私の
以前の記事が好きな人のために、私はイナゴのストレステストツールの印象を共有し続けています。
テスト用のデータを簡単に準備して結果を処理できるコードを使用して、負荷テストpythonを作成する利点を明確に示すようにします。
サーバー応答処理
負荷テストでは、HTTPサーバーから200 OKを取得するだけでは不十分な場合があります。 応答の内容を確認して、負荷がかかったときにサーバーが正しいデータを発行したり、正確な計算を実行したりすることを確認する必要が生じることがあります。 そのような場合にのみ、Locustはサーバー応答成功パラメーターをオーバーライドする機能を追加しました。 次の例を考えてみましょう。
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
次のシナリオで負荷を作成するリクエストは1つのみです。
サーバーから、1から5000の範囲のランダムIDを持つ写真オブジェクトを要求し、10の倍数にできないと仮定して、このオブジェクトのアルバムIDを確認します
ここで、すぐにいくつかの説明をすることができます。
- 応答としてrequest()を使用した素晴らしい構造: response = request()で正常に置き換えることができ、応答オブジェクトを静かに操作できます
- 間違っていない場合、URLはpython 3.6で追加された文字列形式の構文を使用して形成されます-f '/ photos / {photo_id}' 。 以前のバージョンでは、この設計は機能しません!
- 以前に使用したことのない新しい引数catch_response = Trueは、サーバー応答の成功を判断することをLocustに伝えます。 指定しない場合、同じ方法で応答オブジェクトを受け取り、そのデータを処理できますが、結果を再定義することはできません。 以下に詳細な例を示します。
- 別の引数名= '/ photos / [id]' 統計でリクエストをグループ化する必要があります。 名前には任意のテキストを使用できますが、URLを繰り返す必要はありません。 これがないと、一意のアドレスまたはパラメータを持つ各リクエストが個別に記録されます。 仕組みは次のとおりです。
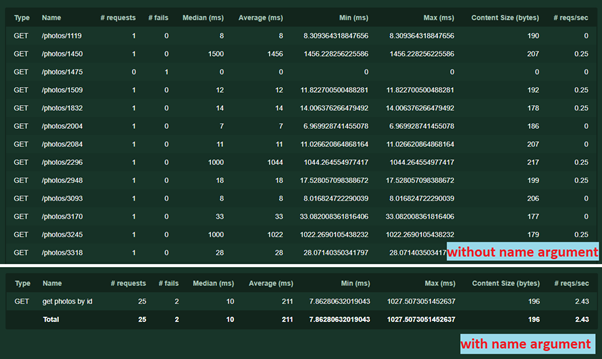
同じ引数を使用して、別のトリックを実行できます。異なるパラメーター(たとえば、POST要求の異なるコンテンツ)を持つ1つのサービスが異なるロジックを実行することがあります。 テスト結果が混同しないように、独自の引数
名ごとに指定して、いくつかの個別のタスクを作成できます。
次に、チェックを行います。 2つあります。最初に、
response.status_code == 200の場合、サーバーが
応答を返したことを確認します。
ある場合は、アルバムのIDが10の倍数であるかどうかを確認します。倍数でない場合は、この回答を成功の
応答としてマークします
。success()その他の場合、応答が
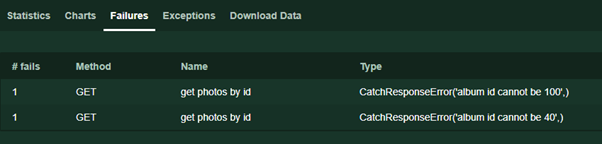
response.failure( 'error text')で失敗した理由を示し
ます 。 このテキストは、テスト中に[失敗]ページに表示されます。
また、熱心な読者は、ネットワークインターフェイスで機能するコードの特徴である例外が存在しないことに気付く可能性があります。 実際、タイムアウト、接続エラー、およびその他の予期しないインシデントの場合、Locustはエラーを処理し、応答を返しますが、応答コードのステータスが0であることを示します。
それでもコードが例外をスローする場合は、実行時に例外タブに書き込まれ、処理できるようになります。 最も典型的な状況は、答えのjson'eが探していた値を返さなかったということですが、すでに次の操作を実行しています。
トピックを閉じる前に-この例では、応答を処理する方が簡単なので、わかりやすくするためにjsonサーバーを使用しています。 ただし、HTTPベースのプロトコルで使用されるHTML、XML、FormData、添付ファイル、およびその他のデータを使用して同じ成功を収めることができます。
複雑なシナリオで作業する
Webアプリケーションの負荷テストを行うことがタスクのほぼすべてであるため、データを返すだけのGETサービスだけで適切なカバレッジを提供することは不可能であることがすぐに明らかになります。
古典的な例:オンラインストアをテストするには、ユーザーが
- 本店を開いた
- 商品を探していました
- 開いたアイテムの詳細
- カートにアイテムを追加しました
- 有料
この例から、ランダムな順序でのサービスの呼び出しは機能せず、順番にしか機能しないと想定できます。 さらに、商品、バスケット、支払い方法には、ユーザーごとに一意の識別子が付いている場合があります。
前の例を少し修正することで、このようなシナリオのテストを簡単に実装できます。 サンプルをテストサーバーに適合させます。
- ユーザーが新しい投稿を書いています。
- ユーザーが新しい投稿にコメントを書く
- ユーザーがコメントを読む
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
この例では、新しい
FlowExceptionクラスを追加しました。 各ステップの後、期待どおりに行かなかった場合、この例外クラスをスローしてスクリプトを中断します-投稿が機能しなかった場合、コメントするものはありませんなど 必要に応じて、構造を通常の
returnに置き換えることができますが、この場合、結果の実行および分析中に、実行されたスクリプトが[例外]タブに表示されるステップでそれほど明確に表示されません。 同じ理由で、構文
を除いて
try ...を使用しません。
負荷を現実的にする
今、私は非難することができます-ストアの場合、すべては本当に線形ですが、投稿とコメントの例はあまりにも遠いです-彼らは作成するよりも10倍頻繁に投稿を読みます。 合理的に、この例をさらに実行可能にしましょう。 そして、少なくとも2つのアプローチがあります。
- このような可能性があり、バックエンドの機能が特定の投稿に依存しない場合、ユーザーが読む投稿のリストを「ハードコード化」し、テストコードを簡素化できます
- 作成された投稿を保存し、投稿のリストを事前設定できない場合、または実際の負荷が読み込まれる投稿に依存する場合はそれらを読みます(コードをより小さくより視覚的にするために、例からコメントの作成を削除しました)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
UserBehaviorクラス
では、
created_postsリストを作成しました。 特に注意してください-これはオブジェクトであり、
__init __()クラスのコンストラクタで作成されたものではないため、クライアントセッションとは異なり、このリストはすべてのユーザーに共通です。 最初のタスクは投稿を作成し、そのIDをリストに書き込みます。 2番目のものは、リストからランダムに選択された1つの投稿を読む可能性が10倍高くなります。 2番目のタスクの追加条件は、作成された投稿があるかどうかを確認することです。
各ユーザーが自分のデータでのみ操作するようにしたい場合は、コンストラクターで次のように宣言できます。
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
その他の機能
タスクの順次起動の場合、公式ドキュメントでは、引数にタスクシリアル番号を指定して@seq_task(1)タスクアノテーションも使用することを推奨しています
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
この例では、各ユーザーはまず
first_taskを実行し、次に
second_taskを実行し、次に
third_taskを10回
実行します。
率直に言って、このような機会を利用できることは喜ばしいことですが、前の例とは異なり、必要に応じて最初のタスクの結果を2番目のタスクに転送する方法は明確ではありません。
また、特に複雑なシナリオの場合、ネストされたタスクセットを作成することができます。本質的には、複数のTaskSetクラスを作成し、相互に接続します。
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
上記の例では、1から6の確率で
Todoスクリプトが起動され、1から4の確率で
UserBehaviorスクリプトに戻るまで実行されます。 ここでは
self.interrupt()呼び出しの存在が非常に重要
です 。これがないと、テストはサブタスクにループします。
読んでくれてありがとう。 最後の記事では、UIを使用しない分散テストとテスト、およびLocustでのテスト中に発生した問題とそれらの回避方法について説明します。