
データベースに関連するプロセスは、遅かれ早かれ、このデータベースへのクエリのパフォーマンスに問題が発生します。
RostelecomのデータウェアハウスはGreenplum上に構築されており、ほとんどの計算(変換)はETLメカニズムを開始(または生成および開始)するSQLクエリによって実行されます。 DBMSには、パフォーマンスに大きく影響する独自のニュアンスがあります。 この記事は、パフォーマンスと共有経験の点でGreenplumを使用する上で最も重要な側面を強調する試みです。
Greenplumの概要Greenplum-
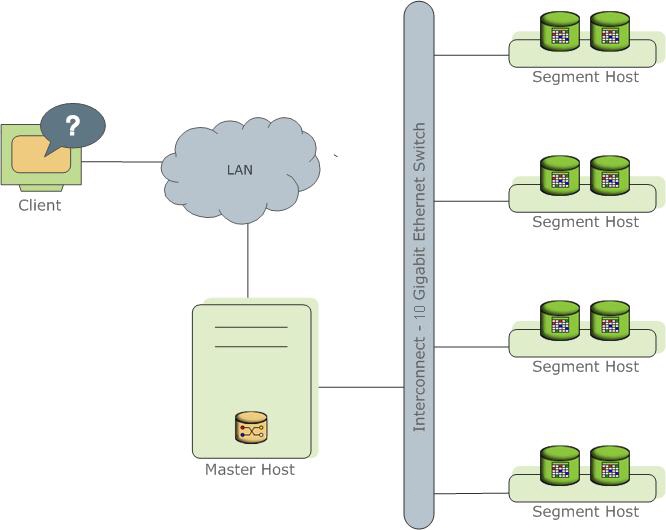
MPPデータベースサーバー。そのコアはPostgreSql上に構築されています。
PostgreSqlプロセスのいくつかの異なるインスタンス(インスタンス)を表します。 それらの1つはクライアントのエントリポイントであり、マスターインスタンス(マスター)と呼ばれ、残りはすべてセグメントインスタンス(セグメント、独立したインスタンス、それぞれ独自のデータを持っています)と呼ばれます。 各サーバー(セグメントホスト)は、1つから複数のサービス(セグメント)で実行できます。 これは、サーバーリソースと主にプロセッサをより活用するために行われます。 ウィザードはメタデータを保存し、クライアントをデータに接続する役割を果たします。また、セグメント間で作業を分配します。
詳細については、
公式ドキュメントを参照してください。
さらに記事では、リクエストプランへの多くの参照があります。 Greenplumの情報は
こちらから入手でき
ます 。
Greenplumで適切なクエリを作成する方法(まあ、少なくとも悲しくはない)
分散データベースを扱っているため、sqlクエリの記述方法だけでなく、データの格納方法も重要です。
1.配布
データは物理的に異なるセグメントに保存されます。 セグメントごとにランダムに、またはフィールドまたは一連のフィールドのハッシュ関数の値によってデータを分離できます。
構文(テーブルを作成する場合):
DISTRIBUTED BY (some_field)
または:
DISTRIBUTED RANDOMLY
このようなフィールドを持つレコードは1つのセグメントに分散されるため、データのゆがみにつながる可能性があるため、分布フィールドは良好な選択性を持ち、null値を持たないようにする必要があります。
フィールドタイプは整数であることが好ましい。 このフィールドは、テーブルを結合するために使用されます。 ハッシュ結合は(クエリの実行に関して)テーブルを結合するための最良の方法の1つであり、このデータ型で最適に機能します。
配布には、2つ以下のフィールドを選択することをお勧めします。もちろん、1つは2つよりも優れています。 分散キーの追加フィールドは、まずハッシュのための追加時間を必要とし、次に(ほとんどの場合)結合の実行時にセグメント間のデータ転送を必要とします。
1つまたは2つの適切なフィールドを選択できない場合、および小さいラベルの場合は、ランダム分布を使用できます。 ただし、このような分布は、単一のレコードではなく、大量のデータ挿入に最適であることを考慮する必要があります。 GreenPlumは、
循環アルゴリズムに従ってデータを配布し、最初のセグメントから開始して、挿入操作ごとに新しいサイクルを開始します。これは、頻繁に小さな挿入を行うと、歪み(データスキュー)につながります。
適切に選択された分布フィールドを使用すると、他のセグメントにデータを送信せずに、すべての計算がセグメントで実行されます。 また、テーブルの最適な結合(結合)を行うには、同じ値を同じセグメントに配置する必要があります。
結合で使用されるフィールドのタイプは、すべてのテーブルで同じでなければなりません。
重要:この場合、クエリ中の負荷も均等に分散されないため、クエリをフィルタリングするために使用されるものを分散フィールドとして使用しないでください。
2.パーティショニング
パーティション化により、
ファクトなどの大きなテーブルを論理的に分離された部分に
分割できます。 Greenplumは、テーブルを物理的に個別のテーブルに分割します。各テーブルは、p。1の設定に基づいてセグメントに分割されます。
テーブルは論理的にセクションに分割する必要があります。そのためには、whereブロックでよく使用されるフィールドを選択します。 実際には、これが期間になります。 したがって、クエリでテーブルに適切にアクセスすると、大きなテーブル全体の一部のみを操作できます。
一般に、パーティション分割はかなりよく知られたトピックであり、パーティション分割と配布に同じフィールドを選択すべきではないことを強調したかったのです。 これにより、リクエストが1つのセグメントで完全に実行されることになります。
それでは、実際に要求に行きましょう。 要求は、特定の
計画に従ってセグメントで実行されます。
3.オプティマイザー
Greenplumには、組み込みのレガシーオプティマイザーとサードパーティのOrcaオプティマイザーの2つのオプティマイザーがあります:GPORCA-Orca-Pivotal Query Optimizer。
リクエストに応じてGPORCAを有効にします。
set optimizer = on;
原則として、 GPORCAオプティマイザーは組み込みより優れています。 サブクエリと
CTEでより適切に動作します(詳細は
こちら )。
最大データフィルタリング(パーティションプルーニングを忘れないでください)と明示的に指定されたフィールドのリストを使用して、CTEの大きなテーブルを呼び出しました。非常にうまく機能します。
たとえば、クエリプランをわずかに変更します。そうしないと、スキャンされたパーティションが表示されます。
標準オプティマイザー: オルカ:
オルカ:
GPORCAでは、パーティション/配布フィールドの更新もできます。 ただし、組み込みオプティマイザーのパフォーマンスが向上する場合があります。 サードパーティのオプティマイザーは統計を非常に要求します。
分析することを忘れないことが重要です。
オプティマイザーがどれほど優れていても、不適切に記述されたクエリはOrcaを拡張しません。
4. whereブロックまたは結合条件のフィールドを使用した操作
フィルターフィールドに適用される関数または結合の条件が
各レコードに適用されることを覚えておくことが重要です。
パーティションフィールドの場合(たとえば、パーティションフィールドのdate_trunc-日付)、この場合はGPORCAでさえ正しく動作できず、
パーティションのクリッピングは機能しません。
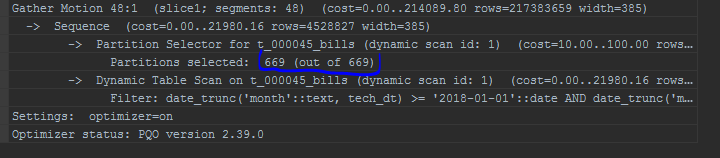
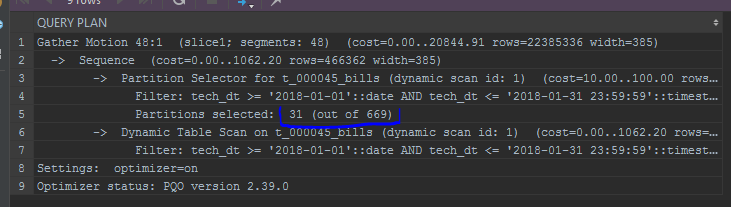 また、パーティションの表示にも注意を向けています。 組み込みのオプティマイザーは、パーティションをリストに表示します:
また、パーティションの表示にも注意を向けています。 組み込みのオプティマイザーは、パーティションをリストに表示します:
同じパーティションフィルター内の定数に関数を慎重に適用します。 例は同じdate_truncです:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCAはこのようなフェイントに完全に対処し、正常に動作しますが、標準オプティマイザーはもう対処しません。 ただし、明示的な型変換を行うことで、それを機能させることができます。
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

そして、すべてが間違っている場合はどうなりますか?
5.モーション
クエリプランで観察できる別のタイプの操作は、モーションです。 そのため、セグメント間のデータの移動にマークを付けました。
- モーションの収集 -ほとんどすべてのプランで表示されます。これは、すべてのセグメントからのクエリ実行の結果を1つのストリーム(通常はマスター)に結合することを意味します。
結合に使用される1つのキーによって分散される2つのテーブルは、データを移動することなく、セグメントですべての操作を実行します。 それ以外の場合、ブロードキャストモーションまたは再配布モーションが発生します。 - ブロードキャストモーション -各セグメントは、データのコピーを他のセグメントに送信します。 理想的な状況では、ブロードキャストは小さなテーブルに対してのみ発生します。
- 再配布の動き -異なるキーに分散された大きなテーブルを結合するために、再配布が実行されてローカルに接続されます。 大きなテーブルの場合、これは非常に高価な操作になる可能性があります。
ブロードキャストと再配布は非常に不利な操作です。 これらは、リクエストが実行されるたびに実行されます。 それらを避けることをお勧めします。 クエリプランでこのような点を見たので、分散キーに注意する価値があります。 また、個別の結合操作が動作の原因です。
このリストは完全なものではなく、主に著者の経験に基づいています。 当時、インターネット上で一度にすべてを見つけることができませんでした。 ここで、リクエストのパフォーマンスに影響を与える最も重要な要因を特定し、これが発生した理由と理由を理解しようとしました。
この記事は、ロステレコムのデータ管理チームによって作成されました