こんにちは 私はディマです。私はかなり長い間Pythonに座っています。 今日は、2つの非同期フレームワークTornadoとAiohttpの違いを紹介します。 プロジェクトのフレームワーク間の選択の話、TornadoとAsyncIOのコルーチンがどのように異なるか、ベンチマークを示し、フレームワークの荒野に出てそこからうまく抜け出す方法に関するいくつかの有用なヒントを示します。

ご存知のように、Avitoはかなり大きな広告サービスです。 大量のデータと負荷があり、毎月3,500万人のユーザーと毎日4,500万のアクティブな広告があります。 私は、レコメンデーション開発グループのテクニカルアドバイザーとして働いています。 私のチームはマイクロサービスを書いていますが、今では約20人が働いています。 5k RPSのように、このすべてに負荷がかかっています。
非同期フレームワークの選択
まず、私たちが今いる場所にどのようになったかを説明します。 2015年には、非同期フレームワークを選択する必要がありました。
- 他のマイクロサービス:http、json、rpcに対して多くのリクエストを行う必要があること。
- Redis、Postgres、MongoDBなど、さまざまなソースから常にデータを収集する必要があること。
したがって、私たちには多くのネットワークタスクがあり、アプリケーションは主に入出力で占められています。 当時のPythonの現在のバージョンは3.4で、asyncとawaitはまだ表示されていませんでした。 Aiohttpも-バージョン0.xでした。 FacebookのAsynchronous Tornadoは2010年に登場しました。 彼に必要な多くのデータベースドライバーが書かれています。 竜巻は、ベンチマークで安定した結果を示しました。 次に、このフレームワークでの選択を停止しました。
3年後、私たちは多くを理解しました。
最初に、Python 3.5はasync / awaitメカニズムを備えています。 yieldとyield fromの違いは何か、Tornadoとawait(ネタバレ:あまり良くない)との一貫性を理解しました。
第二に、CPUが完全に占有されていない場合でも、スケジューラで大量のコルーチンを使用することで、奇妙なパフォーマンスの問題が発生しました。
第三に、他のTornadoサービスに対して多数のhttpリクエストを実行する場合、非同期DNSリゾルバーと特に友達である必要があることがわかりました。接続を確立し、指定したリクエストを送信するためのタイムアウトを尊重しません。 そして一般的に、Tornadoでhttpリクエストを行う最良の方法はcurlです。これはそれ自体がかなり奇妙です。
Andrei Svetlov氏は
、PyCon Russia 2018でのプレゼンテーションで次のように述べています。「何らかの種類の非同期Webアプリケーションを作成したい場合は、非同期で作成してください。お待ちください。 イベントループは、おそらく、すぐにはまったく必要ないでしょう。 混乱しないように、フレームワークのジャングルに登らないでください。 低レベルのプリミティブを使用しないでください。すべてうまくいきます...」 過去3年間、残念ながら、トルネードの内部を頻繁にクロールし、そこから多くの興味深いことを学び、30-40コールの巨大なトレースバックを見る必要がありました。
収量対収量
非同期pythonで理解する最大の問題の1つは、yield fromとyieldの違いです。
Guido Van Rossumがこれについて詳しく
書いています。 翻訳をわずかな略語で囲みます。
私は、PEP 3156がyieldの代わりにyield-fromを使用することを主張する理由を何度か尋ねられました。
(...)
将来の結果が必要な場合は常にyieldを使用します。
これは次のように実装されます。 yieldを含む関数は(明らかに)ジェネレーターなので、何らかの反復コードが必要です。 彼をプランナーと呼びましょう。 実際、スケジューラーは(forループを使用して)古典的な意味で「反復」しません。 代わりに、2つの将来のコレクションをサポートします。
最初のコレクションを「実行可能」シーケンスと呼びます。 これは未来であり、その結果は利用可能です。 このリストが空になるまで、スケジューラーは1つの項目を選択し、1つの反復ステップを実行します。 このステップは、将来の結果(ソケットから読み込まれたばかりのデータかもしれません)で.send()ジェネレーターメソッドを呼び出します。 ジェネレーターでは、この結果はyield式の戻り値として表示されます。 send()が結果を返すか完了すると、スケジューラは結果(StopIteration、別の例外、または何らかのオブジェクトである可能性があります)を解析します。
(混乱している場合は、ジェネレーターの動作、特に.send()メソッドについて読んでください。おそらく、PEP 342が良い出発点です)。
(...)
スケジューラーによってサポートされる2番目の将来のコレクションは、まだI / Oを待機している未来で構成されます。 それらは何らかの形でselect / poll / shellなどに渡されます。 ファイル記述子がI / Oの準備ができたときにコールバックを提供します。 コールバックは、実際にfutureによって要求されたI / O操作を実行し、結果のfuture値をI / O操作の結果に設定し、futureを実行キューに移動します。
(...)
今、私たちは最も興味深いものに到達しました。 複雑なプロトコルを作成しているとします。 プロトコル内で、recv()メソッドを使用してソケットからバイトを読み取ります。 これらのバイトはバッファに到達します。 recv()メソッドは非同期ラッパーにラップされ、I / Oを設定し、先に説明したように、I / Oが完了すると実行されるfutureを返します。 ここで、コードの他の部分が一度に1行ずつバッファーからデータを読み取りたいとします。 readline()メソッドを使用したとします。 バッファーのサイズが平均行長よりも大きい場合、readline()メソッドはブロックせずにバッファーから次の行を取得するだけです。 ただし、バッファに行全体が含まれていない場合があり、readline()はソケットでrecv()を呼び出します。
質問:readline()はfutureを返すべきかどうか? 彼が時々バイト文字列を返し、時には将来、呼び出し側に型チェックと条件付きyieldを強制するのはあまり良くありません。 そのため、readline()は常にfutureを返す必要があります。 readline()が呼び出されると、バッファーをチェックし、少なくとも1行全体が見つかった場合、futureを作成し、バッファーから取得した行の結果を設定して、futureを返します。 バッファーに行全体がない場合は、I / Oを開始してそれを予期し、I / Oが完了すると新たに開始します。
(...)
しかし、現在、I / Oブロッキングを必要としないが、readline()がfutureを返すため、スケジューラへの呼び出しを強制する将来の多くのものを作成しています。これは、呼び出し元からyieldが必要なため、スケジューラへの呼び出しを意味します。
スケジューラーは、すでに完了している未来が表示されていることを確認した場合、コルーチンに直接制御を転送するか、未来を実行キューに戻すことができます。 後者は、キューの最後で待機する必要があるだけでなく、メモリのローカリティ(存在する場合)もおそらく失われるため、作業が大幅に遅くなります(複数の実行可能なコルーチンがある場合)。
(...)
このすべての最終的な効果は、コルーチンの作成者がyield futureについて知る必要があることです。したがって、Pythonの関数呼び出しはかなり遅いため、複雑なコードをより読みやすいコルーチンに再編成するためのより大きな心理的障壁が存在します。 また、Glyphとの会話から、典型的な非同期I / O構造では速度が重要であることを覚えています。
これをyield-fromと比較しましょう。
(...)
「Sからの収量」は「Sのiの場合:収量i」とほぼ同等であると聞いたことがあるかもしれません。 最も単純な場合、これは事実ですが、コルーチンを理解するには十分ではありません。 以下を考慮してください(非同期I / Oについてはまだ考えないでください):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
このコードは、「okay」と「42」を含む2行を出力します(その後、未処理のStopIterationを生成します。これは、gen1の最後にyieldを追加することで抑制できます)。 このコードは、pythontutor.comのリンクで実際に動作しています。
次に、次のことを考慮します。
def gen2(): yield from gen1() driver(gen2())
まったく同じように機能します。 今考えて。 どのように機能しますか? この場合、コードはNoneを返すため、forループの単純なyield-from拡張はここでは使用できません。 (試してみてください) 。 Yield-fromは、ドライバーとgen1の間の「透過チャネル」として機能します。 つまり、gen1が値をOKにすると、yield-fromを介してドライバーにgen2を終了し、ドライバーが42をgen2に送り返すと、この値はyield-fromを介して再びgen1に返されます(yieldの結果になります) )
ドライバーがジェネレーターにエラーを投げた場合も同じことが起こります。エラーはyield-fromを通過して、それを処理する内部ジェネレーターに送られます。 例:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
このコードは、「okay」と「bah」、および次のコードを提供します。
def gen2(): yield from gen1()
(こちらをご覧ください: goo.gl/8tnjk )
次に、この種のコードについて説明できるように、単純な(ASCII)グラフィックスを紹介します。 [f1-> f2-> ...-> fN)を使用して、一番下のf1(最も古い呼び出しフレーム)と一番上のfN(最も新しい呼び出しフレーム)のスタックを表します。リストの各項目はジェネレーターで、->はyield-fromです。 最初の例のドライバー(gen1())にはyield-fromがありませんが、gen1ジェネレーターがあるため、次のようになります。
[ gen1 )
2番目の例では、gen2はyield-fromを使用してgen1を呼び出すため、次のようになります。
[ gen2 -> gen1 )
半開区間[...)の数学表記を使用して、右端のジェネレーターがyield-fromを使用して別のジェネレーターを呼び出すときに、右端に別のフレームを追加できることを示します。 左端は、ドライバーが見るもの(つまり、スケジューラー)です。
これで、readline()の例に戻る準備ができました。 readline()は、yield-fromを使用する別のジェネレーターであるread()を呼び出すジェネレーターとして書き換えることができます。 後者は、ソケットからの実際の入出力を行うrecv()を呼び出します。 左側にあるアプリケーションは、readline()を呼び出すジェネレーターであり、これもyield-fromを使用して検討します。 スキームは次のとおりです。
[ app -> readline -> read -> recv )
現在、recv()ジェネレーターはI / Oを設定し、それを未来にバインドし、* yield *(yield-from!ではありません)を使用してスケジューラーに渡します。 futureは、スケジューラの両方のyield-from矢印に沿って左側に移動します(「[」の左側にあります)。 スケジューラは、ジェネレータのスタックが含まれていることを知らないことに注意してください。 彼が知っているのは、彼が一番左のジェネレーターを含んでいること、そして彼がちょうど未来を発行したことです。 I / Oが完了すると、スケジューラは将来の結果を設定し、ジェネレーターに送り返します。 結果は両方のyiled-from矢印に沿ってrecvジェネレーターに右に移動し、recvジェネレーターはソケットから読み取りたいバイトをyield結果として受け取ります。
つまり、yield-fromフレームワークスケジューラは、前述のyieldベースのフレームワークスケジューラと同じようにI / O操作を処理します。 *しかし:*スケジューラーはreadline()とread()の間、またはread()とrecv()の間、またはその逆の制御の転送に参加しないため、futureが既に実行されている場合、最適化について心配する必要はありません。 したがって、app()がreadline()を呼び出し、readline()がバッファーからの要求を満たすことができる場合(read()を呼び出さずに)、スケジューラーはまったく参加しません-この場合のapp()とreadline()の相互作用は、バイトコードインタープリターによって完全に処理されますPython スケジューラーはより単純にすることができ、コルーチンの呼び出しごとに作成および破棄される将来のスケジューラーがないため、スケジューラーによって作成および管理される将来の数は少なくなります。 まだ必要な未来は、たとえばrecv()によって作成された実際のI / Oを表す未来だけです。
ここまで読んだことがあれば、報いを受けるに値します。 実装の詳細の多くは省略しましたが、上記の図は本質的に図を正しく反映しています。
もう1つ指摘しておきたいことがあります。 *コードの一部にyield-fromを使用させ、他の部分にyieldを使用させることができます。 ただし、歩留まりを確保するには、チェーン内のすべてのリンクに、コルーチンだけでなく未来が必要です。 yield-fromを使用することにはいくつかの利点があるため、ユーザーにいつyieldを使用するかを覚えておく必要はなく、yield-fromの場合は常にyield-fromを使用する方が簡単です。 簡単な解決策では、recv()がyield-fromを使用して将来のI / Oをスケジューラに渡すこともできます。__iter__メソッドは、実際に未来を提供するジェネレータです。
(...)
そしてもう一つ。 yield-fromはどの値を返しますか? これは、*外部*ジェネレーターの戻り値であることがわかります。
(...)
したがって、矢印は、左と右のフレームを* yielding *ターゲットに接続しますが、通常の戻り値も通常の方法で一度に1つのスタックフレームを渡します。 例外は同じ方法で移動されます。 もちろん、それらをキャッチするには、各レベルでtry / exceptが必要です。
yield fromは、awaitとほぼ同じであることがわかります。
非同期対収量
def coro()^ y = aからの収量 | async def async_coro(): y = aを待つ |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
古い学校と新しい学校の2つのコルーチンには、わずかな違いが1つしかありません。
なぜこれだけなのですか? 竜巻は単純な収量を使用します。 バージョン5より前では、このコールチェーン全体をyieldを介して接続します。これは、パラダイムからの新しいクールなyieldとの互換性が不十分です。
最も単純な非同期ベンチマーク
総合的なテストに従ってのみ選択する、本当に良いフレームワークを見つけることは困難です。 実生活では、多くのことがうまくいかないことがあります。
Aiohttpバージョン3.4.4、Tornado 5.1.1、uvloop 0.11を使用し、Intel Xeonサーバープロセッサ、CPU E5 v4、3.6 GHzを使用し、Python 3.6.5でWebサーバーの競争力をチェックし始めました。
マイクロサービスの助けを借りて解決し、非同期モードで動作する典型的なタスクは次のようになります。 リクエストを受け取ります。 それぞれについて、あるマイクロサービスに対して1つのリクエストを行い、そこからデータを取得し、さらに非同期で別の2つまたは3つのマイクロサービスに移動し、データベースのどこかにデータを書き込んで結果を返します。 私たちが待つ多くのポイントが判明しました。
より簡単な操作を実行します。 サーバーの電源を入れて、50ミリ秒スリープします。 コルーチンを作成して完了します。 競争力のあるサーバーで多くのコルーチンが同時にスピンするという事実のために、許容可能な遅延を伴う非常に大きなRPS(完全に合成されたベンチマークで見られるものと同程度ではないかもしれません)はありません。
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
ロード-GET HTTPリクエスト。 所要時間-300秒、1秒-ウォームアップ、負荷の5回の繰り返し。
 サービス応答時間のパーセンタイルの結果。
サービス応答時間のパーセンタイルの結果。パーセンタイルとは何ですか?いくつかの大きな数字があります。 95パーセンタイルXは、このサンプルの値の95%がX未満であることを意味します。5%の確率では、数値はXより大きくなります。
Aiohttpはこのような簡単なテストで1000 RPSで素晴らしい仕事をしたことがわかります。 これまでのところ、
uvloopはありません 。
トルネードを、旧(歩留まり)および新(非同期)学校のコルーチンと比較してください。 著者は、非同期の使用を強くお勧めします。 それらが本当にはるかに高速であることを確認できます。
1200 RPSでは、トルネードは、新しい学校のコルーチンを使用したとしても、すでにあきらめ始め、古い学校のコルーチンを使用したトルネードは完全に吹き飛ばされました。 50ミリ秒スリープし、マイクロサービスが80ミリ秒を担当する場合、これはどのゲートにも入りません。
1,500 RPSの新しい学校のトルネードは完全にgaveめましたが、Aiohttpは3,000 RPSの制限からはほど遠いです。 最も興味深いのはまだ来ていません。
Pyflame、実用的なマイクロサービスのプロファイリング
プロセッサでこの瞬間に何が起こっているのか見てみましょう。

Pythonの非同期マイクロサービスが本番環境でどのように機能するかを考え出したとき、私たちはそれが何にぶつかったのかを理解しようとしました。 ほとんどの場合、問題はCPUまたは記述子にありました。 Uberには、ptraceシステムコールに基づいた
Pyflameプロファイラーという優れたプロファイリングツールがあります。
コンテナでサービスを開始し、コンテナに戦闘負荷をかけ始めます。 多くの場合、これはささいな作業ではありません。戦闘中の負荷を作成することは、負荷テスト、外観、およびすべてで正常に機能するように合成テストを実行することが多いためです。 あなたは彼に戦闘負荷をかけると、ここでマイクロサービスが鈍り始めます。
動作中に、このプロファイラーは呼び出しスタックのスナップショットを作成します。 サービスを変更することはできません。近くでpyflameを実行するだけです。 一定期間に一度スタックトレースを収集し、クールな視覚化を行います。 このプロファイラーは、特にcProfileと比較した場合、オーバーヘッドがほとんどありません。 Pyflameはマルチスレッドプログラムもサポートしています。 この製品をprodで直接起動しましたが、パフォーマンスはそれほど低下しませんでした。
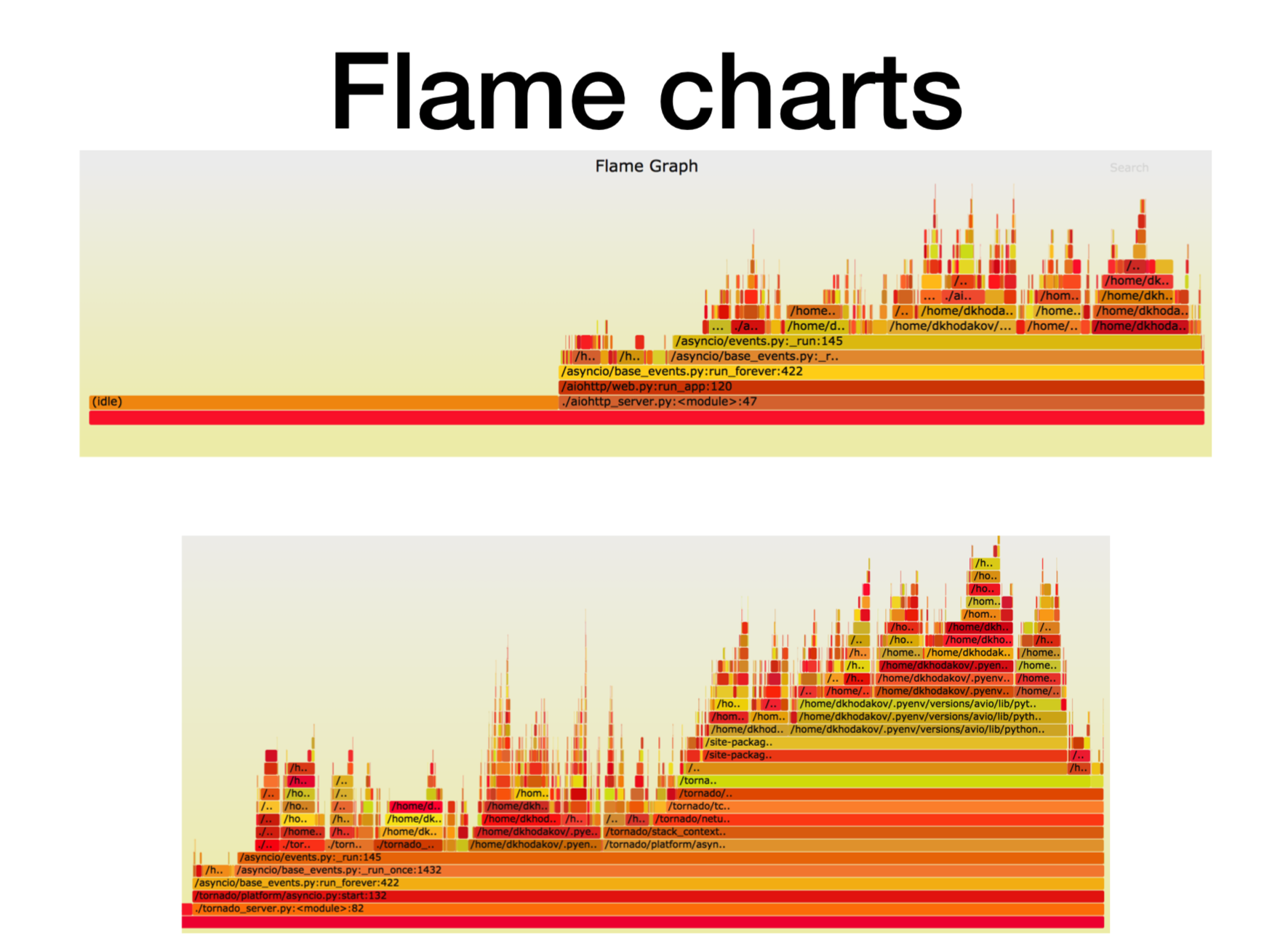
ここで、X軸は、スタックフレームがすべてのPythonスタックフレームのリストに載っていたときの時間、呼び出しの数です。 これは、スタックのこの特定のフレームで費やしたプロセッサ時間のおおよその量です。
ご覧のとおり、aiohttpでのほとんどの時間はアイドル状態になります。 すばらしい:これは、ほとんどの時間でネットワークコールを処理するために、非同期サービスに必要なものです。 この場合のスタックの深さは約15フレームです。
同じ負荷のトルネード(2番目の写真)では、アイドルに費やされる時間が大幅に短縮され、この場合のスタック深度は約30フレームです。
こちらが
svgへの
リンクです。
より複雑な非同期ベンチマーク
async def work():
125ミリ秒のランタイムが必要です。

uvloopを使用したトルネードの方がうまくいきます。 しかし、Aiohttp uvloopはさらに役立ちます。 Aiohttpは2300-2400 RPSで動作が悪くなり、uvloopを使用すると負荷範囲が大幅に拡大します。 インポートの1つの行、そして今、あなたははるかに生産的なサービスを持っています。
まとめ
今日私があなたに伝えたかったことを要約します。
- まず、かなりの量の長いコルーチンが存在する特定の人工ベンチマークを開始しました。 私たちのテストでは、AiohttpはTornadoよりも2.5倍優れたパフォーマンスを示しました。
- 第二の事実。 Uvloopは、Aiohttpのパフォーマンスの向上に非常に役立ちます(Tornadoよりも優れています)。
- Pyflameについて説明しました。Pyflameを使用して、実稼働環境でアプリケーションを直接プロファイルすることがよくあります。
- また、(await)vs yieldからの収量についても話しました。
これらのベンチマークの結果、私たちの推奨チーム(および他の一部)は、実稼働環境でのPythonのマイクロサービスについて、Tornadoとともにほぼ完全にAiohttpに移行しました。
- 戦闘サービスの場合、CPU消費は2倍以上減少しました。
- httpリクエストのタイムアウトを尊重し始めました。
- 遅延サービスは2〜5倍減少しました。
これ
がベンチマークへのリンクです。 興味があれば、それを繰り返すことができます。 ご清聴ありがとうございました。 質問してください、私はそれらに答えようとします。