
当社からクラウドリソースをレンタルする多くのクライアントは、仮想チェックポイントを使用しています。 クライアントはさまざまな問題を解決します。誰かがサーバーセグメントのインターネットへのアクセスを制御したり、当社の機器のサービスを公開したりします。 IPSブレードを介してすべてのトラフィックを実行する必要がある人もいれば、ブランチからデータセンターの内部リソースにアクセスするためにVPNゲートウェイとしてCheck Pointが必要な人もいます。 FZ-152に準拠した認証を取得するためにクラウド内のインフラストラクチャを保護する必要がある人もいますが、これについては別途お知らせします。
当直には、チェックポイントのサポートと管理に関与しています。 今日は、仮想環境にチェックポイントのクラスターを展開するときに考慮する必要があるものを説明します。 仮想化、ネットワーク、Check Point自体の設定、および監視のレベルの瞬間に触れます。
私はアメリカを発見することを約束しません-多くはベンダーの推奨事項とベストプラクティスにあります。 しかし、誰も彼らを読まない)、彼らは運転した。
クラスターモード
クラスター内にチェックポイントがあります。 最も一般的なインストールは、アクティブ/スタンバイモードの2つのノードのクラスターです。 アクティブノードで何かが発生すると、非アクティブになり、スタンバイノードがオンになります。 「スペア」ノードへの切り替えは、通常、クラスタメンバ間の同期の問題、インターフェイスの状態、確立されたセキュリティポリシーが原因で発生します。これは、単に機器の負荷が大きいためです。
2ノードクラスターでは、アクティブ/アクティブモードを使用しません。
ノードの1つが落ちた場合、生き残ったノードは単純に二重の負荷に耐えることができず、すべてが失われます。 本当にアクティブ-アクティブが必要な場合は、クラスターに少なくとも3つのノードが必要です。
ネットワークと仮想化の設定
ネットワーク機器では、クラスタメンバーのSYNCインターフェイス間のマルチキャストトラフィックが許可されます。 マルチキャストトラフィックが可能でない場合、同期プロトコル(CCP)がブロードキャストで使用されます。 Check Pointクラスター内のノードは互いに同期します。 変更に関するメッセージは、マルチキャストを介してノードからノードに送信されます。 Check Pointは、非標準のマルチキャスト実装を使用します(非マルチキャストIPアドレスが使用されます)。 このため、Cisco Nexusスイッチなどの一部の機器はこれらのメッセージを理解しないため、ブロックします。 この場合、ブロードキャストに切り替えます。
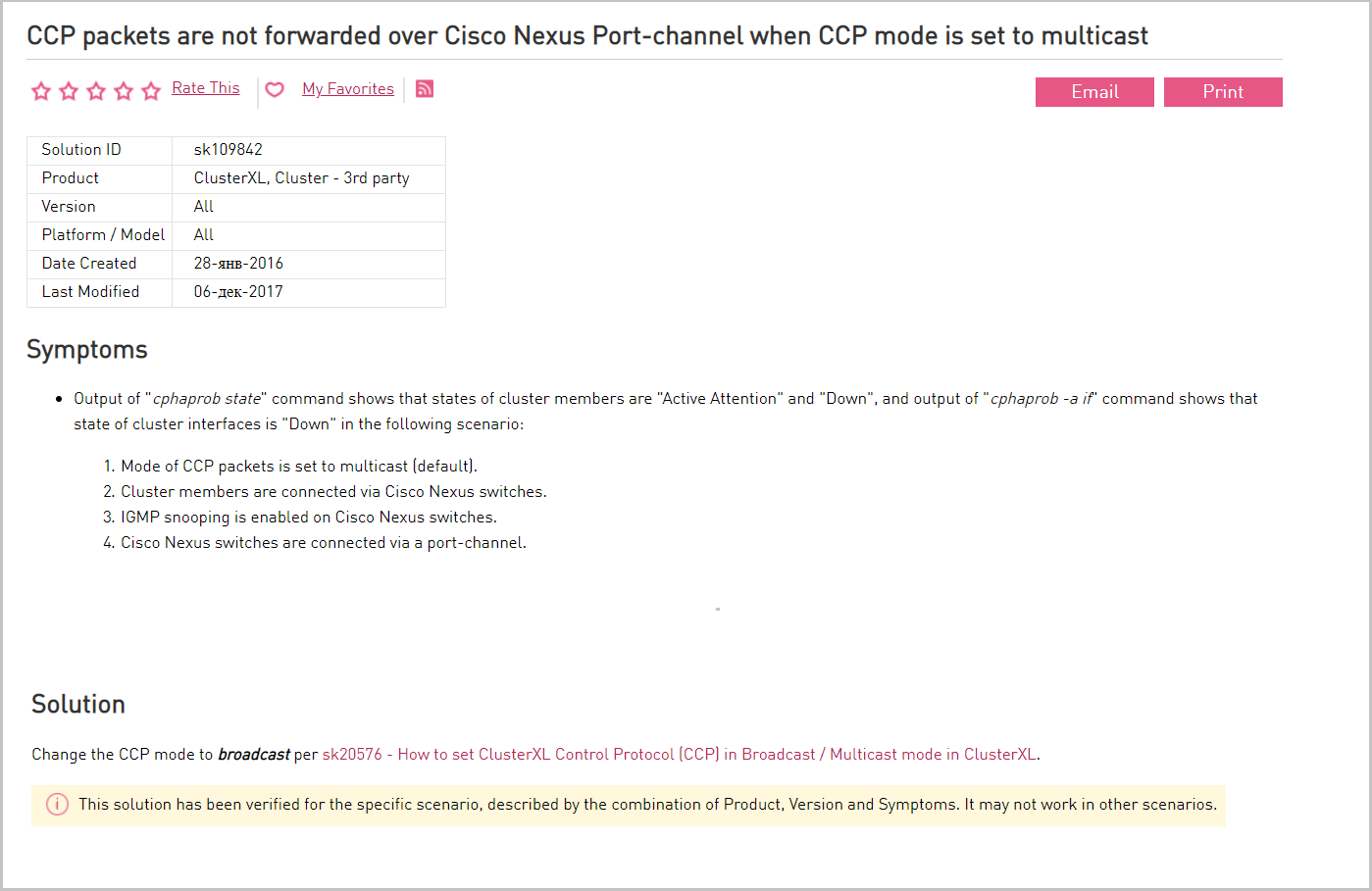 ベンダーポータルでのCisco Nexusとそのソリューションの問題の説明。
ベンダーポータルでのCisco Nexusとそのソリューションの問題の説明。仮想化レベルでは、マルチキャストトラフィックの通過も許可します。 マルチキャストがクラスター同期(CCP)で禁止されている場合は、ブロードキャストを使用します。
Check Pointコンソールで、cphaprob -a ifコマンドを使用すると、CPP設定とその動作モード(マルチキャストまたはブロードキャスト)を確認できます。 動作モードを変更するには、cphaconf set_ccp broadcastコマンドを使用します。
 クラスターノードは異なるESXiホストに存在する必要があります。
クラスターノードは異なるESXiホストに存在する必要があります。 ここではすべてが明らかです。物理ホストが落ちても、2番目のノードは動作し続けます。 これは、DRSの非アフィニティルールを使用して実現できます。
Check Pointが実行される仮想マシンの寸法。 ベンダーの推奨事項は2つのvCPUと6 GBですが、これは、最小帯域幅のファイアウォールがある場合などの最小構成用です。 実装の経験では、複数のソフトウェアブレードを使用する場合、少なくとも4つのvCPU、8 GBのRAMを使用することをお勧めします。
ノードでは、平均150 GBのディスクを割り当てます。 仮想Check Pointを展開すると、ディスクがパーティション分割され、システムスワップ、システムルート、ログ、バックアップ、アップグレードに割り当てるスペースを調整できます。
システムルートを増やす場合、バックアップとアップグレードパーティションも、それらの間の比率を維持するために増やす必要があります。 割合が尊重されない場合、次のバックアップがディスクに適合しない場合があります。
ディスクプロビジョニング-シックプロビジョニングレイジーゼロ化。 Check Pointは多くのイベントとログを生成し、1000秒ごとにエントリが表示されます。 それらの下で、すぐに場所を予約することをお勧めします。 これを行うには、仮想マシンを作成するときに、シックプロビジョニングテクノロジーを使用してディスクを割り当てます。 ディスク作成時に物理ストレージのスペースを確保します。
ESXiホスト間の移行中にCheck Pointの100%リソース予約を構成しました。 Check Pointが展開されている仮想マシンがホスト上の他のVMとリソースを競合しないように、リソースを100%予約することをお勧めします。
その他 R77.30のチェックポイントバージョンを使用します。 RedHat Enterprise Linuxバージョン5(64ビット)を仮想マシンのゲストOSとして使用することをお勧めします。 ネットワークドライバーから-VMXNET3またはIntel E1000。
チェックポイント設定
最新のCheck Pointアップデートがゲートウェイと管理サーバーにインストールされます。 CPUSEを介して更新を確認します。
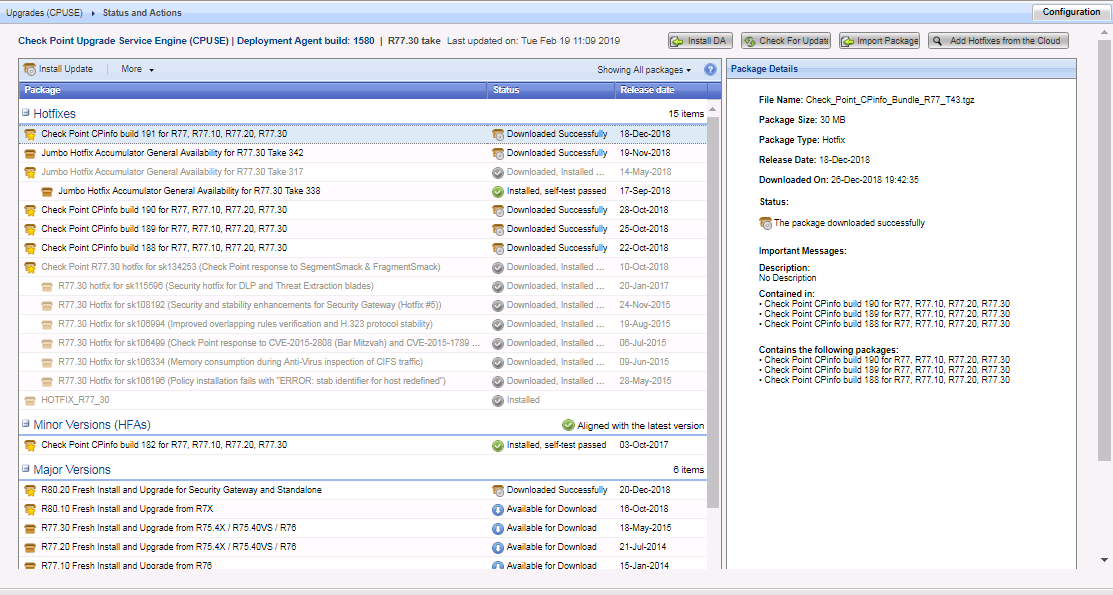
Verifierを使用して、インストールするサービスパックがシステムと競合しないことを確認します。

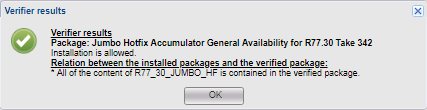
検証者はもちろん良いことですが、微妙な違いがあります。 一部の更新はアドオンと互換性がありませんが、Verifierはこれらの競合を表示せず、更新を許可します。 更新の最後にエラーが表示されますが、そこからのみ更新を妨げるものがわかります。 たとえば、この状況はMABDA_001サービスパック(モバイルアクセスブレード展開エージェント)で発生し、IE以外のブラウザーでJavaプラグインを起動する問題を解決します。
IPSおよびその他のソフトウェアブレード用に毎日自動署名更新を構成しました。 チェックポイントは、新しい脆弱性を検出またはブロックするために使用できるシグネチャをリリースします。 脆弱性には自動的に重大度レベルが割り当てられます。 このレベルと設定されたフィルターに従って、システムは署名を検出するかブロックするかを決定します。 ここでは、正当なトラフィックがブロックされないように、フィルターで無理をせず、定期的にチェックして調整することが重要です。
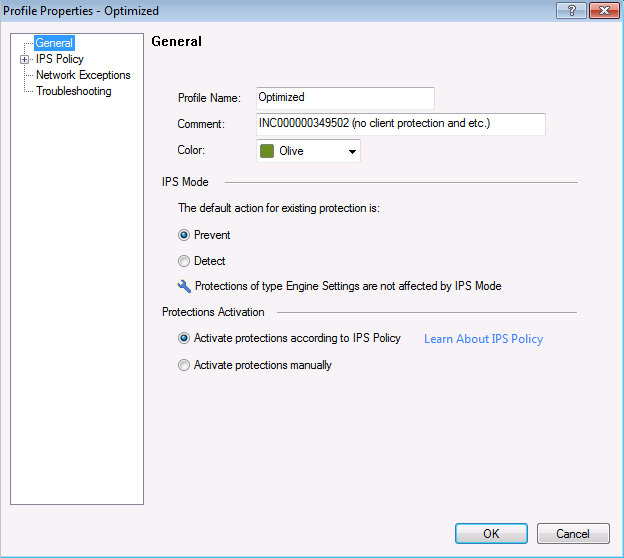 IPSプロファイル。パラメータに応じて署名に関連するアクションを選択します。
IPSプロファイル。パラメータに応じて署名に関連するアクションを選択します。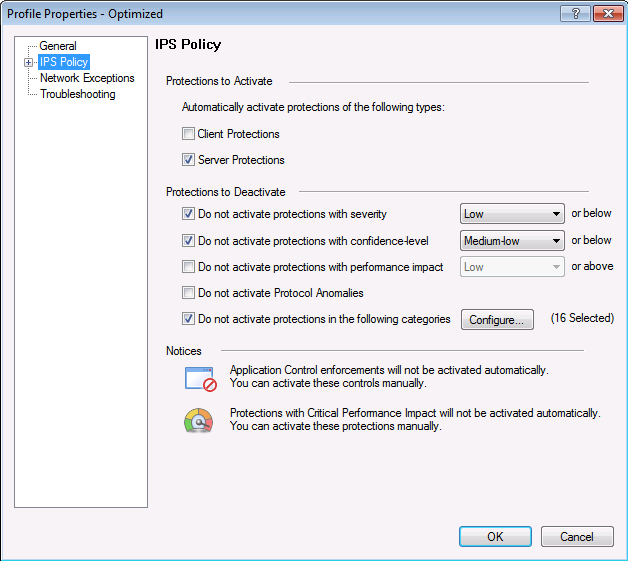 シグニチャ設定に基づくこのIPSプロファイルのポリシー設定:重大度レベル、パフォーマンスへの影響など。Check Pointハードウェアは、NTP時刻同期プロトコルで構成されています。 推奨事項
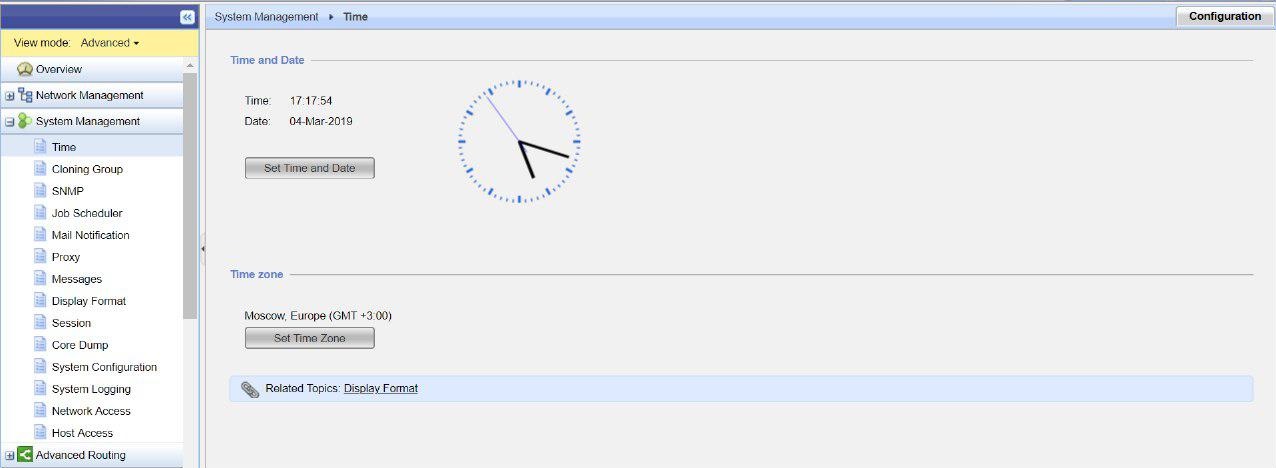
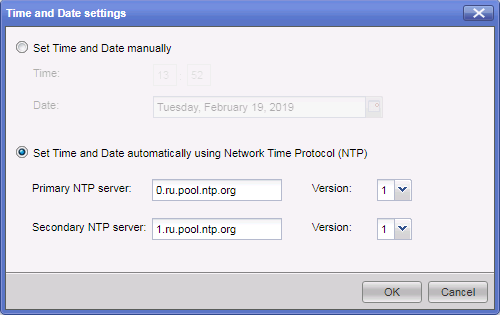
シグニチャ設定に基づくこのIPSプロファイルのポリシー設定:重大度レベル、パフォーマンスへの影響など。Check Pointハードウェアは、NTP時刻同期プロトコルで構成されています。 推奨事項に基づいて、Check Pointは外部NTPサーバーを使用して機器の時刻を同期する必要があります。 これは、gaia Webポータルから実行できます。
不正確な時間設定により、クラスターが同期しなくなる可能性があります。 時間が間違っている場合、興味のあるログエントリを探すのは非常に不便です。 イベントログの各エントリには、いわゆるタイムスタンプが付いています。
 IPS、アプリコントロール、アンチボットなどに関するアラート用にスマートイベントを構成しました。
IPS、アプリコントロール、アンチボットなどに関するアラート用にスマートイベントを構成しました。これは、独自のライセンスを持つ別個のモジュールです。 持っている場合、すべてのソフトウェアブレードとデバイスの動作に関する情報を視覚化するのに便利です。 たとえば、攻撃、IPS操作の数、脅威の重要度、ユーザーがアプリケーションを使用することを禁止するなど。
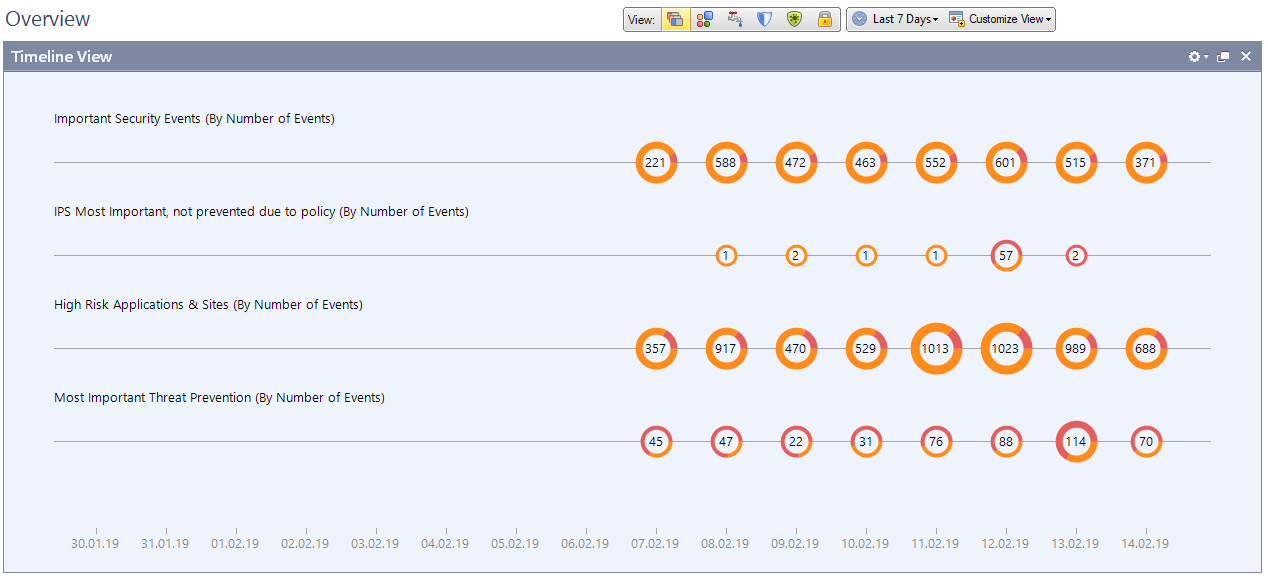
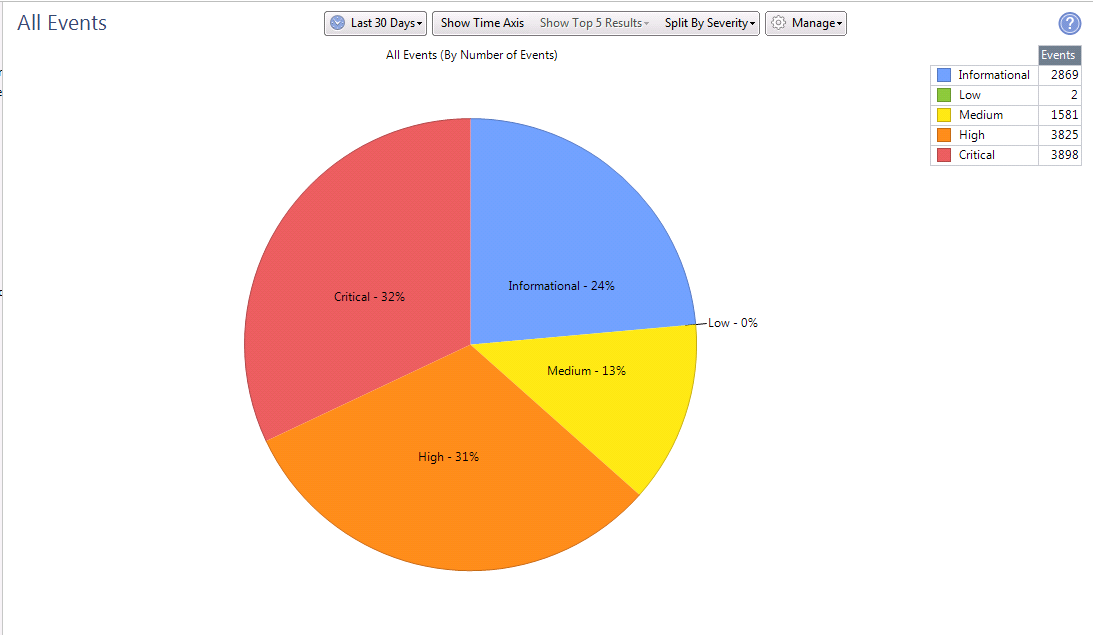 これらは、署名の数とその重要度に応じた30日間の統計です。
これらは、署名の数とその重要度に応じた30日間の統計です。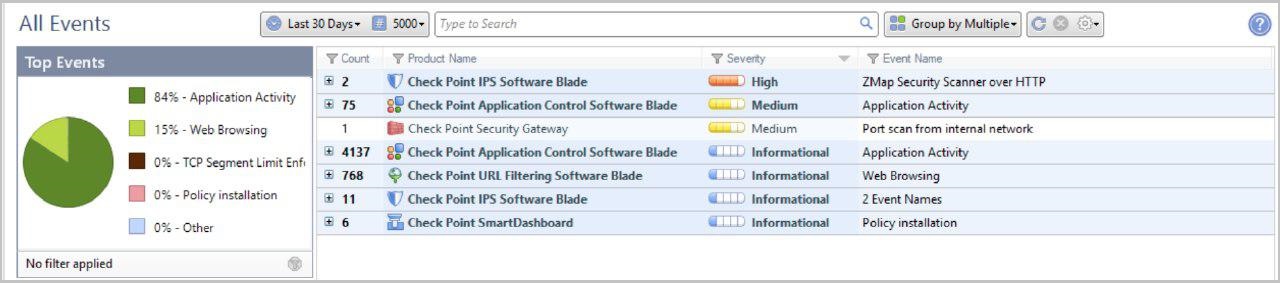 各ソフトウェアブレードで検出されたシグネチャの詳細情報。
各ソフトウェアブレードで検出されたシグネチャの詳細情報。モニタリング
少なくとも次のパラメータを監視することが重要です。
- クラスター状態。
- Check Pointコンポーネントの可用性。
- CPU負荷
- 残りのディスク容量。
- 空きメモリ。
Check Pointには、個別のソフトウェアブレード-Smart Monitoring(個別のライセンス)があります。 その中で、Check Pointコンポーネントの可用性、個々のブレードの負荷、およびライセンスステータスを追加で監視できます。
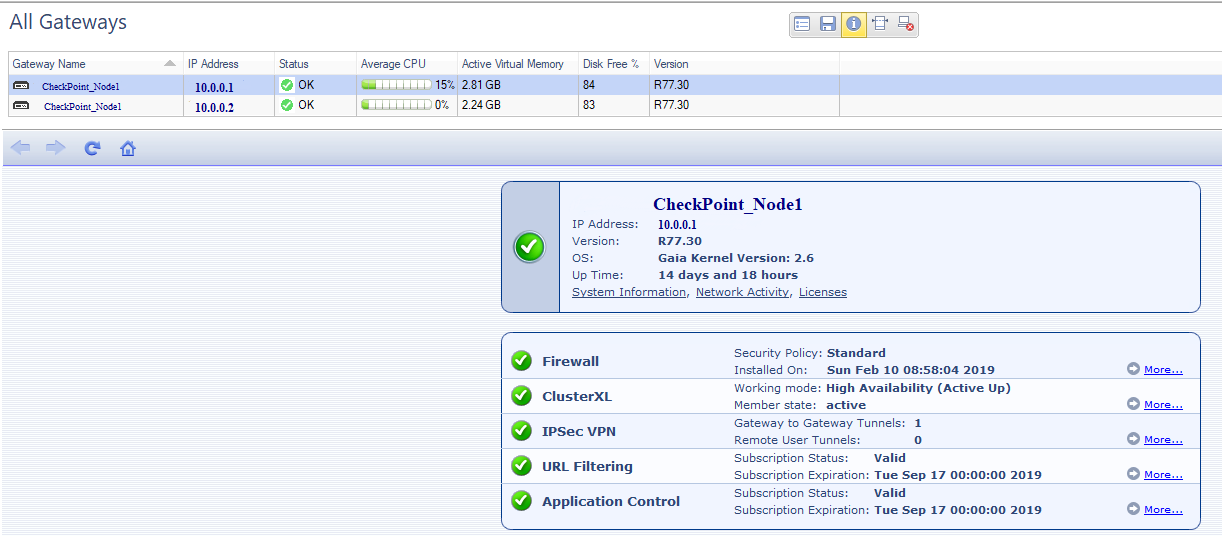
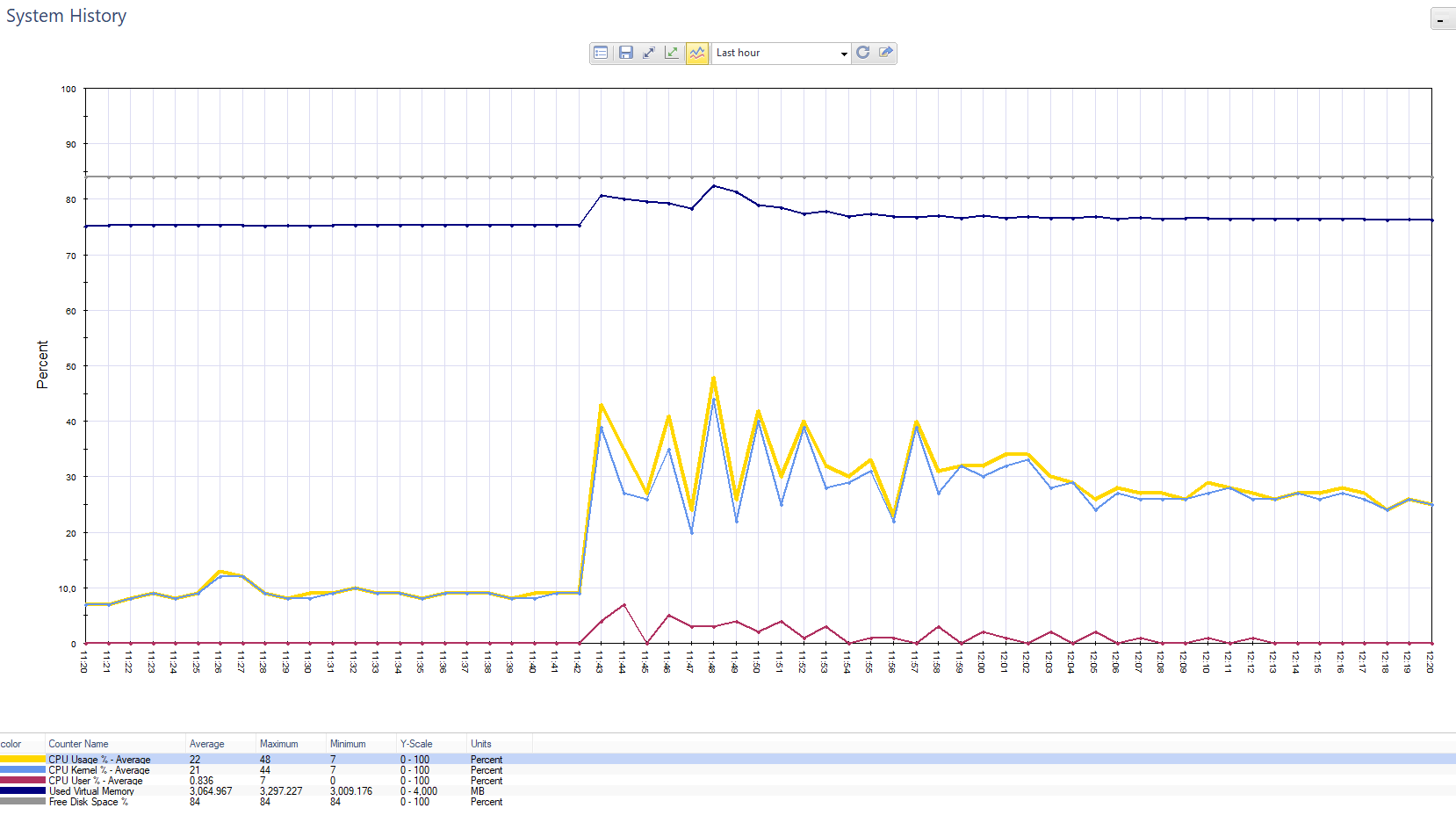 チェックポイント負荷グラフ。 スプラッシュ-これは、プッシュ通知を80万人の顧客に送信した顧客です。
チェックポイント負荷グラフ。 スプラッシュ-これは、プッシュ通知を80万人の顧客に送信した顧客です。 同じ状況でのファイアウォールブレードの負荷のグラフ。
同じ状況でのファイアウォールブレードの負荷のグラフ。監視は、サードパーティのサービスを介して構成することもできます。 たとえば、Nagiosも使用します。ここでは次を監視します。
- 機器のネットワーク可用性。
- クラスターアドレスの可用性
- コアによるCPUロード。 70%以上をダウンロードすると、電子メールアラートが届きます。 このような高負荷は、特定のトラフィック(vpnなど)を示している可能性があります。 これが頻繁に繰り返される場合、おそらく十分なリソースがなく、プールを拡張する価値があります。
- 空きRAM。 80%未満しか残っていない場合は、それについて調べます。
- 特定のパーティション(var / logなど)でのディスクの読み込み。 すぐに詰まる場合は、拡張する必要があります。
- スプリットブレイン(クラスターレベル)。 両方のノードがアクティブになり、それらの間の同期が消えるときの状態を監視します。
- 高可用性モード-クラスターがアクティブ/スタンバイモードであることを監視します。 ノードの状態(アクティブ、スタンバイ、ダウン)を確認します。
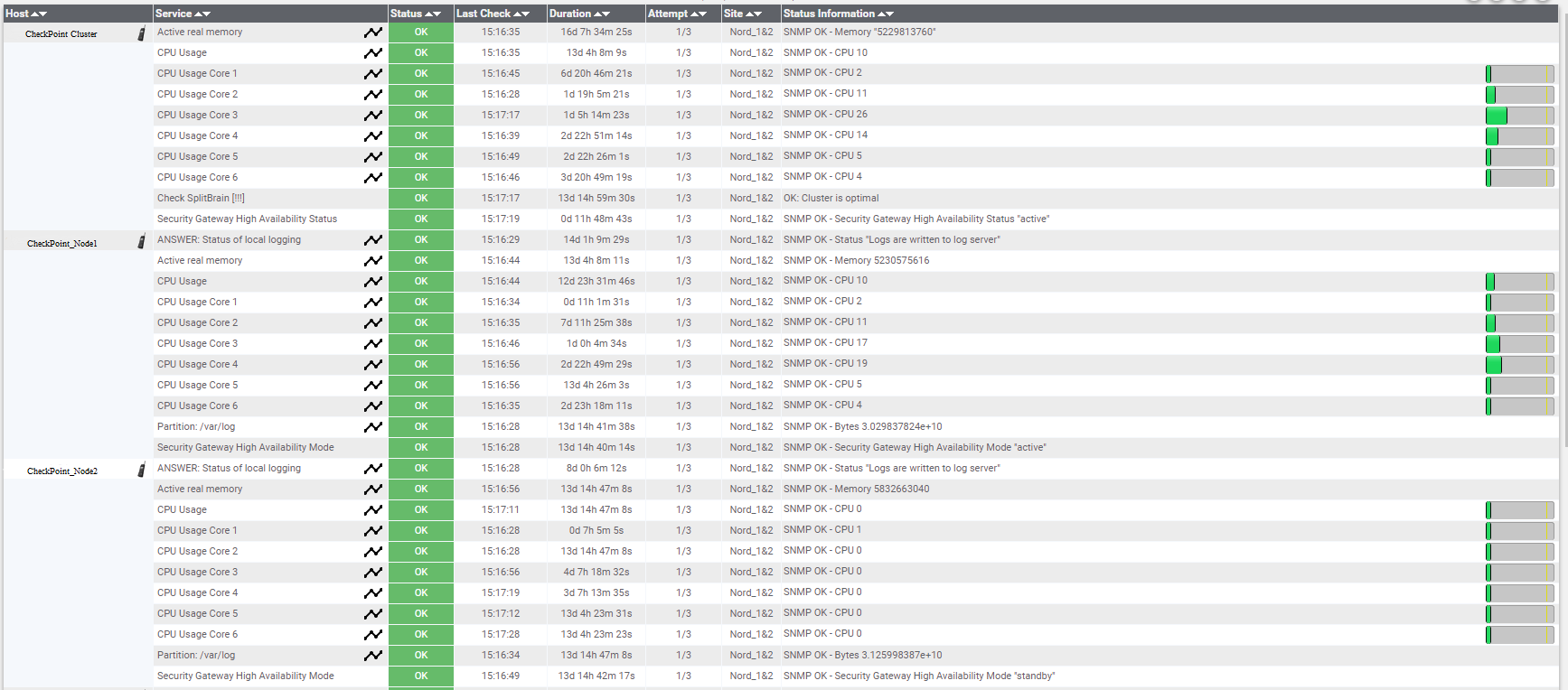 Nagiosの監視オプション。
Nagiosの監視オプション。また、ESXiホストが展開されている物理サーバーのステータスを監視する価値があります。
バックアップ
ベンダー自身が、更新プログラム(Hotfixies)をインストールした直後にスナップショットを取ることを推奨しています。
変更の頻度に応じて、完全バックアップは週に1回または月に1回構成されます。 私たちの実践では、チェックポイントファイルの増分コピーとフルバックアップを週に1回毎日行います。
以上です。 これらは、仮想チェックポイントを展開する際に考慮すべき最も基本的なポイントでした。 ただし、この最小要件を満たしても、作業の問題を回避するのに役立ちます。