こんにちは同僚!

発信年の最後の出版物で、私たちはすでに
本を翻訳しているトピックである強化学習について言及したかった。
自分で判断してください。Mediumの初歩的な記事があり、問題のコンテキストを概説し、Pythonでの実装を伴う最も単純なアルゴリズムについて説明しました。 この記事にはいくつかのgifがあります。 そして、モチベーション、報酬、成功への道の正しい戦略の選択は、来年に私たち一人一人にとって非常に役立つものです。
素敵な読書を!
強化学習は、エージェントが環境で行動することを学習し、アクションを実行し、それによって直感を開発するタイプの機械学習です。その後、彼はアクションの結果を観察します。 この記事では、強化による学習の問題を理解して定式化し、それをPythonで解決する方法を説明します。
最近、コンピューターが人間と対戦するという事実に慣れてきました-マルチプレイヤーゲームのボットとして、または一対一のゲームのライバルとして:たとえば、Dota2、PUB-G、マリオ。 2016年に2016年のAlphaGoプログラムが韓国のチャンピオンを破ったとき、調査会社の
Deepmindはニュースについて
大騒ぎした。 あなたが熱心なゲーマーなら、Dota 2 OpenAI Fiveの5つの試合について聞くことができます。そこでは、車が人と戦って、いくつかの試合でDota2の最高の選手を破りました。 (詳細に興味がある場合は、
ここでアルゴリズムを詳細に分析し、マシンがどのように再生されるかを調べます)。

OpenAI Fiveの最新バージョン
はRoshanを採用しています。
それでは、中心的な質問から始めましょう。 強化されたトレーニングが必要な理由 それはゲームでのみ使用されますか、または適用された問題を解決するための現実的なシナリオに適用できますか? これが初めて強化トレーニングを読む場合、これらの質問に対する答えを想像することはできません。 実際、強化学習は、人工知能の分野で最も広く使用され、急速に発展している技術の1つです。
強化学習システムが特に求められている分野は次のとおりです。
- 無人車両
- ゲーム産業
- ロボティクス
- レコメンダーシステム
- 広告とマーケティング
強化学習の概要と背景では、機械学習とディープラーニングの方法を自由に使えるようになったとき、強化を伴う学習現象はどのように形になったのでしょうか? 「彼はリッチサットンとリッチ博士の研究監督者であるアンドリューバートによって発明され、博士号の準備を支援しました。」 パラダイムは1980年代に最初に形になり、その後古風なものになりました。 その後、リッチは自分には素晴らしい未来があり、最終的には認められると信じていました。
強化された学習は、デプロイされた環境での自動化をサポートします。 機械学習とディープラーニングはどちらもほぼ同じ方法で動作します。戦略的に異なる配置になっていますが、どちらのパラダイムも自動化をサポートしています。 それでは、なぜ強化訓練が行われたのですか?
それは自然な学習プロセスを非常に連想させ、プロセス/モデルが行動し、彼女がどのようにタスクに対処するかについてのフィードバックを受け取ります:良いかどうか。
機械学習とディープラーニングもトレーニングオプションですが、利用可能なデータのパターンを特定するように調整されています。 一方、強化学習では、そのような経験は試行錯誤を通して得られます。 システムは徐々に適切なオプションまたはグローバル最適を見つけます。 強化された学習の重大な追加の利点は、この場合、教師による指導の場合のように、広範なトレーニングデータのセットを提供する必要がないことです。 いくつかの小さな断片で十分です。
強化学習の概念猫に新しいトリックを教えることを想像してください。 しかし、残念なことに、猫は人間の言語を理解していないので、あなたは彼らと一緒に遊んでいるものを取り上げて伝えることはできません。 したがって、あなたは異なった行動をします。状況を真似すると、猫は何らかの形で応答しようとします。 猫があなたが望むように反応した場合、あなたはそれにミルクを注ぎます。 次に何が起こるか理解していますか? 繰り返しますが、同様の状況で、猫は再び望みのアクションを実行し、さらに熱意を込めて、より良い給餌が期待されます。 これは、ポジティブな例で学習が行われる方法です。 しかし、ネガティブなインセンティブを持つ猫を「教育」しようとすると、たとえば、厳密に見て、眉をひそめた場合、そのような状況では通常学習しません。
強化学習も同様に機能します。 マシンに入力とアクションを伝え、出力に応じてマシンに報酬を与えます。 私たちの究極の目標は、報酬を最大化することです。 次に、強化学習の観点から上記の問題を再定式化する方法を見てみましょう。
- 猫は「環境」にさらされる「エージェント」として機能します。
- 環境は、あなたが猫に教えているものに応じて、家庭または遊び場です。
- トレーニングから生じる状況は「状態」と呼ばれます。 猫の場合、条件の例は、猫が「ベッドの下を走る」または「 "う」ときです。
- エージェントは、アクションを実行し、ある「状態」から別の「状態」に移動することで反応します。
- 状態が変更された後、エージェントは実行したアクションに応じて「報酬」または「罰金」を受け取ります。
- 「戦略」は、最良の結果を得るためのアクションを選択するための方法論です。
強化学習とは何かを理解したので、強化学習と深層強化学習の起源と進化について詳しく説明し、このパラダイムがどのように教師なしでも学習できない問題を解決できるかを議論し、次のことに注意してください奇妙な事実:現在、Googleの検索エンジンは強化学習アルゴリズムを使用して最適化されています。
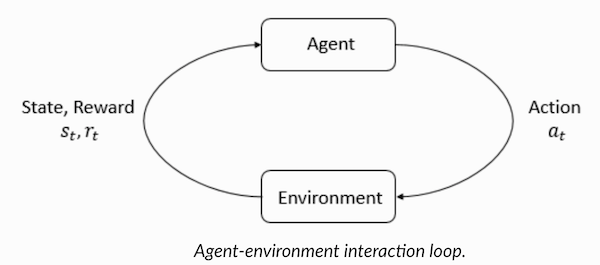
強化学習の用語を理解するエージェントと環境は、強化学習アルゴリズムで重要な役割を果たします。 環境は、エージェントが生き残らなければならない世界です。 さらに、エージェントは環境(報酬)から強化信号を受け取ります。これは、世界の現在の状態がどれだけ良いか悪いかを説明する数値です。 エージェントの目的は、総報酬、いわゆる「ゲイン」を最大化することです。 最初の強化学習アルゴリズムを作成する前に、次の用語を理解する必要があります。

- 状態:状態は、この世界を特徴付ける情報の単一の断片が欠落していない世界の完全な記述です。 固定または動的の位置が可能です。 原則として、そのような状態は、高次の配列、行列、またはテンソルの形式で記述されます。
- アクション :通常、アクションは環境条件に依存し、異なる環境ではエージェントが異なるアクションを実行します。 多くの有効なエージェントアクションは、「アクションスペース」と呼ばれるスペースに記録されます。 通常、空間内のアクションの数は有限です。
- 環境 :これは、エージェントが存在し、エージェントと対話する場所です。 さまざまな種類の報酬、戦略などがさまざまな環境に使用されます。
- 報酬と賞金 :強化でトレーニングする場合、報酬関数Rを常に監視する必要があります。 アルゴリズムを設定し、最適化するとき、そして学習をやめるときも重要です。 それは、世界の現在の状態、今とった行動、そして次の世界の状態に依存します。
- 戦略 :戦略は、エージェントが次のアクションを選択するルールです。 戦略のセットは、エージェントの「頭脳」とも呼ばれます。
強化学習の用語に精通したので、適切なアルゴリズムを使用して問題を解決しましょう。 この前に、このような問題を定式化する方法を理解する必要があり、この問題を解決するときは、強化を伴うトレーニングの用語に依存します。
タクシーソリューションそこで、強化アルゴリズムを使用して問題を解決します。
無人タクシー用のトレーニングゾーンがあり、4つの異なるポイント(
R,G,Y,B )で駐車場に乗客を引き渡すためにトレーニングゾーンがあるとします。 その前に、Pythonでプログラミングを開始する環境を理解して設定する必要があります。 Pythonを学習し始めたばかりの場合は、
この記事をお勧め
します 。
タクシーの問題を解決するための環境は、OpenAIの
Gymを使用して構成できます。これは、強化トレーニングの問題を解決するための最も一般的なライブラリの1つです。 ジムを使用する前に、マシンにインストールする必要があります。これには、pipというPythonパッケージマネージャーが便利です。 以下はインストールコマンドです。
pip install gym次に、環境がどのように表示されるかを見てみましょう。 このタスクのすべてのモデルとインターフェースは既にgymで構成されており、
Taxi-V2下に名前が付けられています。 以下のコードスニペットは、この環境を表示するために使用されます。
「4つの場所があります(異なる文字で示されています)。 私たちの仕事は、ある地点で乗客を迎え、別の地点で降ろすことです。 乗客の降車に成功すると+20ポイントを獲得し、それに費やしたステップごとに1ポイントを失います。 また、意図しない乗客の搭乗および降車ごとに10ポイントのペナルティがあります。」(出典:
gym.openai.com/envs/Taxi-v2 )
コンソールに表示される出力は次のとおりです。

タクシーV2 ENV
素晴らしい、
envはOpenAi Gymの心臓部であり、統合された環境インターフェースです。 以下は、役に立つと思われるenvメソッドです。
env.reset :環境をリセットし、ランダムな初期状態を返します。
env.step(action) :環境
env.step(action)開発を1ステップ進めます。
env.step(action) :次の変数を返します
observation :環境の観察。reward :あなたの行動が有益であったかどうかをrewardます。done :「1エピソード」とも呼ばれる、乗客を適切に乗降させたかどうかを示します。info :デバッグ目的に必要なパフォーマンスや遅延などの追加情報。env.render :環境の1フレームを表示します(レンダリングに役立ちます)
それでは、環境を調べて、問題をよりよく理解してみましょう。 タクシーはこの駐車場で唯一の車です。 駐車場は
5x5グリッドに分割でき、25のタクシーの場所を取得できます。 これらの25個の値は、状態空間の要素の1つです。 注:現時点では、タクシーは座標(3、1)の地点にあります。
乗客が搭乗できる環境には4つのポイントがあります:
R, G, Y, Bまたは
[(0,0), (0,4), (4,0), (4,3)]座標(水平、垂直)、上記の環境をデカルト座標で解釈できる場合。 タクシー内で乗客の状態をもう1つ考慮する場合は、タクシーの訓練のために環境内の州の総数を計算するために、乗客の場所と目的地のすべての組み合わせを取得できます。4つの目的地と5つの(4+ 1)乗客の場所。
したがって、タクシーの環境では、5×5×5×4 = 500の可能な状態があります。 エージェントは500の条件のいずれかを処理し、アクションを実行します。 私たちの場合、選択肢は次のとおりです。1つの方向または別の方向に移動するか、乗客を乗降させる決定です。 つまり、次の6つの可能なアクションを自由に使用できます。
ピックアップ、ドロップ、北、東、南、西(最後の4つの値は、タクシーが移動できる方向です)
これは
action spaceです。エージェントが特定の状態で実行できるすべてのアクションのセットです。
上の図から明らかなように、タクシーは状況によっては特定のアクションを実行できません(壁が干渉します)。 環境を記述するコードでは、壁のヒットごとに-1のペナルティを割り当て、タクシーが壁に衝突します。 したがって、そのような罰金は累積するので、タクシーは壁にぶつからないようにします。
報酬表:タクシー環境を作成するときに、Pと呼ばれるプライマリ報酬表も作成できます。これは、状態の数が行の数に対応し、アクションの数が列の数に対応するマトリックスと考えることができます。 つまり、
states × actionsマトリックスについて話して
states × actionsです。
絶対にすべての条件がこのマトリックスに記録されているため、説明するために選択した州に割り当てられた報酬のデフォルト値を表示できます。
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
この辞書の構造は次のとおりです:
{action: [(probability, nextstate, reward, done)]} 。
- 値0〜5は、図に示す現在の状態でタクシーが実行できるアクション(南、北、東、西、ピックアップ、ドロップオフ)に対応しています。
- doneを使用すると、目的の地点で乗客を降ろしたときに判断できます。
強化トレーニングなしでこの問題を解決するには、ターゲット状態を設定し、スペースを選択してから、何度も繰り返してターゲット状態に到達できる場合、この瞬間が最大報酬に対応すると仮定します。 他の州では、プログラムが正しく機能する(目標に近づく)場合、報酬の価値は最大に近づくか、ミスを犯した場合、罰金を累積します。 さらに、罰金の値は-10に達することができます。
強化トレーニングなしでこの問題を解決するコードを書きましょう。
各州のデフォルトの報酬値を持つPテーブルがあるので、このテーブルに基づいてタクシーのナビゲーションを整理することができます。
乗客が目的地(1エピソード)に到達するまで、つまり、報酬率が20に到達するまでスクロールする、無限ループを作成します
env.action_space.sample()メソッドは、使用可能なすべてのアクションのセットからランダムアクションを自動的に選択します。 。 何が起こるか考えてください:
import gym from time import sleep
結論:
クレジット:OpenAI
問題は解決されていますが、最適化されていません。または、このアルゴリズムはすべての場合に機能しません。 問題を解決するためにマシン/アルゴリズムによって費やされる反復の数が最小限に抑えられるように、適切な相互作用エージェントが必要です。 ここでは、Q学習アルゴリズムが役立ちます。その実装については、次のセクションで検討します。
Qラーニングの紹介以下は、最も人気があり、最も単純な強化学習アルゴリズムの1つです。 環境は、段階的なトレーニングと、特定の状態で彼が最も最適なステップを踏むという事実に対してエージェントに報酬を与えます。 上記の実装では、エージェントが学習する報酬テーブル「P」がありました。 報酬テーブルに基づいて、彼はそれがどれほど有用かによって次のアクションを選択し、Q値と呼ばれる別の値を更新します。 その結果、Qテーブルと呼ばれる新しいテーブルが作成され、組み合わせ(ステータス、アクション)に表示されます。 Q値が優れている場合、より最適化された報酬が得られます。
たとえば、タクシーが乗客がタクシーと同じ地点にいる状態にある場合、「ピックアップ」アクションのQ値は、「乗客を降ろす」や「北へ行く」などの他のアクションよりも高い可能性が非常に高い「。
Q値はランダムな値で初期化され、エージェントが環境と対話し、特定のアクションを実行することでさまざまな報酬を受け取ると、Q値は次の式に従って更新されます。

これにより、Q値を初期化する方法とそれらを計算する方法が問題になります。 アクションが進むと、この方程式でQ値が実行されます。
ここで、AlphaとGammaはQ学習アルゴリズムのパラメーターです。 アルファは学習のペースであり、ガンマは割引率です。 両方の値の範囲は0〜1であり、1に等しい場合もあります。 更新中の損失の値を補正する必要があるため、ガンマはゼロにすることができますが、アルファはできません(学習率は正です)。 ここでのアルファ値は、先生に教えるときと同じです。 ガンマは、将来私たちを待っている報酬を与えることの重要性を決定します。
このアルゴリズムの概要は次のとおりです。
- ステップ1:Qテーブルを初期化し、ゼロで埋め、Q値に対して任意の定数を設定します。
- ステップ2:次に、エージェントが環境に応答し、さまざまなアクションを試すようにします。 状態の変更ごとに、この状態(S)で可能なすべてのアクションの1つを選択します。
- ステップ3:前のアクション(a)の結果に基づいて、次の状態(S ')に進みます。
- ステップ4:状態(S ')から可能なすべてのアクションについて、Q値が最も高いアクションを選択します。
- ステップ5:上記の式に従ってQテーブル値を更新します。
- ステップ6:次の状態を現在の状態にします。
- ステップ7:ターゲット状態に達した場合、プロセスを完了してから繰り返します。
Python Q学習 import gym import numpy as np import random from IPython.display import clear_output
これで、すべての値が
q_table変数に保存されます。
そのため、モデルは環境条件で訓練され、乗客をより正確に選択する方法がわかりました。 そして、強化学習の現象に精通し、アルゴリズムをプログラムして新しい問題を解決できます。
その他の強化学習テクニック:
- マルコフ意思決定プロセス(MDP)とベルマン方程式
- 動的プログラミング:モデルベースのRL、戦略の反復、および値の反復
- ディープQトレーニング
- 戦略勾配降下法
- サルサ
この演習のコードは次の場所にあります。
vihar / python-reinforcement-learning