
過去1年間、マイクロサービスについて非常に多くの出版物があったため、マイクロサービスの内容と理由を説明するのは時間の無駄になるため、残りの議論では、このアーキテクチャを実装する方法と、正確に直面した理由と直面した問題に焦点を当てます。
小さな銀行では大きな問題がありました。大量のレガシーとの膨大な量の同期RPCインタラクションによって接続された3つのpythonモノリス。 同時に発生するすべての問題を少なくとも部分的に解決するために、マイクロサービスアーキテクチャに切り替えることが決定されました。 しかし、そのようなステップを決定する前に、3つの主要な質問に答える必要があります。
- モノリスをマイクロサービスに分割する方法と、従うべき基準。
- マイクロサービスはどのように相互作用しますか?
- 監視方法
これらの質問に対する実際の簡単な回答は、この記事に当てられます。
モノリスをマイクロサービスに分割する方法と、従うべき基準。
この一見単純な質問が、最終的にすべてのさらなるアーキテクチャを決定しました。
私たちは銀行です。したがって、システム全体は、財政とさまざまな補助的なものを備えた業務を中心に展開します。 sagasを使用して金融システムのACIDトランザクションを分散システムに転送することは確かに可能ですが、一般的なケースでは非常に困難です。 したがって、次のルールを開発しました。
- マイクロサービスのSOLID Sを観察します
- トランザクションは完全にマイクロサービスで実行する必要があります-DBの損傷に対する分散トランザクションはありません
- 動作するには、マイクロサービスが独自のデータベースまたはリクエストからの情報を必要とします
- マイクロサービスの清潔さ(関数型言語の意味で)を確保するようにしてください
当然ながら、同時にそれらを完全に満たすことは不可能でしたが、部分的な実装でさえ開発を大幅に簡素化します。
マイクロサービスはどのように相互作用しますか?
多くのオプションがありますが、最終的にはすべてが単純な「マイクロサービス交換メッセージ」によって抽象化できますが、同期プロトコル(RESTを介したRPCなど)を実装する場合、モノリスの欠点のほとんどは残りますが、マイクロサービスの利点はほとんど現れません。 したがって、明らかな決定は、メッセージブローカーを使用して開始することでした。 RabbitMQとKafkaのどちらを選択するかは後者に決まっています。その理由は次のとおりです。
- Kafkaはよりシンプルで、単一のメッセージングモデル- パブリッシュ-サブスクライブを提供します
- Kafkaから2回目のデータ取得は比較的簡単です。 これは、監視やログ記録だけでなく、誤った処理を伴うバグのデバッグや修正にも非常に便利です。
- サービスを拡張する明確で簡単な方法:トピックにパーティションを追加し、より多くのサブスクライバーを起動しました-残りはkafkaが行います。
さらに、 非常に高品質で詳細な比較に注意を喚起したいと思います。
kafka + asynchronyのキューにより、次のことが可能になります。
- 他の人に顕著な影響を与えることなく、更新のためにマイクロサービスを短時間オフにします
- データの回復に煩わされずに、長期間サービスをオフにします。 たとえば、最近、会計マイクロサービスは減少しました。 2時間後に修復され、彼はカフカから生のアカウントを取り、すべてを処理しました。 以前のように、そこで発生するはずだったものを回復し、HTTPログとデータベース内の別のテーブルを手動で実行する必要はありませんでした。
- セールの現在のデータでサービスのテストバージョンを実行し、その処理の結果をセールのサービスのバージョンと比較します。
データのシリアル化システムとして、AVROを選択しました。理由は別の記事に記載されています 。
ただし、選択したシリアル化方法に関係なく、プロトコルの更新方法を理解することが重要です。 AVROはスキーマ解決をサポートしていますが、これを使用せず、純粋に管理上決定します。
- トピック内のデータはAVROを介してのみ読み書きされ、トピックの名前はスキームの名前に対応します(Confluentのアプローチは異なります -メッセージの上位バイトにレジストリからID AVROスキームを書き込むため、1つのトピックに異なるタイプのメッセージを含めることができます
- データを追加または変更する必要がある場合は、kafkaの新しいトピックで新しいスキームが作成されます。その後、すべてのプロデューサーが新しいトピックに切り替え、その後にサブスクライバーが続きます
AVRO回路自体をgitサブモジュールに保存し、すべてのkafkaプロジェクトに接続します。 彼らは、スキームの集中レジストリをまだ実装しないことに決めました。
PS:同僚は、AVROの代わりにJSONスキーマでのみオープンソースオプションを作成しました 。
いくつかの微妙な点
各サブスクライバーは、トピックからすべてのメッセージを受信します
これがパブリッシュ-サブスクライブインタラクションモデルの特異性です。トピックをサブスクライブすると、サブスクライバーはそれらすべてを受け取ります。 その結果、サービスで必要なのが一部のメッセージのみである場合、それらを除外する必要があります。 これが問題になる場合は、いくつかの異なるトピックでメッセージをレイアウトする個別のサービスルーターを作成し、それによってkafkaにはないRabbitMQ機能の一部を実装することが可能になります。 現在、1つのスレッドでpythonの1つのサブスクライバーが1秒間に約7〜5000メッセージを処理していますが、PyPyから実行すると、速度は11〜15,000 /秒に増加します。
トピック内のポインターの有効期間を制限する
kafkaの設定には、リーダーが停止した場所をkafkaが「記憶」する時間を制限するパラメーターがあります-デフォルトでは2日間。 休暇中に問題が発生し、2日間解決されない場合、トピックの位置が失われないように、1週間に上げるとよいでしょう。
確認時間制限の読み取り
Kafkaリーダーが30秒以内に読み取りを確認しない場合(構成可能なパラメーター)、ブローカーは何かが間違っていると信じ、読み取りを確認しようとするとエラーが発生します。 これを回避するために、メッセージを長時間処理する場合、ポインターを移動せずに読み取り確認を送信します。
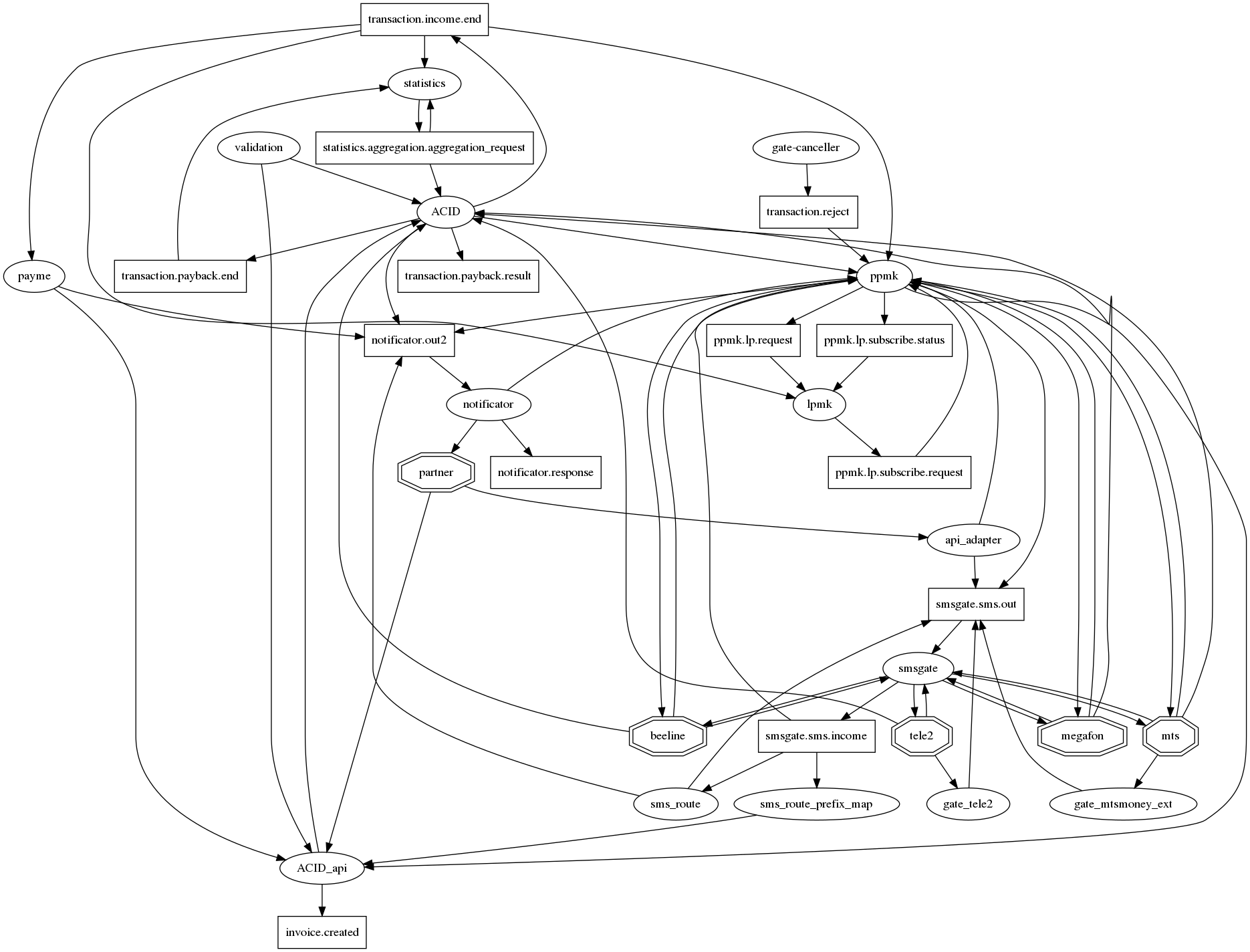
接続のグラフを理解することは困難です。
graphvizですべての関係を正直に描くと、1つのノードに数十の接続があるマイクロサービスの伝統的な黙示録のハリネズミです。 少なくとも何らかの方法(接続のグラフ)を読みやすくするために、次の表記法に同意しました:マイクロサービス-楕円、カフカの上部-長方形。 したがって、1つのグラフで、相互作用の事実とそのタイプの両方を表示できます。 しかし、残念ながら、それはそれほど良くなっていません。 したがって、この質問はまだ開かれています。
監視方法
モノリスの一部としても、ログファイルとセントリーがありましたが 、Kafkaを介して対話に切り替えてk8に展開すると、ログはElasticSearchに移動し、Elasticでサブスクライバーのログを読み取ることで最初に監視されました。 ログなし-作業なし。
その後、プロメテウスの使用を開始し、 kafka-exporterはダッシュボードをわずかに変更しました: https : //github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
その結果、これらの写真を取得します。
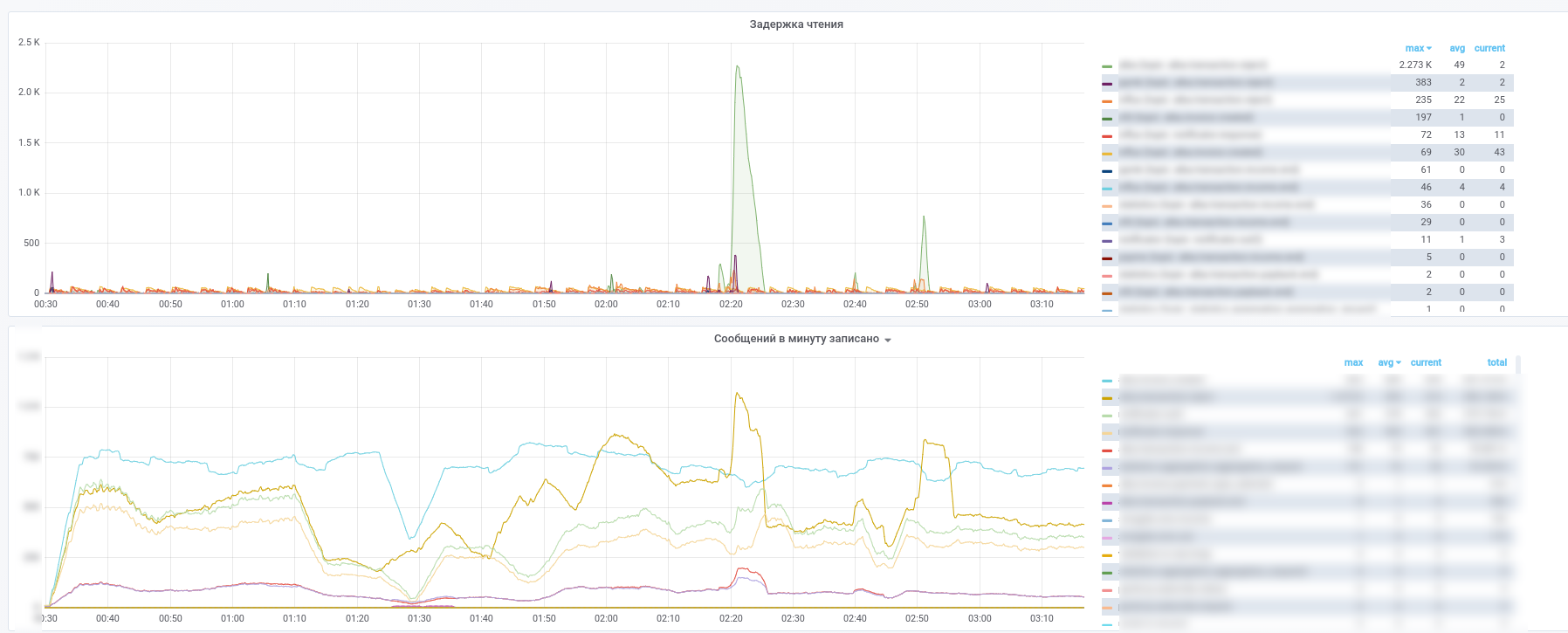
どのサービスがどのメッセージの処理を停止したかを確認できます。
さらに、主要トピック(支払いトランザクション、パートナーからの通知など)からのすべてのメッセージはInfluxDBにコピーされ、同じグラフナにまとめられます。 したがって、メッセージパッシングの事実を記録できるだけでなく、コンテンツに応じてさまざまなサンプルを作成することもできます。 したがって、「サービスからの応答の平均遅延時間は何ですか」や「このストアでの昨日と今日のトランザクションフローは非常に異なりますか」などの質問に対する答えは、常に手元にあります。
また、インシデントの分析を簡素化するために、次のアプローチを使用します。各サービスは、メッセージを処理するときに、システムがタイプのレコードの配列を表示するときに発行されるUUIDを含むメタ情報で補完します。
- サービス名
- このマイクロサービスの処理プロセスのUUID
- プロセス開始タイムスタンプ
- 処理時間
- タグセット
その結果、メッセージが計算グラフを通過すると、メッセージはグラフ上を移動したパスに関する情報で強化されます。 MQのzipkin / opentracingの類似物であることがわかります。これにより、メッセージを受信してグラフ上のパスを簡単に復元できます。 これは、グラフでサイクルが発生する場合に特に役立ちます。 支払いのシェアがわずか0.0001%の小さなサービスの例を思い出してください。メッセージのメタ情報を分析することで、検証のためにデータベースにアクセスすることなく、支払いの開始者であるかどうかを判断できます。