データの視覚化と分析は、現在、電気通信業界で広く使用されています。 特に、分析は地理空間データの使用に大きく依存しています。 おそらくこれは、通信ネットワーク自体が地理的に分散しているという事実によるものです。 したがって、このような分散の分析は非常に価値があります。
データ
k-meansクラスタリングアルゴリズムを説明するために、ニューヨークの無料パブリックWiFiに地理データベースを使用します。 データセットはNYC Open Dataで入手できます。 特に、k-meansクラスタリングアルゴリズムを使用して、緯度と経度のデータに基づいてWiFi使用クラスターを形成します。
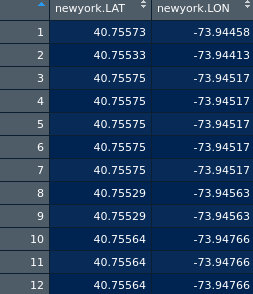
緯度と経度のデータは、プログラミング言語Rを使用してデータセット自体から抽出されます。
データの一部は次のとおりです。
クラスターの数を決定します
次に、以下のコードを使用してクラスターの数を決定します。このコードは結果をグラフで示します。
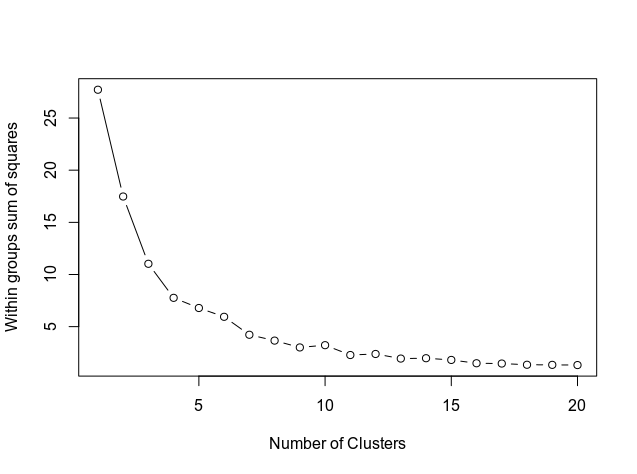
グラフは、曲線が約11でどのように整列するかを示しています。したがって、これはk-meansモデルで使用されるクラスターの数です。
K平均分析
K-meansの分析が実行されます。
newyorkdfデータセットには、緯度、経度、クラスターラベルに関する情報が含まれています。
> newyorkdf
newyork.lat newyork.lon fit.cluster
1 40.75573 -73.94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
...
80 40.84832 -73.82075 11
明確な説明を次に示します。
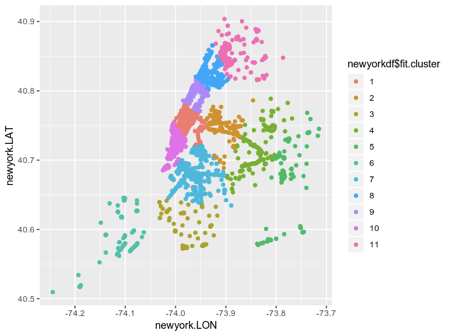
この図は役立ちますが、ニューヨーク自体の地図にオーバーレイすると、レンダリングはさらに価値があります。

このタイプのクラスタリングは、都市のWiFiネットワークの構造に関する優れたアイデアを提供します。 これは、クラスター1でマークされた地理的領域が多くのWiFiトラフィックを示していることを示しています。 一方、クラスター6の接続が少ない場合は、WiFiトラフィックが少ないことを示している可能性があります。
K-Meansクラスタリングだけでは、特定のクラスターのトラフィックが高いまたは低い理由がわかりません。 たとえば、クラスター6の人口密度は高いが、インターネット速度が低いと接続数が少なくなる場合。
ただし、このクラスタリングアルゴリズムは、さらなる分析のための優れた出発点となり、追加情報の収集を容易にします。 たとえば、このマップを例として使用すると、個々の地理的クラスターに関する仮説を立てることができます。 元の記事は
こちらです。