短期間で、プロメテウスは最も人気のある監視ツールの1つになりました。 特に、そしてその作業の高速性に感謝します。 そのローカルストレージは、メトリックの短期ストレージに最適であり、メトリックと連携します。 場合によっては、古いデータを自動的にカットするが、それらを操作するためのインターフェイスを変更せずに、メトリックを数か月および数年にわたって配布したいことがあります。
これについては、RootConf 2018でのAlexey Palazhchenkoによるレポートのデコードです。レポート:プロメテウス、ローカルストレージTSDB、リモートストレージプロメテウス、PromQL、TSDB、クリックハウス、PromHouse、InfluxDBのビット。
猫の下で誰が気にしてください。
友達! みなさんこんにちは! 私の名前はアレクセイ・パラジチェンコです。 私はパーコナで働いています。 プロメテウスでのメトリックの長期保存についてお話したいと思います。

私はPerconaで働いており、percona監視および管理と呼ばれる製品を作っています。 これは、お客様がご自身で設定したボックスソリューションです。 PMMは完全にオープンソースです。 Prometheus、グラフ作成用のGrafana、カスタムクエリ分析ソフトウェア、および管理を可能にする独自のラッパーで構成されています。 たとえば、Prometheusにスクレイプターゲットを追加できます。 これらは、コンテナまたは仮想マシンを手動で入力して構成ファイルを編集することなく、メトリックを取得する新しいソースです。
これらはSaaSではないことを理解することが重要です。 生産はありません。 私たちの生産はお客様にあります。 それを実験することはあまり良くありません。 productionと呼ばれる最も近いものがあります -これはhttps://pmmdemo.percona.com/です。 レポートの時点で、GDPRのためにpmmdemo.percona.comをシャットダウンする必要がありました。
PMMをお客様に提供します—箱入りソリューション:Dockerコンテナまたは仮想マシン。 彼らはすべてプロメテウスが好きです。 プロメテウスを初めて見ている人の中には、プルモデルに出くわす人もいます。 初心者にとって、これは不便です。 一般的に別の大きな会話。 プルまたはプッシュメソッドについて議論することができます。 平均して、これはほぼ同じことです。
プロメテウスのいくつかのことはとてもクールです。
プロメテウスの顧客はそれが好きです。 彼らは、メトリックをますます長く保ちたいと考えています。 誰かがPrometheusを運用上の監視のみに使用しています。 しかし、1年前のグラフと比較して、メトリックをより長く保持し、ダイナミクスを観察したい人がいます。 ただし、メトリクスの長期保存の目標は、Prometheusプロジェクトの目標ではありません。 最初は、メトリックを短時間保存するために作成されました。 SoundCloudはわずか数日でメトリックを保存します。 Prometheusには、これをもっと長くできるメカニズムがありますが、少し横に配置されています。 したがって、システムのコアを変更することなく、Prometheusエコシステムのソリューションを作成できます。 それらに基づいて、同じエコシステム内で独自の決定を下すことができます。

これは既製のソリューションに関するレポートではありません。 これは、私たちの経験、痛み、試みに関する報告です。 このレポートの後でリポジトリまたはドッカーコンテナをダウンロードして実行すると予想される場合は、動作しますが、そうではありません。 しかし、同時にそれはそうなるのに十分近い。 いくつかの基礎があります。 それらはすべてオープンソースです。 試してみることができます。 彼らはまだ生産の準備ができていません。 しかし、このレポートに記載されている情報を使用すると、理由を理解できます。 自分に合った独自の決定を下すことができます。
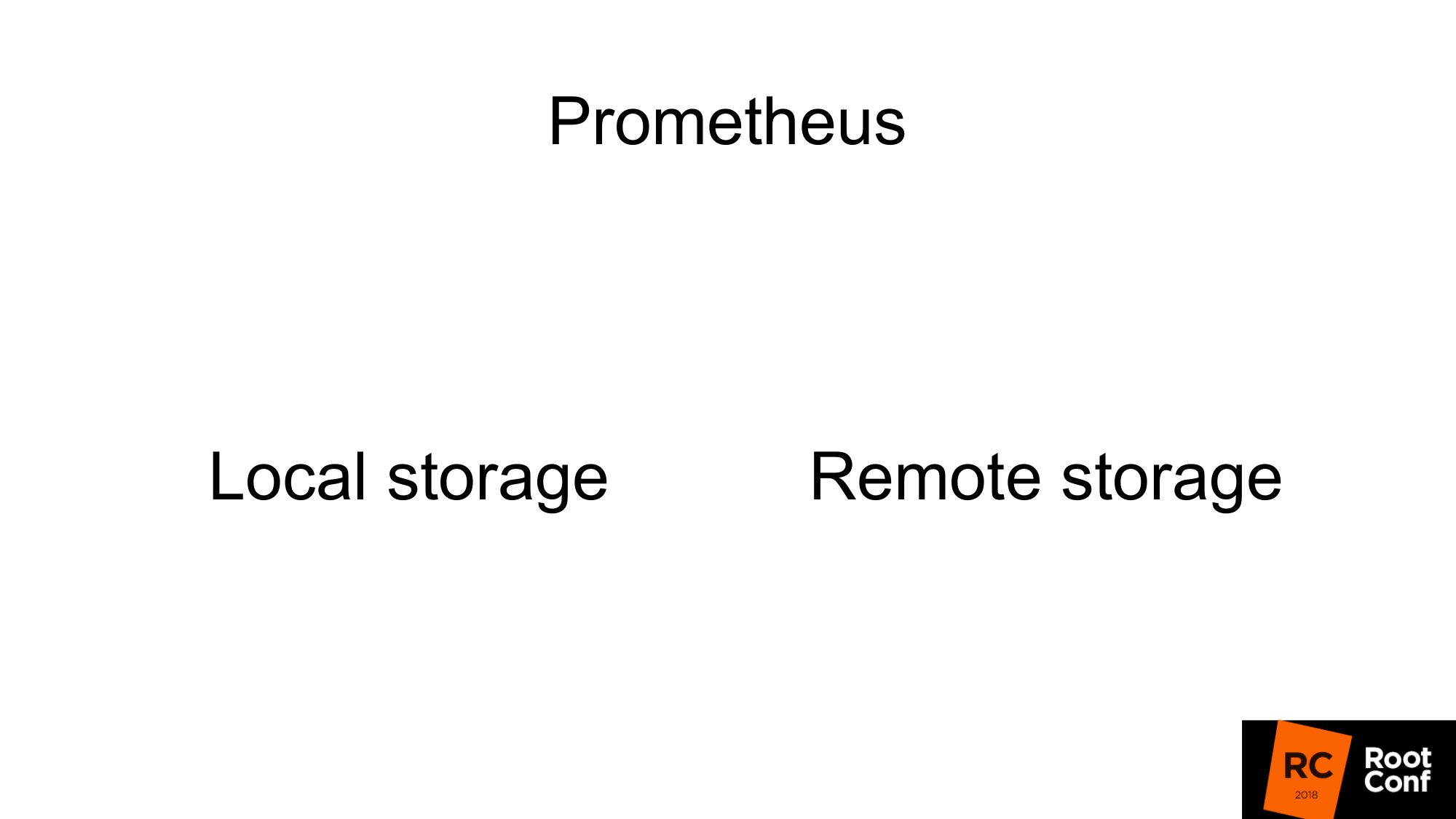
メトリックはどのようにPrometheusに保存されますか? ローカルストレージがあります。 リモートストレージがあります。 これらは実際には2つの異なる世界です。 それらは弱く交差します。 したがって、レポートも2つの部分に分かれています。

Prometheusの優れたイントロがあったメインホールの以前のレポートにいた場合、ローカルストレージはTSDBと呼ばれる独立したライブラリであることがわかります。 TSDBはOpenTSDBとは関係ありません。 TSDBは、Goプログラムから使用できる別個のGoパッケージです。 TSDBライブラリレベルでは、クライアントまたはサーバーはありません。
このライブラリは、時系列データを操作するために最適化されています。 たとえば、TSDBにはデルタエンコーディングがあり、これにより、数値自体ではなく、これらの数値間の変更を保存できます。 これにより、16バイトではなく1バイトを保存できます。 時間に1バイト、値に1バイト。 つまり、この優れた圧縮のために、正確に平均1または2バイトを保存します。
TSDBはプルモデル用に最適化されています。 データはそこにのみ追加されます。 プロメテウスは履歴データを記録できません。 このためのAPIはありません。 最大のデルタは約5分です。 データが古い場合、受け入れられません。
TSDBには、組み込みのダウンサンプリングtsdb#313はありません。 一般に、プロメテウスの周りで何かをしているプロジェクトがあり、そこにダウンサンプリングがあるという事実について議論された未解決の問題があります。 これまでのところ、解決策はTSDBがダウンサンプリングを追加しないことです。

TSDBからどのようにデータを取得しますか? TSDBはディスク上のデータベースです。 Goプログラムを作成している場合は、それを使用できます。 ただし、Goでプログラムを作成しない場合は、クエリクエリを作成できるJSON APIがあります。 Prometheusを使用したことがあり、少なくとも一度チャートを作成したことがあれば、PromQLクエリとオプションで時間を実行できるクエリパラメータがある標準クエリAPIを知っています。 時間がない場合は、現在の時間が取られます。
特定のクエリがスライド上で強調表示されますが、実際にはめったに表示されません。 これはハックです。 これにより、Prometheusのすべてのメトリックを引き出すことができます。 どのように機能しますか? PromQLのレベルでは、常にセリエに一致するような表現を書くことは不可能であると言われています。 これはルールに直接記述されます。 別のルールでは、すべての値が空であるようなマッチャーを作成することはできません。 単に中括弧を書くと、これは機能しません。 nameが何かと等しくない(空の値ではない)場合、機能しません。 しかし、これはあなたがこれを行うことができる本当のハックです。 ただし、特に文書化されていません。 これが機能することをコード自体にコメントがあります。
2番目のクエリはquery_rangeで、これは同じことを行いますが、データを範囲内でいくつかのステップで返します。 基本的に、最初から最後までの各ステップでクエリを数回実行します。 これは、グラフィックの描画に使用されるAPIです。 最初のAPIは、インスタント値を取得するために使用します。

メタデータを取得するためのAPIがあります。 メトリックのすべての名前を取得する場合、次のようなクエリを作成します。matchはメトリックの配列です。 いくつかの引数が存在する場合がありますが、この場合、同じ一致を渡し、すべてが返されます。
2番目のメタAPI。すべてのラベルの値を返します。 すべてのジョブのリストを表示する場合は、label_nameの代わりにjobを作成してこのリストを取得します。 これらのAPIはJSONを返します。

Prometheus自体のすべてのメトリックをエクスポーターにネイティブな形式で返す別のAPIがあります。 この形式はexpfmtと呼ばれます。 プロメテウス自体には、このようなリクエストを行うことができるフェデレーションAPIがあります。 これは何のためですか? 最も簡単なオプションは、すでにexpfmtで動作するコードがある場合、カスタムJSON APIで動作するように再トレーニングする必要はありません。 オブジェクトの最上位のどこかにJSONがある場合、ほとんどの場合、このオブジェクト全体を解析する必要があるため、この形式のストリーミングははるかに簡単です。 ここでは、行ごとに実行できます。
最も重要なことは、それが別個のAPIであることです。 実際のエクスポートと同じように機能します。 別のプロメテウスを使ってそれを削ることができます。 これは、通常のパラメーターを持つ通常のジョブです。 パラメータ-クエリURLを渡す必要があります。 カールリクエストを行う場合、ここでも同じようになります。 現在の時間値のすべてのメトリックを取得します。 唯一の注意点:このAPIを介して別のプロメテウスを廃棄するPrometheusがジョブとインスタンスラベルの値をこすらないように、honor_labelsを設定する必要があります。 このフェデレーションAPIを使用すると、1つのプロメテウスから別のプロメテウスにすべてのデータをロードできます。
これはどのように使用できますか?
まず、最も重要なことは、これを行う必要がないということです。 TSDBはさまざまな動作モードに最適化されています。 大量のデータを取得するプロメテウスがある場合、大量のI / Oを実行します。 Federation APIを使用する場合、入力出力の量は約2倍に増加します。 ニュアンスがあります。 連合をスクレイプする頻度と、ターゲットをスクレイプする頻度によって異なります。 時間を変更しない場合、これにより負荷が実際に2倍になります。 したがって、Prometheusを拡張してフェデレーションを有効にしたい場合は、それを強制終了します。 負荷は倍増します。
第二の瞬間。 データをスキップします。 データの競合が発生します。 なぜそう このAPIは、PrometheusのほとんどすべてのAPIと同様、アトミックではありません。 新しいデータが到着した場合、フェデレートリクエストがまだ進行中の時点で新しいスクレイピングが終了します。ある時系列で1つのデータを取得し、別の時系列で新しいデータを取得できます。 それが無関係な時系列である場合、それは一般的に怖くないです。 しかし、expfmtレベルでいくつかの基本的なメトリックによって表される要約またはヒストグラムがある場合、それらの間に矛盾が生じます。

このアトミックな問題をどのように解決できますか? プロメテウスには、既存の時系列から新しい時系列を作成できる記録ルールがあります。 これはあまり頻繁に行うことはできません。 これはダウンサンプリングを行う1つの方法です。 たとえば、ターゲットを1秒ごとに廃棄しますが、その後1分でnode_cpu集計を実行します。 Prometheus 2.0でグループ化すると、これらの集計を順番に実行できます。 同じグループにあるルールは、厳密に順番に実行されます。 この時点では、原子性の問題はなく、プロセスでデータが変更されるという問題はありません。 しかし、これは、これに論理的に接続されているがデータモデルの観点からは接続されていない他のデータを許容できるという事実の問題を解決するものではありません。 まだ純粋な原子性はありません。 このトピックには未解決の問題があります。 スナップショットを作成できます。 TSDBデータベースに対してPromQLクエリを作成し、取得した値から評価で開始した時間の値よりも小さいすべてのサンプルを削除できます。 これが最も簡単な方法ですが、今のところまだ実行されていません。
記録規則は、フェデレーションが行うプロメテウスではなく、下位のプロメテウスで行う必要があることを理解することが重要です。 そうしないと、ピークがスキップされ、モニタリングが正しく機能しません。

これらの組み合わせをどのように使用して、ダウンサンプリングと長期保存を行うことができますか。
最初のもの。 連携を設定し、そのプロメテウスからすべてのデータをダウンロードするだけです。 この奇妙な正規表現はゾイドバーグのようなものです-実際には単なるコロンです。 コロンの左右にあるアスタリスク。 記録ルールには標準名を使用し、中央にコロンを追加します。 元の名前を分割すると、左側に集約レベルがあり、右側に関数があります。 通常のコロンメトリックはそうではありません。 コロンがある場合、これは集約であることを示しています。 その後、このメトリック名をグラフで使用します。 スケジュール、grafanaのダッシュボードをメインのPrometheus、および上位のプロメテウスと連携させるには、式またはを使用します。 どちらかがどれであるかに応じて、1つのメトリックまたは別のメトリックを使用します。 不正をしてラベルを変更して、新しいメトリックの名前を古い名前に変更できます。 これはかなり危険なアプローチです。 通常の添付ファイルのスペルを間違えると、時系列の競合が発生します。 プロメテウスは多くの警告をログに書き込みます。 これは表示されますが、理由を見つけるのは非常に困難です。 しかし、たとえばこれらの正規表現をプログラムで生成するなど、慎重に行うと、これは機能します。 次に、node_cpuのみが使用される通常のダッシュボードがあります。 使用されているプロメテウスに応じて、生データまたは集計データのいずれかを受け取ります。

前述したように、記録ルールは非常に簡単に生成できます。 既に示したAPIを介してすべての時系列を取得します。 ルールを作成し、これらのルールは正しい関数と演算子を使用する必要があります。 ゲージでレートを使用する必要はありません。 これは適切に機能しません。 countでのみ使用する必要があります。 作業レベルでは、データ型に関する情報がない場合があります。 たとえば、expfmtを使用する場合。 タイプに関する情報があります。 JSON APIが存在しない場合。 その結果、自動的に生成される式には物理的な意味がない場合があります。 したがって、ホワイトリストまたはブラックリストのいずれかを使用できます。 これに応じて、必要なルールを生成するか、意味をなさないルールを除外します。 promtoolツールを使用すると、生成したルール、生成した構成が適切であることを確認できます。 正しい構文です。

Grafanaがあり、複数のPrometheusがある場合、どのPrometheusにリクエストを送信するかを知る必要があります。 これをどのように行うのでしょうか?
1つの方法は、リクエスト内の時刻を調べる特別なプロキシを配置することです。これに応じて、Prometheusを選択します。 クエリには開始時間と終了時間があります。 これに応じて、手でルーティングを行うことができます。 これを行う何らかのプログラムを書くことができます。 実際には、これはluaモジュールまたは小さなプログラムを使用してnginxによって実行されます。

本当にAPIが必要ですか? TSDBを直接操作できますか? ニュアンスがあります。 まず、現在Prometheusで使用されているTSDBを使用しようとすると、これを行うことができなくなります。 これを防ぐ特別なロックファイルがあります。 これを無視するコードを書き、データの読み取りまたは書き込みを行おうとすると、それらを損傷することが保証されます。 読書も。 何ができますか? APIを介してデータを読み取り、TSDBを並行して作成できます。 次に、Prometheusを停止し、TSDBに置き換えます。 ただし、同時に、APIを介してすべてのデータを読み取ると、パフォーマンスが低下する可能性があります。 これについては少し後で説明します。
2番目のオプション。 これらのファイルをコピー(ホットバックアップ)できます。つまり、そのままコピーできます。 はい、破損します。 開くと、データが破損しているという警告が表示されます。 それらを修正する必要があります。 新しいデータが失われる可能性があります。 しかし、それは私たちにとって重要ではありません。 古いデータのダウンサンプリングが必要です。 ダウンサンプリングは、PromQLを使用して実行できます。 しかし、ニュアンスがあります。 TSDBよりもプロメテウスから引き裂くのははるかに困難です。 Goと依存関係の管理に少し精通している場合、ベンダーのPromQLは大きな苦痛です。 アドバイスはしません。 可能であればこれを避けてください。

リモートストレージに渡します。 Prometheusのリモートストレージで作業した人はいますか? いくつかの手。 リモートストレージは、長い間使用されてきたAPIです。 現在、バージョン2.2リモートストレージでは、実験的としてマークされています。 さらに、Remote Storage APIが確実に変更されることもわかっています。
リモート記憶域を使用すると、生データのみを操作できます。 入力または出力にPromQLはありません。 読んだときに、PromQLの全機能を使用することはできません。 基本的に、条件に一致するすべてのデータをリモートストレージから送り出します。 さらにPromQLは既にそれらで動作します。 これにはかなり大きなオーバーヘッドがあります。 ネットワークを介して大量のデータを送信する必要があります。 したがって、まだリリースされていないが、すでに遅延しているPrometheus 2.3では、読み取りのヒントがあります。 これについては後ほど説明します。
メタデータ用のAPIはまだありません。 すべての時系列をリモートストレージから返すAPIを作成することはできません。 Prometheus APIでリクエストを行った場合、リモートストレージでは機能しません。 ローカルデータベースにある時系列が返されます。 ローカルデータベースが無効になっている場合、0が返されます。これは少し予想外かもしれません。 現在、このAPIはProtoBufを使用しており、将来的には確実にgRPCに変更される予定です。 gRPCはHTTP2を必要とするため、彼らはまだそれをしていません。 そして実際には、彼らは彼と問題を抱えていました。

書き込みAPIは次のようになります。 リクエストにはラベルのセットがあります。 ラベルのセットは、時系列を一意に識別するだけです。 __name__は実際には特別な名前を持つ単なるラベル__name__ 。 サンプルは時間と値のセットです-int64とfloat64。 記録するとき、順序は重要ではありません。 これを自分自身に書き込むデータベースがすべてを正しく行うと想定されています。 プロメテウスは、いくつかの最適化を行い、それを再度ソートしない場合があります。 したがって、書き込み要求はほんの数時系列です。

書き込み構成にはかなり柔軟な構成があります。 書き込み並行性を構成するための多くのオプションがあります。 プロメテウスがシャードと呼ぶものは、本質的には競争力のある要求です。 1つのリクエストの最大サンプル数、並列リクエストの最大数、タイムアウト、繰り返し方法、バックオフを制限できます。 多くのデータベースでは、一度に100個のサンプル-これは非常に小さい場合があります。 ClickHouseを使用する場合は、もちろん、値を大幅に増やす必要があります。 そうしないと、非常に効率が悪くなります。

リモート読み取りAPIは次のようになります。 これは、開始から終了までの時間範囲と一致セットにすぎません。

一致は基本的に、名前と値のペアのセットであり、通常のラベルと条件タイプです。 比較すると、等式、不等式、または正規表現があります。 これは、PromQLに表示される通常の時系列セレクターです。 ここには機能はありません。

答えは、このクエリに一致するいくつかの時系列です。 ここでは、サンプルを時間で並べ替える必要があります。 繰り返しますが、これはプロメテウスが小さなCPUを節約するのに役立ちます-ソートする必要はありません。 ただし、データベースでこれを行う必要があると想定されています。 ほとんどの場合、そうなるでしょう。なぜなら、ほとんどの場合、時間通りにインデックスがあるからです。

Prometheus 2.3は読み取りヒントを導入しました。 これは何ですか これは、要求されている時系列で機能する内部関数が適用されることをPrometheusに伝える機会です。 これは、関数または集約演算子のいずれかです。 レートかもしれません。 つまり、それはfuncと呼ばれますが、実際には合計であり、PromQLの観点からは実際には関数ではありません。 これが演算子です。 そして一歩。 前の例では、1分のレートがありました。 ここで、速度は関数であり、ステップとしてのミリ秒単位の1分です。 このヒントは、リモートデータベースでは無視できます。 同時に、応答に無視されたかどうかの表示はありません。

読み取りの構成は何ですか?
まず、required_matchersという構成があります。 これにより、式に一致するリモートストレージリクエストを送信できます。 リモートストレージから集計データを読み取るには、コロンを含むクエリを使用する必要があります。
TSDBにあるリモートストレージから最近のデータを読み取るかどうかを選択できるオプションがあります。 通常、標準構成では、ローカルディスクに書き込まれる小さなローカルTSDBがあります。 彼女は数時間または数日間そこに保管します。 ダッシュボードの作成に使用されるアラートに使用される現在使用しているデータは、ローカルTSDBからのみ読み取られます。 高速ですが、大量のデータを保存することはできません。
古い履歴データは、リモートストレージから読み取られます。 これにより、ローカルストレージとリモートストレージが相互に通信する方法が明確になります。 重複排除はありません。
基本的に何が起こっているのか。 データはローカルストレージから取得され、read_recentが有効な場合、データはリモートストレージから取得されます。 それらは一緒にマージされます。 これは問題ではないと思われます。 最近のデータをダウンサンプリングしていないと仮定した場合、これらはまったく同じデータであり、ローカルデータと完全に一致します。サンプルは2倍になるため、関数には影響しません。 そうでもない。 irate()関数と、ゲージ用のペアがあり、最後の2つの値の差を返します。 指定された時間範囲を振り返りますが、最後の2つの値のみを使用します。 最後の2つの値の時間が同じ場合、差はゼロになります。 これはバグであり、見つけることはほぼ不可能です。 わずか4日前に修理されました。 これは興味のある人向けのチケットです 。

興味深いことに、リモート読み取りは、バージョン1.8以降、Prometheusによって実装されています。 これは、バージョン2.xに移行するときに古いPrometheusのデータを読み取ることができる方法です。 公式の方法では、リモート読み取りとして接続することをお勧めします。 必要に応じてデータが差し引かれます。
リモート読み取りを使用して、プロキシなしでクエリルーティングを行うことができます。 前のスライドの1つで、時間に応じて、1つのプロメテウスまたは別のプロメテウスでルーティングできることを示しました。 同様に、これを回避できます。 以下のリモート読み取りであるプロメテウスを差し込むだけで、そこからデータが読み取られます。 しかし、もちろん多くのデータが汲み上げられるという事実には修正があります。 特に、クエリヒントを使用していない場合。

なぜクリックハウスなのか?
私たちの研究ソリューションとして、私たちはClickHouseを選択しました。それは、私たちが長い間見てきたためです。 データベースのパフォーマンスに常に携わり、新しいデータベースを常にチェックしている人々がいます。 当社は、オープンソースのデータベースに取り組んでいます。
生のパフォーマンスがとても気に入っています。 CPU、時間などの点でその能力は非常に優れています。 これらのシステムのほとんどは、無限のスケーラビリティについて語っていますが、単一サーバーの効率についてはほとんど語っていません。 クライアントの多くは、メトリックをサーバーのペアに保存します。
組み込みの複製、シャーディング。
GraphiteMergeTreeは、グラファイトデータを格納するための特別なエンジンです。 最初は彼は私たちにとても興味がありました。

このエンジンは、グラファイトデータのロールアップ(間引きおよび集約/平均化)を目的としています。
Graphiteは完全なデータをClickHouseに保存しますが、それを受信できます。さらに、間引きGraphiteMergeTreeを使用すると、間引きなしでMergeTreeが使用されます。 感覚は、データが常にいっぱいであり、上書きされるのではなく、読み取りの最適化にすぎないということです。 しかし、全体的には悪くありません。 読み取りを行うとき、データをポンプアウトせず、それらは自動的に集約され、少量のデータを取得します-これは良いことです。 私たちの欠点は、すべてのデータが保存されることです。
月の初めにレポートの準備をしていました。 誰かが電報チャットに参加して、「GraphiteMergeTreeデータのダウンサンプル」と尋ねます。 もう書いてない ドキュメンテーションはノーと言います。 しかし、チャットの相手は「はい、optimizeを呼び出す必要があります」と答えます。 実行、確認-はい、真実。 ドキュメントは本質的にバグです。 次に、ソースコードを読んでチェックしましたが、最適化があり、最終的に最適化されています。 Optimize finalは、もともとGraphiteMergeTree専用に作成されました。 実際に彼はダウンサンプリングしています。 しかし、それは彼の手で呼ばれなければなりません。
GraphiteMergeTreeには異なるデータモデルがあります。 彼にはラベルがありません。 メトリックの名前ですべてを効果的に記述しても、うまくいきません。
名前メトリックは1つのテーブルに保存されます。 メトリックの名前の長さは異なります。 これにより、メトリックの名前でインデックス検索を行う場合、長さが異なるため、このインデックスは、このインデックスが固定長の値を持っている場合ほど効果的ではないという事実につながります。 ファイル検索を行う必要があるため。 バイナリ検索を行うために着陸する場所を正確に指定することは不可能です。

したがって、彼らは独自のスキームを作成しました。 スライドは、時系列をデータベースに保存する方法を示しています。 ClickHouseが必要とする日付は指紋です。 PrometheusまたはTSDBのソースを見ると、指紋は本質的にフルネーム時系列の短いクイックチェックサムであることがわかります。 指紋は、すべてのラベル、キー、および値の組み合わせです。 名前は通常のラベルです。 互換性のために同じアルゴリズムを使用します。 借方記入は便利です。 指紋は同じであり、TSDBとストレージでそれらが同じであることを確認できます。 ラベルは特別なJSONに保存されます。これにより、ClickHouseは標準機能でラベルを操作できます。 これは、スペースのないコンパクトなJSONであり、命名がわずかに単純化されています。 このテーブルは操作中には使用されません。 PromHouseと呼ばれる実際のソリューションのメモリに常に保存されます。 時系列とは何かを調べるためにサーバーを起動するときにのみ使用されます。 彼女は差し引かれます。 新しい時系列が到着すると、そこに記録します。 複数のPromHouseインスタンスはすべて、同じテーブルを読み取ることができます。 ReplacingMergeTreeは、これらの時系列(いくつかの異なるインスタンスがある)が同じ時系列を記述することを示しています。 彼らは争います-そして、ここで問題はありません。

サンプルを別のテーブルに非常に効率的に保存します。 固定長の値を使用すると、このフィンガープリントは時間と値が同じになります。 サンプルあたり24バイトを取得します。 長さが厳密に固定されています。 各列は個別に保存されます。 サイズが固定されていることがわかっているため、指紋検索は効果的です。 文字列の場合、GraphitmergeTreeのような問題はありません。 カスタムパーティションを使用します。 プライマリ指紋インデックスと時間。
24バイトは簡易バージョンです。 実際、それはよく圧縮されます。 実際、使用するスペースが少なくなります。 最新のテストでは、圧縮率は約1〜42です。

GraphiteMergeTreeがある場合、手動ダウンサンプリングを実行するにはどうすればよいですか? 実際、私たちは手でそれを行うことができます。 前と同じように、何も組み込まれていないときのシャーディング、パーティション分割。 手で新しいテーブルを作ります。 時間サンプルが来ると、どのテーブルに書き込むかを決定します。
読み込むテーブルのクエリから時間を選択します。 読み取りが境界で発生する場合、いくつかのテーブルを読み取ります。 次に、このデータを保持します。 これにはビューを使用できます。 たとえば、複数のテーブルのビューを作成すると、1つのクエリで読み取ることができます。 ただし、ClickHouseにはバグがあります。ビューからの述語はクエリに代入されません。 したがって、ビューでリクエストを行うと、すべてのテーブルに送信されます。 使用できないビュー。
ダウンサンプリングはどのように行いますか? 一時テーブルを作成します。 正しい関数を使用して、挿入を選択データにコピーします。
グローバルロックの下でアトミックな名前変更を行います。 既存のテーブルの名前を古いものに変更しています。 既存から新規。 古いテーブルを削除します。 148日間のデータはすでにダウンサンプリングされています。 ここで問題は何ですか? 美しく見えるに挿入します。 実際、正しい機能、適切な集約を適用する必要があります。 実際には、これを1つの大きな要求で行うことはできません。 少数の大規模なリクエストでさえも実行できません。 これはコードから実行する必要があります。 コードは、多数の小さなリクエストを送信します。 大規模なリクエストでこれを行うために最善を尽くしましたが、これはあまり効果的ではありません。 これまでの1日からのデータのダウンサンプリングには、1日もかかりません。 データの量によっては、時間がかかる場合があります。

ClickHouseは更新/削除されます。 削除すると、最初のバージョンが既に取得されています。 更新/削除が機能する場合、ダウンサンプリングデータスキームを簡素化できます。
次に、ClickHouseには、カスタム圧縮(デルタ、デルタからデルタ)を作成するタスクがあります。 これがTSDBの機能です。 これは時系列データに適しています。 これは、データの種類に応じて圧縮の種類を選択できる場合に特に便利です。 たとえば、カウンタは成長しているだけです。このためには、デルタデルタ圧縮が適しています。 大きさの周りで変動するゲージ。したがって、デルタはうまく機能します。

動作する他のストレージがあります。 すぐに使えるInfluxDBがあります。 スピードのために彼をscるのが慣習ですが、箱から出して動作し、何もする必要がないのは良いことです。
OpenTSDBと、書き込み専用のGraphiteがあります。 Prometheusの標準アダプターは実際には機能しません。
CrateDBがあります。 時系列データベース用にPostgreSQLをフォークするTimescaleDBがあります。 彼らはそれがうまくいくと言っていますが、私たちは自分で試していません。
フランケンシュタインプロジェクトとしても知られているCortexがあります。 これは彼をとてもよく説明しています。 これは、プロメテウス連合に基づいて決定しようとしている人たちです。 S3にデータを保存します。
サノスがいます。
- 彼は非常に興味深いアーキテクチャを持っています。 ローカルTSDBを使用するプロメテウスがあります。 それらの間にクラスターが作成されます。 各プロメテウスの隣には特別なサイドカーがあり、リモート読み取りおよびリモート書き込みAPIを介してリクエストを受け取ります。 彼はこれらのリクエストをプロメテウスにリダイレクトします。 Prometheusは、リモート読み取りおよびリモート書き込みAPIを使用できます。 すべてのサイドカーは相互接続されており、gRPCを介してカスタムAPIマスター間で複製が利用可能で、再シェーディングがあります。
- 洗練されたアーキテクチャ。
- かなり湿っています。 数ヶ月前、開始時のハーフキックから外れていました。

プルモデルを使用しても、大量のデータは書き込まれません。 年間データを入力するには、1年待つ必要があります。 どういうわけかそこにそれらを書き込もうとしています。
Prometheusにはリモート書き込みがないため、ローカルTSDBに大量のデータを書き込むことはできません。
2番目の問題。 ストレステスト用のデータを生成すると、よく揺れます。 たとえば、既存のデータを取得して100個のインスタンスを生成し、それらが同じデータである場合、圧縮係数は非常に美しいため、実際には発生しません。

Prometheusが一緒に保持できる通常のエクスポーターのように見える偽のエクスポーターを作成しました。
- スクラップが入ると、彼は上流の輸出業者に行きます。 データを取得します。
- 多くのインスタンスを生成します。 1がスクレイピーであり、出力で100を得たとしましょう。
- データをわずかに変更します:カウンターとゲージのプラスマイナス10%。
- 単純な値0または1は変更されません。応答するUPメトリックがある場合、サービスが実行されているかどうかを示します:yes-1またはno-0。そして098 UPの意味はあまり明確ではありません。
- 整数を実際の整数に変更したり、その逆を行ったりすることはありません。
- 通常のexpfmt形式でデータを提供するだけです。

データをロードするpromloadツール。 データの読み取り:
- 独自の形式のファイルから読み取ることができます
- たぶん、リモート読み取りから
- 一部のエクスポーターから読み取ることができます
さまざまな形式で書き込みます。 / dev / nullを含めて、読み取りがどのように迅速に機能するかを正確にテストする場合。
現在では、PromHouseだけでなく、リモート読み取りまたはPrometheusを使用するソリューション向けの負荷テストツールでもあります。

テストでは、ボトルネックは多くの場合、長期間データを生成する偽のエクスポーターであったため、読み取りキャッシュを追加します。 それらをキャッシュできます。 それらを非現実的に良いものにしてください。 しかし、私たちは遅くなりません。 ストレステストを数日待つ必要はありませんでした。
ある種のフィルタリングをその場で、ある種の変更をその場で行う。
TSDBのネイティブサポート。 API経由ではなく、ディスク上のデータベースを操作するため。
移行の精度に焦点を当てます。 pmmdemo.percona.com:connectedを配置すると、すべてのメトリックを受け取りました。 これをネイティブな方法で行うと、PrometheusはTSDBを開き、ディスクからすべての時系列を生成し、インデックスを生成してから、チャンクファイルにクロールし、それらが実際に存在することを認識します。 この時点で、すべてが横になります。
単純なアプローチは、時系列全体を取得し、古いデータから新しいデータに読み込むことです。 その瞬間、彼は横になります。 あなたは反対をする必要があります。 最初に、正規表現を使用したいくつかのクエリで時系列リストを取得する必要があります。 たとえば、Aで始まる時系列。次にBで始まる時系列を教えてください。次に、時間ではなく、メトリックによって正確に読み込みます。 これは非論理的ですが、これが機能する方法です。 あなたがそのようなことをするなら、これはニュアンスです。 OOM Killerがそこで発生したことがわかると、それはあなたが原因であることがわかります。

負荷テストの結果、グラフはありません。 負荷テストには多くの時間がかかりますが、残念なことに、設定エラーのためにすべてがうまくいきませんでした。 したがって、結果はうまくいきませんでした。
負荷テストを行うときに、Perconaブログに書き込みます。
グラフなしで結果を言うことができます。 録音は線形でした。 読書は急上昇し、あまり速くありませんでした。 現在のデータを読むことは、私たちにとってあまり重要ではありません。 読み取りヒントを使用して高速化できます。 read_recentを有効にして、読み取りを改善できます。 古いデータの場合、これは正常に機能します。

人々は長期保存を望んでいます。 そのような要求があります。 PromConでPromHouseについて話しました。 そこでは非常にホットなトピックでした。 サノスは積極的に開発しています。
すでに可能です。 これには解決策があります。 APIがあります。 いくつかの統合があります。 ただし、これらはすべてファイルでファイナライズする必要があります。 生産準備の整ったソリューションはありません。

見どころへのリンク。 最初のリンクは、PromHouseリポジトリです。 2番目のリンクは、彼が移動する可能性がある場所です。 今、1つのリポジトリにいくつかの異なるものがありますか? あまり密接に関連していません。 したがって、それらを転送する必要があります。
ブログには、パフォーマンスに関する情報といくつかのニュースが含まれます。
質問:
質問:InfluxDBに関する噂を確認しましたか?
回答:彼はあまり良くありませんでした。 彼はずっと良くなりました。 InfluxDBが遅く、バラバラになっているという事実に関するこれらすべての物語は、古いバージョンに関するものです。 現在のバージョンは安定しています。 言わない? それが速く動作すること。 しかし、それは安定して動作します。 私の意見では、InfluxDBの長所:
- まず、InfluxDBはそのまま使用できるため、近くで何かをする必要はありません。
- 次に、ClickHouseでは、TSDBではなく他のデータベースベースのソリューションと同様に、より使い慣れたクエリ言語を使用できます。 InfluxDBクエリ言語はSQLに似ています。 PromQLでは困難な分析を行うことができます。 TimeScaleDBを使用する場合-実際のSQLがあります。
質問:記録専用のGraphiteMergeTreeエンジンが取得されますか? グラフを表示したい場合、長期保存を表示するためにGrafanaをGraphiteに設定する必要がありますか?
回答:はい。 Prometheus自体にある統合は、録音に対してのみ機能します。 彼はデータを書き込むだけです。 したがって、GrafanaからGraphiteに移動します。
質問:そして、彼は書くときにラベルを失いますか?
回答:それらをどうするか、それらを挿入する方法、それらを挿入する場所を指示する構成があります。
聴衆からの情報:Avitoは、PrometheusからGraphiteまでのレコーディングのソリューションを作成していると言いました。
質問:記録することで、長期ストレージサーバーですべてが問題ないという結論に達しました。
100万メトリックのフローがあります(5分または15分)。 raid 6 sata ?
: PMM — . downsampling c 14 1 . , . . . .
: IOPS ?
: .
:
: . , . , , .
: InfluxDB, InfluxDB?
: read_recent. , remote storage. InfluxDB . . read_recent , .
: , Prometheus. InfluxDB. Grafana Prometheus. Prometheus PromQL , InfluxDB?
: .
: Prometheus InfluxDB Grafana?
: . Prometheus 2.2 , .
PS : valyala gecube
, .