プログラミング言語のエラーを処理するには、さまざまな方法があります。
- 多くの言語(Java、Scalaおよびその他のJVM、Python、および他の多く)の標準例外
- ステータスコードまたはフラグ(Go、bash)
- さまざまな代数データ構造。その値は、成功した結果とエラーの説明(Scala、haskell、およびその他の関数型言語)の両方になります。
例外は非常に広く使用されていますが、一方で、それらはしばしば遅いと言われています。 しかし、機能的アプローチの反対者はしばしばパフォーマンスに訴えます。
最近、Scalaで作業しており、エラー処理に例外とさまざまなデータ型の両方を等しく使用できるので、どちらのアプローチがより便利で高速になるのだろうかと思います。
このアプローチはJVM言語では受け入れられず、私の意見ではエラーが発生しやすいため、コードとフラグの使用はすぐに破棄します(私はしゃれをおaびします)。 したがって、例外と異なるタイプのADTを比較します。 さらに、ADTは、機能的なスタイルでのエラーコードの使用と見なすことができます。
更新 :スタックトレースのない例外が比較に追加されます
出場者
代数データ型についてもう少しADT( ADT )にあまり精通していない人のために-代数型はいくつかの可能な値で構成され、それぞれが複合値(構造、レコード)になります。
例は、タイプOption[T] = Some(value: T) | None nullの代わりに使用されるOption[T] = Some(value: T) | None :このタイプの値は、値がある場合はSome(t) 、値がない場合はNoneなります。
別の例は、 Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) 。正常に完了したか、エラーが発生した可能性のある計算の結果を示します。
参加者は:
- 古き良き例外
- スタックトレースの入力は非常に遅い操作であるため、スタックトレースなしの例外
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) -同じ例外ですが、機能ラッパーですEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) -結果またはエラーの説明を含む型ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - Catsライブラリのタイプ。エラーの場合、さまざまなエラーに関する複数のメッセージを含めることができます( List完全にList使用されませんが、重要ではありません)
本質的に、例外はATDなしのスタックトレースと比較されますが、Scalaには単一のアプローチがなく、いくつかを比較するのが興味深いため、いくつかのタイプが選択されています。
例外に加えて、文字列はエラーを説明するために使用されますが、実際の状況で同じ成功を収めると、異なるクラスが使用されます( Either[Failure, T] )。
問題
エラー処理のテストでは、解析とデータ検証の問題を取り上げます。
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
つまり 生データMap[String, String]持っている場合、データが有効でない場合はPersonまたはエラーを取得する必要があります。
投げる
例外を使用した額の解決策(以下ではperson関数のみを提供します。完全なコードはgithubで確認できます):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
ここで、 string 、 integer 、およびbooleanは、単純型の存在と形式を検証し、変換を実行します。
一般的に、それは非常にシンプルで理解しやすいものです。
ThrowNST(スタックトレースなし)
コードは前のケースと同じですが、可能な場合はスタックトレースなしで例外が使用されます: ThrowNSTParser.scala
試して
このソリューションは、例外を早期にキャッチしforを介して結果を組み合わせることができます(他の言語のループと混同しないでください)。
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
壊れやすい目ではもう少し珍しいですが、forの使用により、例外を除いてバージョンと非常によく似ており、さらに、フィールドの存在の検証と目的のタイプの解析が別々に行われます( flatMapは次のように読むことができます)
どちらか
ここでは、エラータイプが修正されているため、 EitherタイプはResultエイリアスの後ろに隠れています。
いずれかのParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
Tryような標準のEitherがScalaでモナドを形成するため、コードはまったく同じになりました。ここでの違いは、文字列がエラーとしてここに表示され、例外が最小限使用されることです(数値を解析するときにエラーを処理するためのみ)
検証済み
ここでは、最初に発生したものではなく、可能な限り多くを取得するためにCatsライブラリが使用されます(たとえば、いくつかのフィールドが無効である場合、結果にはこれらすべてのフィールドの解析エラーが含まれます)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
このコードはすでに例外を除いて元のバージョンとあまり似ていませんが、追加の制限の検証はフィールドの解析とは異なり、1つではなくいくつかのエラーが発生します。
テスト中
テストのために、異なる割合のエラーでデータセットが生成され、それぞれの方法で解析されました。
エラーのすべての割合の結果:

より詳細には、エラーの割合が低い(より大きなサンプルが使用されているため、ここでは時間が異なります):
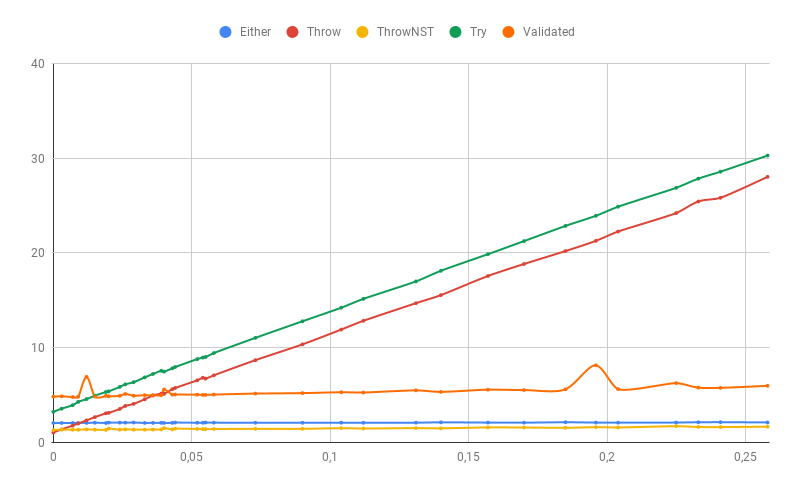
エラーの一部が依然としてスタックトレースの例外である場合(この場合、数値の解析エラーは制御できない例外になります)、「高速」エラー処理メソッドのパフォーマンスは大幅に低下します。 Validatedすべてのエラーを収集し、その結果、他よりも遅い例外を受け取るため、特に影響を受けます。

結論
実験が示したように、スタックトレースの例外は実際には非常に遅い(100%エラーはThrowとEither 50倍以上の差です!)そして、例外がほとんどない場合、ADTの使用には代償があります。 ただし、スタックトレースなしで例外を使用すると、ADTと同じくらい速く(エラーの割合が低くなります)、そのような例外が同じ検証を超えると、ソースの追跡が容易になりません。
合計、除外の確率が1%を超える場合、スタックトレースのない例外が最も速く動作し、 Validatedまたは通常のEitherほぼ同じ速度で動作します。 多数のエラーがある場合、Fail-fastセマンティクスのために、 EitherもValidatedよりも少し速くなる可能性があります。
エラー処理にADTを使用すると、例外よりも別の利点があります。エラーの可能性は型自体に結び付けられ、nullの代わりにOptionを使用する場合のように見逃しにくくなります。