRIMARY PGに書き込み(ステップ1)、その後OSD-0がデータをSECONDARY PGに同期的に複製します(ステップ2)ステップ2の成功/失敗、OSDはクライアントへの操作を確認/確認しません(ステップ3)。 2つのOSD間のデータ複製は、クライアントに対して透過的です。 OSDは通常、データ複製のために別の「クラスター」高速ネットワークを使用できます。
トリプルレプリケーションが構成されている場合、2つのSECONDARYでPRIMARY OSDと同期して実行され、クライアントに対して透過的です...まあ、その許容度が高いだけです。
Glの動作は異なります:
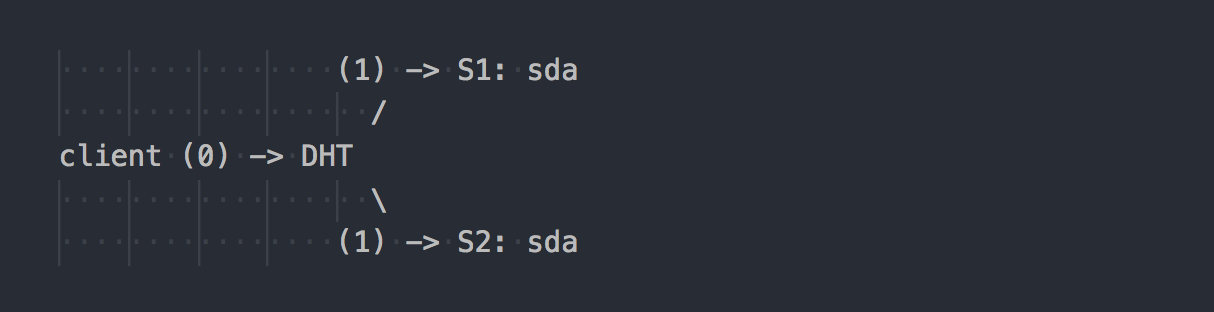
クライアントはボリュームのトポロジを認識し、DHTを使用して(ステップ0)目的のブリックを決定し、書き込みます(ステップ1)。 すべてがシンプルで明確です。 ただし、ここでは、レプリケーショングループ内のすべてのブリックが同じハッシュ範囲を持っていることを思い出してください。 そして、このマイナーな機能は休日全体を作ります。 クライアントは、適切なハッシュ範囲を持つすべてのブリックに並行して書き込みます。
この場合、二重レプリケーションでは、クライアントは2つの異なるブリックで並行してデュアル記録を実行します。 トリプルレプリケーションでは、それぞれトリプルレコーディングが実行され、1MBのデータがクライアントからgl-serverの側へのネットワークトラフィックの約3MBに変わります。 同意して、システムの概念は垂直です。
このようなスキームでは、glクライアントにより多くの作業が割り当てられ、その結果、彼はより多くのCPUを必要とします。ネットワークについてはすでに述べました。
複製は、AFPトランスレーター(自動ファイル複製)によって行われます-同期複製を実行するクライアント側のxlator。 レプリカのすべてのブリックへの書き込みを複製します→トランザクションモデルを使用します。
必要に応じて、グループ内のレプリカを同期(修復)します。たとえば、1つのブリックが一時的に使用できなくなった後、glデーモンは、クライアントに透過的で、参加せずに組み込みAFPを使用してこれを独自に行います。
興味深いことに、ネイティブglクライアントを介さずに、glに組み込まれたNFSサーバーを介して作業を行う場合、RADOSと同じ動作が得られます。 この場合、AFPはglデーモンで使用され、クライアントの介入なしにデータを複製します。 ただし、組み込みNFSはgl v4で保護されています。この動作が必要な場合は、NFS-Ganeshaを使用することをお勧めします。
ところで、NFSとネイティブクライアントを使用するときの動作が非常に異なるため、まったく異なるパフォーマンスインジケーターを見ることができます。
「ひざの上」だけに同じクラスターがありますか?
インターネット上で、あらゆる種類の膝蓋骨セットアップの議論をよく目にします。そこでは、手元にあるものからデータクラスターが構築されます。 この場合、RADOSベースのソリューションにより、ドライブを選択する際の自由度が高まります。 RADOSでは、ほぼすべてのサイズのドライブを追加できます。 各ディスクには(通常)そのサイズに対応する重みがあり、データはその重みにほぼ比例してディスクに分散されます。 glの場合、複製のあるボリュームには「別個のディスク」という概念はありません。 ディスクは、二重複製ではペアで、三重ではトリプルで追加されます。 1つのレプリケーショングループに異なるサイズのディスクがある場合は、グループ内の最小のディスク上の場所で実行され、大きなディスクの容量を展開解除します。 このようなスキームでは、glは、1つのレプリケーショングループの容量が、グループ内の最小のディスクの容量に等しいと仮定します。これは論理的です。 同時に、異なるサイズのディスク(異なるサイズのグループ)で構成されるレプリケーショングループを持つことができます。 より大きなグループは、他のグループに比べてより大きなハッシュ範囲を受け取り、その結果、より多くのデータを受け取ることができます。
5年目はCephと暮らしています。 同じボリュームのディスクから始めましたが、より容量の大きいディスクを導入しました。 Cephを使用すると、アーキテクチャ上の問題を発生させることなく、ディスクを取り外して、より大きなディスクまたはわずかに小さなディスクと交換できます。 glでは、すべてがより複雑になります-2 TBのディスクを取り出しました-同じものを入れてください。 さて、または全体としてグループ全体を撤回することは、あまり良くありませんが、同意します。
フェイルオーバー
すでに2つのソリューションのアーキテクチャに少し精通しているので、それをどのように活用するか、サービスを提供する際の機能について説明することができます。
s1のsdaが拒否されたとします-よくあることです。
glの場合:
- グループに残っているライブディスク上のデータのコピーは、他のグループに自動的に再配布されません。
- ディスクが交換されるまで、データのコピーは1つだけ残ります。
- 故障したディスクを新しいディスクと交換すると、作業ディスクから新しいディスクへのレプリケーションが実行されます(1対1)。
これは、複数のRAID-1でシェルフを提供するようなものです。 はい、トリプルレプリケーションでは、1つのディスクに障害が発生した場合、1つのコピーではなく2つのコピーが残りますが、このアプローチには重大な欠点があります。RADOSの良い例を示します。
S1(OSD-0)でsdaが失敗したとします-一般的なこと:
- OSD-0にあったPGは、10分後に他のOSDに自動的に再マップされます(デフォルト)。 この例では、OSD 1および2にあります。サーバーがさらにある場合は、OSDの数を増やします。
- 2番目に残っているデータのコピーを保存するPGは、復元されたPGが転送されるOSDにそれらの複製を自動的に開始します。 glのような1対1のレプリケーションではなく、多対多のレプリケーションが判明します。
- 破損したディスクではなく、新しいディスクが導入されると、一部のPGはその重みに従って新しいOSDにマップされ、他のOSDからのデータが再配布されます。
RADOSのアーキテクチャ上の利点は意味がないと思います。 ドライブに障害が発生したことを示す手紙を受け取ったとき、けいれんすることはできません。 そして、朝に仕事に来たら、すべての行方不明のコピーがすでに数十の他のOSDに、またはその過程で復元されていることを見つけてください。 数百のPGが多数のディスクに分散している大規模なクラスターでは、数十のOSDが関係する(読み取りおよび書き込み)ため、1つのOSDのデータリカバリは1つのディスクの速度よりもはるかに速い速度で行われます。 さて、負荷分散についても忘れないでください。
スケーリング
この文脈では、おそらく台座glを与えます。 Cephの記事で、PGの概念に関連するRADOSスケーリングの複雑さについて既に書いています。 クラスターの成長に伴うPGの増加が引き続き発生する場合、Ceph MDSについては不明です。 CephFSはRADOSの上で実行され、メタデータと特別なプロセスであるcephメタデータサーバー(MDS)に個別のプールを使用して、ファイルシステムメタデータを処理し、FSとのすべての操作を調整します。 特に、アクティブ/アクティブモードで複数のMDSを実行できるため、MDSがCephFSのスケーラビリティに終止符を打つと言っているわけではありません。 glはアーキテクチャ上、これらすべてを欠いていることに注意したいだけです。 PGに対応するものはなく、MDSのようなものはありません。 Glは、レプリケーショングループを追加するだけで、ほぼ直線的に完全にスケーリングします。
CephFSの前の時代、データペタバイトのソリューションを設計し、glを調べました。 それからglの拡張性について疑問があり、メーリングリストで見つけました。 答えの1つを次に示します(Q:私の質問):
60個のサーバーを使用しています。各サーバーには26x8TBのディスクがあり、合計1560個のディスク16 + 4 ECボリュームと9PBの使用可能なスペースがあります。
Q:クライアント側でlibgfapiまたはFUSEまたはNFSを使用していますか?
私はFUSEを使用しており、ほぼ1000のクライアントがいます。
Q:ボリュームにはいくつのファイルがありますか?
Q:ファイルはもっと大きいですか、小さいですか?
100万を超えるファイルがあり、クラスターの%13が使用されているため、平均ファイルサイズは1 GBになります。
最小/最大ファイルサイズは100MB / 2GBです。 毎日10〜20 TBの新しいデータがボリュームに入ります。
Q:「ls」の動作速度はどれくらいですか?
メタデータの操作は予想どおり遅くなります。 1つのディレクトリに2〜3Kを超えるファイルを置かないようにします。 私のユースケースはバックアップ/アーカイブ用であるため、メタデータ操作はほとんど行いません。
ファイル名を変更する
再びハッシュ関数に戻ります。 特定のファイルが特定のディスクにどのようにルーティングされるかを考えたところ、問題が関連するようになりましたが、ファイルの名前を変更するとどうなりますか?
結局、ファイルの名前を変更すると、その代わりにハッシュも変更されます。これは、別のディスク(異なるハッシュ範囲内)またはRADOSの場合は別のPG / OSD上のこのファイルの場所を意味します。 はい、私たちは正しく考えており、ここでは2つのシステムですべてが再び垂直になっています。
glの場合、ファイルの名前を変更すると、新しい名前がハッシュ関数を介して実行され、新しいブリックが定義され、古いブリックへの特別なリンクが作成されます。 トポフカ、だよね? データが本当に新しい場所に移動し、クライアントが不必要にリンクをクリックしなかったためには、反抗する必要があります。
しかし、RADOSには通常、オブジェクトを後で移動する必要があるという理由だけで、オブジェクトの名前を変更する方法がありません。 オブジェクトの同期移動につながる名前変更には、公正なコピーを使用することが提案されています。 また、RADOSの上で動作するCephFSには、メタデータとMDSを備えたプールの形で切り札があります。 ファイル名を変更しても、データプール内のファイルの内容には影響しません。
レプリケーション2.5
Glには非常に便利な機能が1つあります。これについては別に言及します。 レプリケーション2は信頼できる構成ではないことは誰もが理解していますが、それでも定期的に行われ、正当化されています。 このようなスキームでスプリットブレインから保護し、データの一貫性を確保するために、glを使用してレプリカ2と追加のアービターでボリュームを構築できます。 アービターは、3つ以上の複製に適用できます。 これは他の2つと同じグループ内のブリックであり、実際にはファイルとディレクトリからファイル構造のみを作成します。 このようなブリック上のファイルのサイズはゼロですが、ファイルシステムの拡張属性(拡張属性)は、同じレプリカ内のフルサイズファイルと同期状態で維持されます。 その考えは明確だと思います。 これは素晴らしい機会だと思います。
唯一の瞬間...レプリケーショングループ内の場所のサイズは、最小ブリックのサイズによって決定されます。これは、アービターが少なくともグループ内の残りと同じサイズのディスクをスリップする必要があることを意味します。 これを行うには、実際のディスクを使用しないように、薄い(薄い)LVダミーの大きなサイズを作成することをお勧めします。
そして、顧客はどうですか?
2つのシステムのネイティブAPIは、libgfapi(gl)およびlibcephfs(CephFS)ライブラリの形式で実装されます。 人気のある言語のバインディングも利用できます。 一般に、ライブラリーでは、すべてがほぼ同等に優れています。 ユビキタスNFS-Ganeshaは、両方のライブラリをFSALとしてサポートしていますが、これも標準です。 Qemuはlibgfapiを介してネイティブgl APIもサポートします。
ただし、fio(Flexible I / O Tester)は長くて、正常にlibgfapiをサポートしていますが、libcephfsはサポートしていません。 これはプラスのglです、なぜなら glを直接テストするには、fioを使用するのが本当に便利です。 libgfapiを介してユーザー空間から作業する場合にのみ、glからglのすべてを取得できます。
しかし、POSIXファイルシステムとそのマウント方法について話している場合、glはFUSEクライアントとアップストリームカーネルのCephFS実装のみを提供できます。 カーネルモジュールでは、FUSEがより優れたパフォーマンスを示すほどの空想を作成できることは明らかです。 ただし、実際には、FUSEは常にコンテキストスイッチングのオーバーヘッドです。 私は、FUSEがどのようにデュアルソケットサーバーをCSだけで曲げるかを個人的に何度も見てきました。
どういうわけかライナスは言った:
ユーザースペースファイルシステム? 問題はまさにそこにあります。 常にされています。 ユーザースペースのファイルシステムは、おもちゃ以外のものに対して現実的であると考える人々は、見当違いです。
反対に、GL開発者はFUSEはクールだと考えています。 これにより、柔軟性が向上し、カーネルバージョンから切り離されます。 私の場合、glは速度に関するものではないため、FUSEを使用します。 どういうわけか、それは書かれています-まあ、それは正常であり、カーネルの実装に悩まされるのは本当に奇妙です。
性能
比較はありません)。
これは複雑すぎます。 同一のセットアップであっても、客観的なテストを実施するのは非常に困難です。 とにかく、コメントの中で、システムの1つを「高速化」し、テストがでたらめだと言う100500のパラメータを与える人がいるでしょう。 したがって、興味がある場合は、自分でテストしてください。
おわりに
特に、RADOSとCephFSは、理解、構成、およびメンテナンスの両方において、より複雑なソリューションです。
しかし、個人的には、RADOSのアーキテクチャが好きで、GlusterFSよりもCephFSの上で実行されます。 より多くのハンドル(PG、OSDの重み、クラッシュ階層など)、CephFSメタデータは複雑さを増しますが、柔軟性を高め、このソリューションをより効率的にします。
Cephは現在のSDS基準にはるかに適しており、より有望であるように思えます。 しかし、これは私の意見です、あなたはどう思いますか?