どんな人の思考過程も数学化するのは難しいです。 すべてのビジネスタスクは、公式および非公式のドキュメントのセットを生成し、その情報は企業リポジトリに反映されます。 情報プロセスを生成する各タスクは、一連のドキュメントとその処理のロジックを作成しますが、これは企業のストレージ環境ではほとんど形式化されていません。 情報フローをクリアするために、データウェアハウス内に構造が必要です。 「ダーティ」データをクリーニングするタスクを解決するように設計されたOracle Enterprise Data Quality製品が役立ちます。 しかし、これはその使用に限定されません。
1.ランダムデータベースの概念。人の最初のビジネス関係は、申請書、宣言書、雇用契約書、配置申請書、リソース申請書などの公式および非公式の文書で記述されます。 これらのドキュメントはビジネスプロセス間の論理的な接続を作成しますが、原則として、オフィスマネージャーの思考の産物であり、形式化は不十分です。
少なくともいくつかの複雑な最適化のタスクは、正式なルールと非公式のルールを理解するだけでなく、多くの場合、共通の情報ベースに異なる知識をもたらすことです。
定義 ランダムデータベースとは、特定のビジネスプロセスのために人によって処理されるが、ヒューマンファクターの強い影響のために完全に自動的に処理できない事実、ドキュメント、マニュアルノート、正式なドキュメントのセットです。例。 秘書が正式に電話を受けます。 発信者は製品またはサービスに興味があります。 呼び出し元はCRMで知られていません。 質問:スペシャリストに聞くには、発信者は何を言うべきですか?
もっと正確に言えば、責任者の専門家がこの種の活動の準備ができていない場合、秘書のビジネス指示はビジネスについての正式な対話をどの程度許可しますか?
再びランダムデータベースの定義に到達することがわかりました。
秘書が知るよりも多くの事実が含まれているのかもしれません。 ただし、その中で受信される情報は不要ではありません。 一般に、ランダムデータベースのランダムな事実が正式なシステムの入力に到達すると、情報の過負荷などの事態が発生し、すべての情報の過負荷が秘書だけでなく会社全体のパフォーマンスに影響を与える可能性があります。
処理の目的で使用される場合、この情報の状態を読み取るマシンは、人とは反対の状態、つまり情報過多の論理的結論に基づいて生成されます。 ヒューマンロジックはより柔軟です。
2.定義の実際のタスクへの適用。ランダム商品の値札が著しく高いまたは低い店舗を想像してください。 このストアを経験の浅い買い物リストの先頭に置いた場合、最も人気のある商品の価格は5〜7(または3)のままになります。この価格は合計小切手のサイズに影響する可能性があります。 買い手が最もよく思い出す価格の商品リストを知ることができた場合、残りの価格は比較的広い範囲で変動する可能性があることがわかります。
四旬節の前に、肉が最初は急激に安くなり、それから価格が急激に上昇し、そして消えてしまう理由を疑問に思ったことはありますか? 需要がゼロになる可能性のある製品の価格は、最初に人為的に加熱され、次に一定の需要を通過すると修正が始まり、しばらくすると力強く上昇します。
データ市場にもほぼ同様の状況が存在します。 最も有用な情報は、ほとんどの場合、その適用可能性と抽出可能性に関する二次仮説によって隠されています。
比較的保護されていないリソースに5000〜7000人にとって興味深い情報をレイアウトするだけで十分です。コピーアンドペーストサイトがあります。
または、「誰が私を呼んだのか?」という電話コードの有名なゲーム。 Runetの約1000のサイトは、検索結果でやや高いために、さまざまなオペレーターの電話番号のみで構成されており、ドメイン名を販売し、広告をより高価にしようとしています。
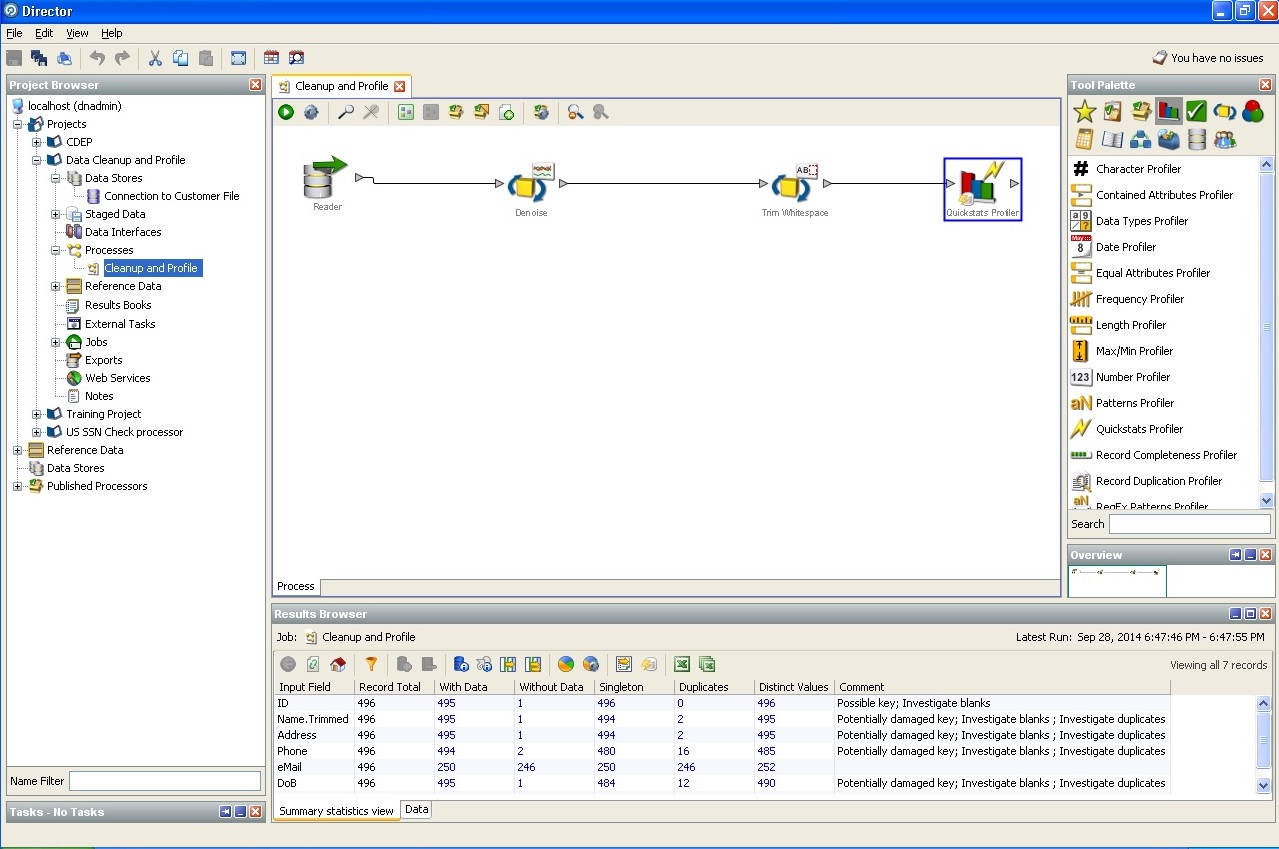
3.「ダーティ」データを扱う際の問題の価格。この記事の著者の調査によると、各プロジェクトの労働リソースの最大10%が特定のデータクリーニング手順の作成に流用されています。 完全に平凡なタイプと長さ、つまり、一意の識別子、データベース整合性ルールとビジネス整合性ルール、定量的および定性的な単位スケール、労働単位システムおよびその他の状態、影響、移行などにとらわれない場合論理的で深刻なビジネス分析。 要件の形式化では、リポジトリの構築とフロントエンドの問題解決の両方のために、事実と次元の関係を形式化する必要が生じます。
ETLプロセスがストレージの稼働時間の70%を占有する場合、200,000人の顧客の条件付きストレージのデータの正しいクリーニングでリソースの5〜7%を節約することは、すでに良いボーナスですか?
既製システムの「ダーティ」データの問題について少し説明します。 祝日を祝い、10,000人の顧客にメールで送ったとしましょう。 名前、姓を間違えたり、フォームに間違ってフォームに入力した場合、メールボックスに最高のはがきで手紙を投げる人は何人いますか? あなたの努力の価格は、どんなユーザーの気分もゼロに減らすことができます!
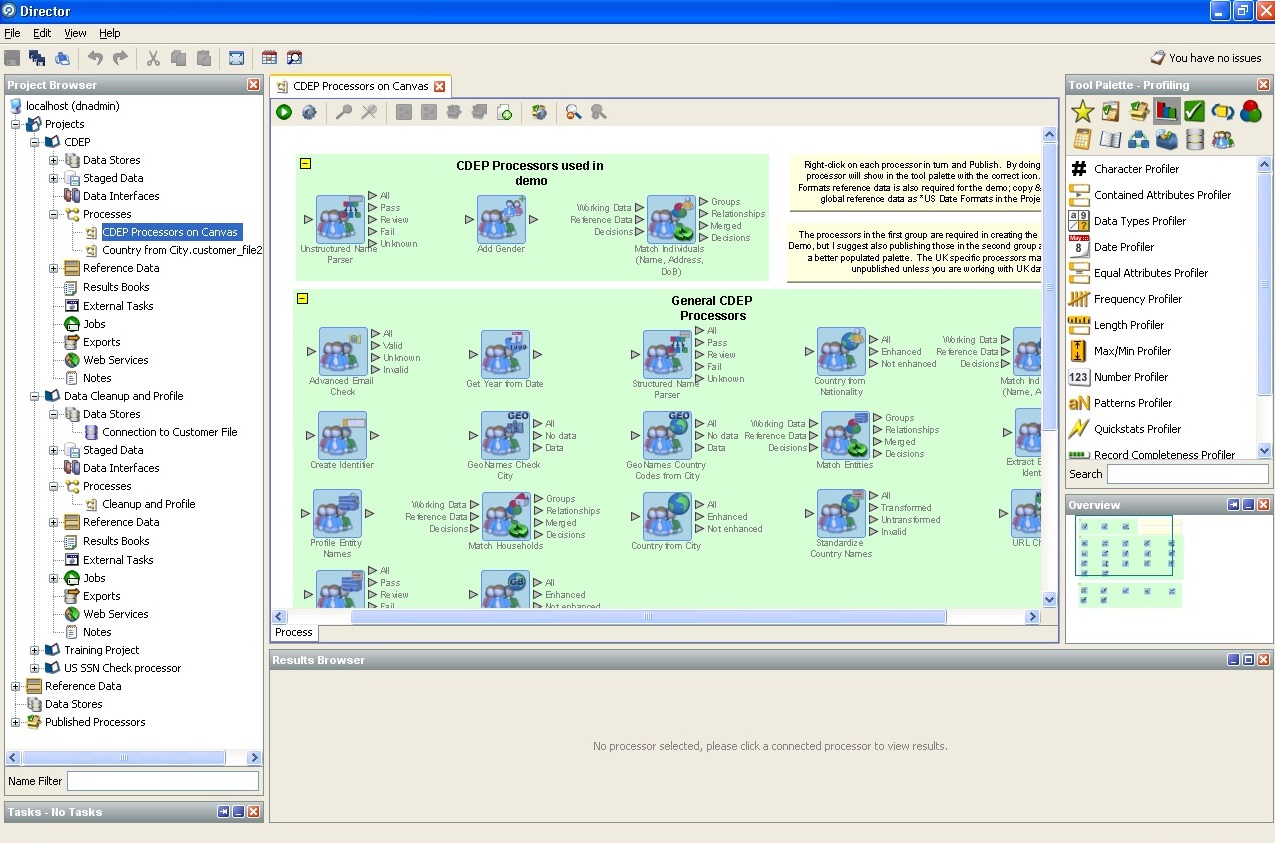
4. Oracle Enterprise Data Quality-企業ストレージの盾と剣。提供するスクリーンショットは、Oracle Enterprise Data Qualityの機能を説明しています。
だから、誰かがあなたのデータベースやテキスト文書に水をこぼすようにしてください。
以下は、標準プロセッサ(の使用を許可する論理ユニット)のリストです。
特定の仮説のデータに、または必要なものを検索するには):
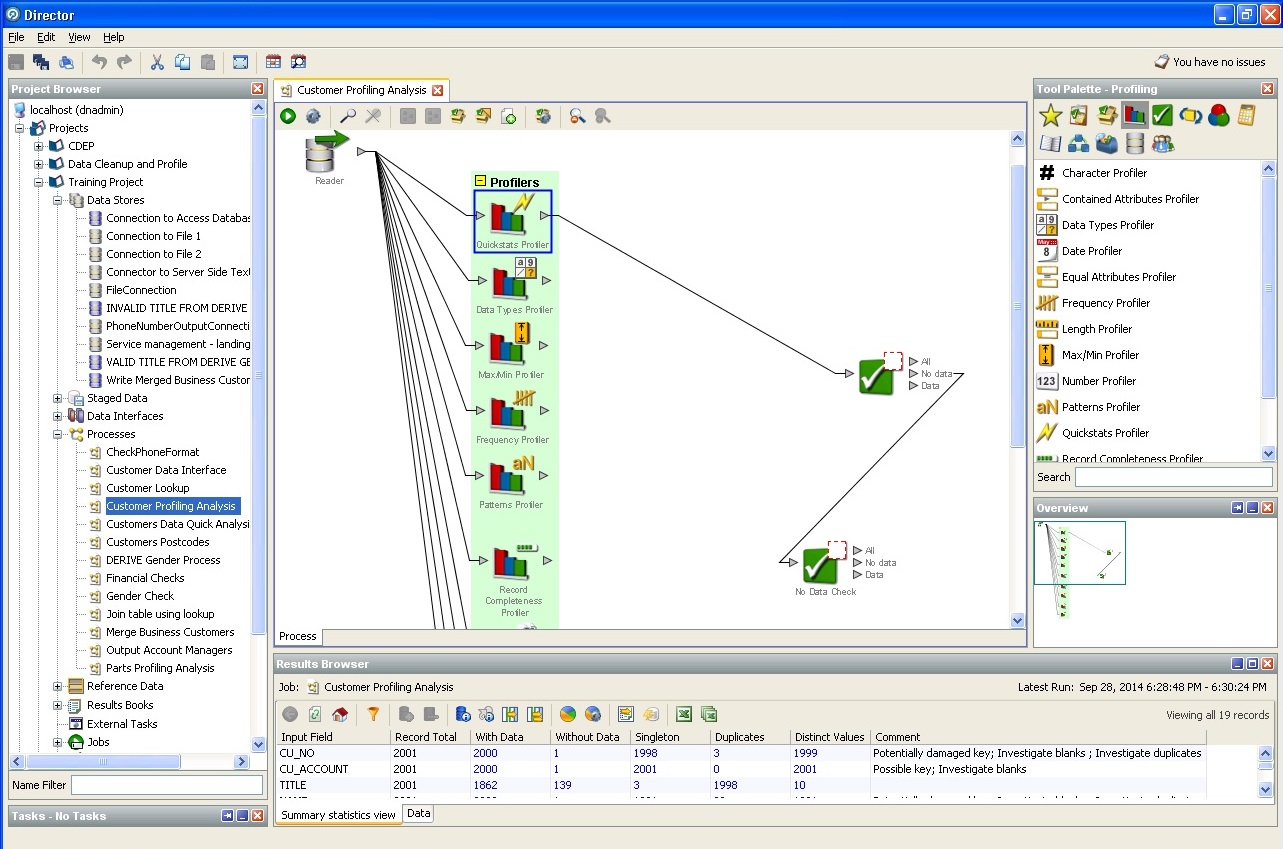
ランダムデータベースプロファイラーアクション:
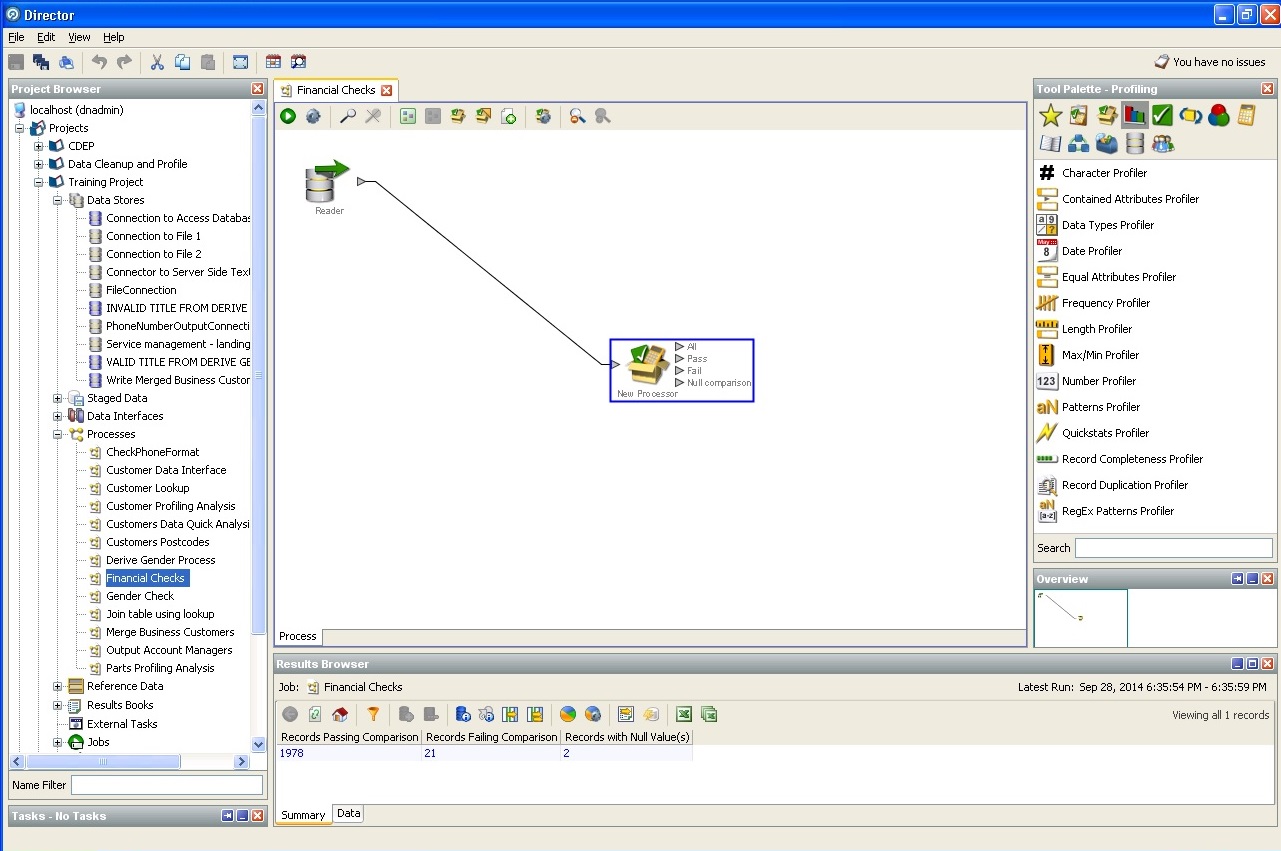
金融ソルベンシーの基本監査:
郵便番号を使用する:
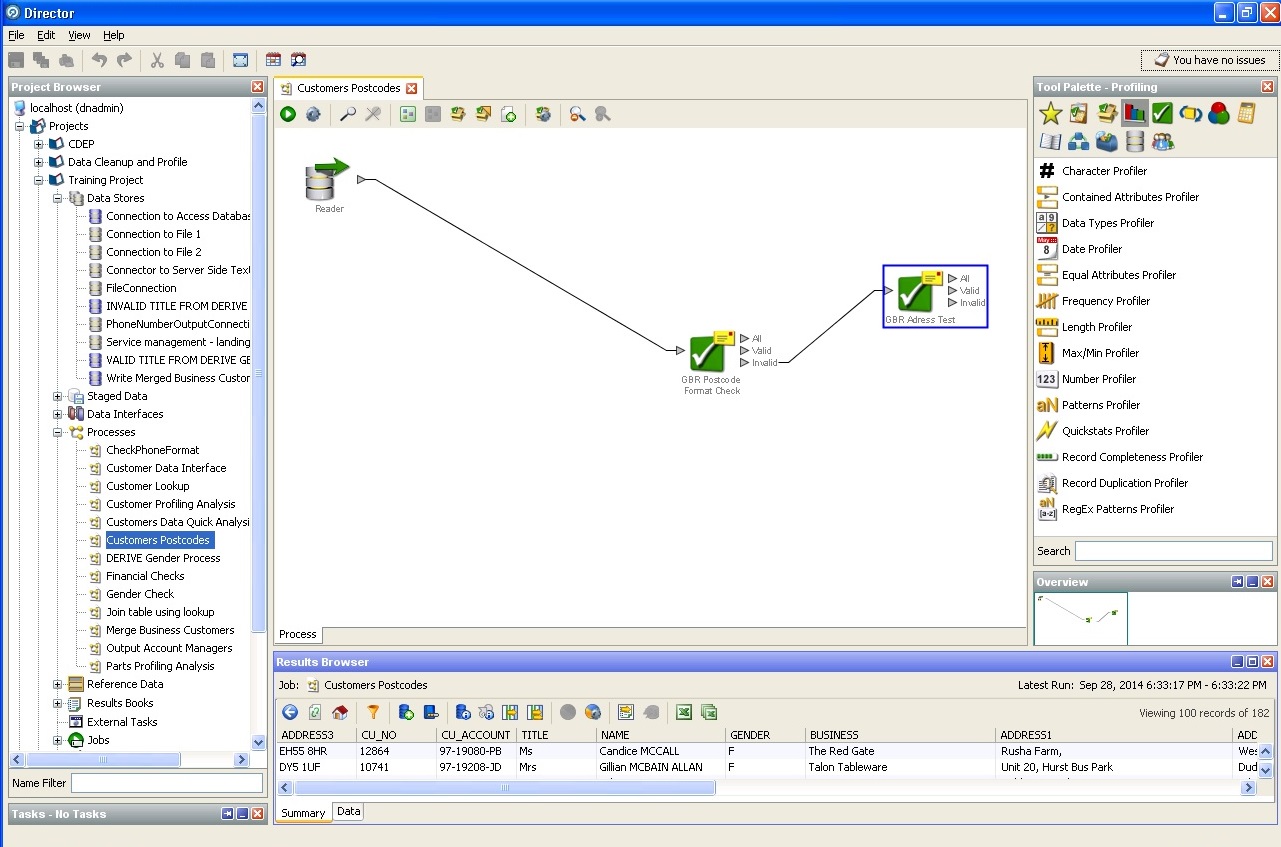
郵送先住所のクリーニング:
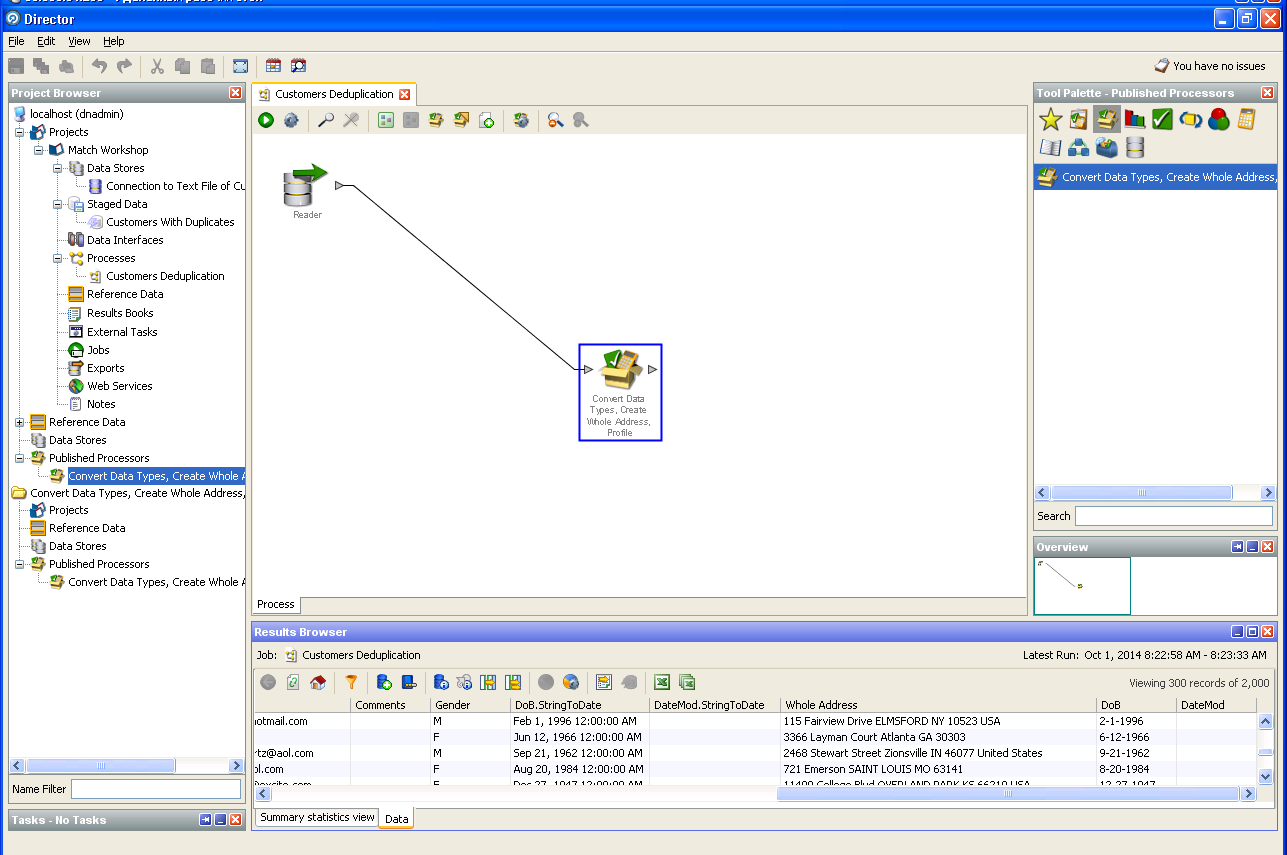
ユーザーデータの消去:
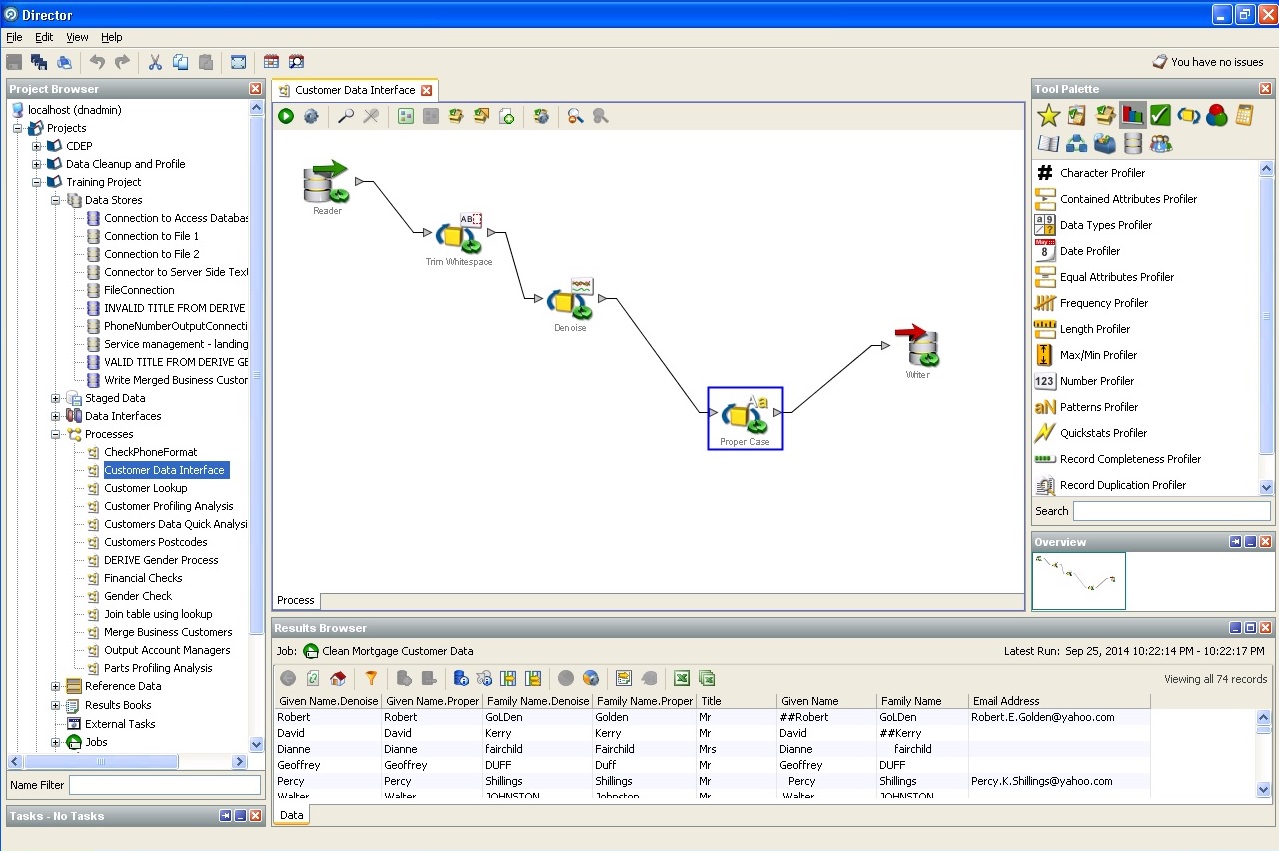
1つまたは別の信頼区間へのレコードの割り当て:
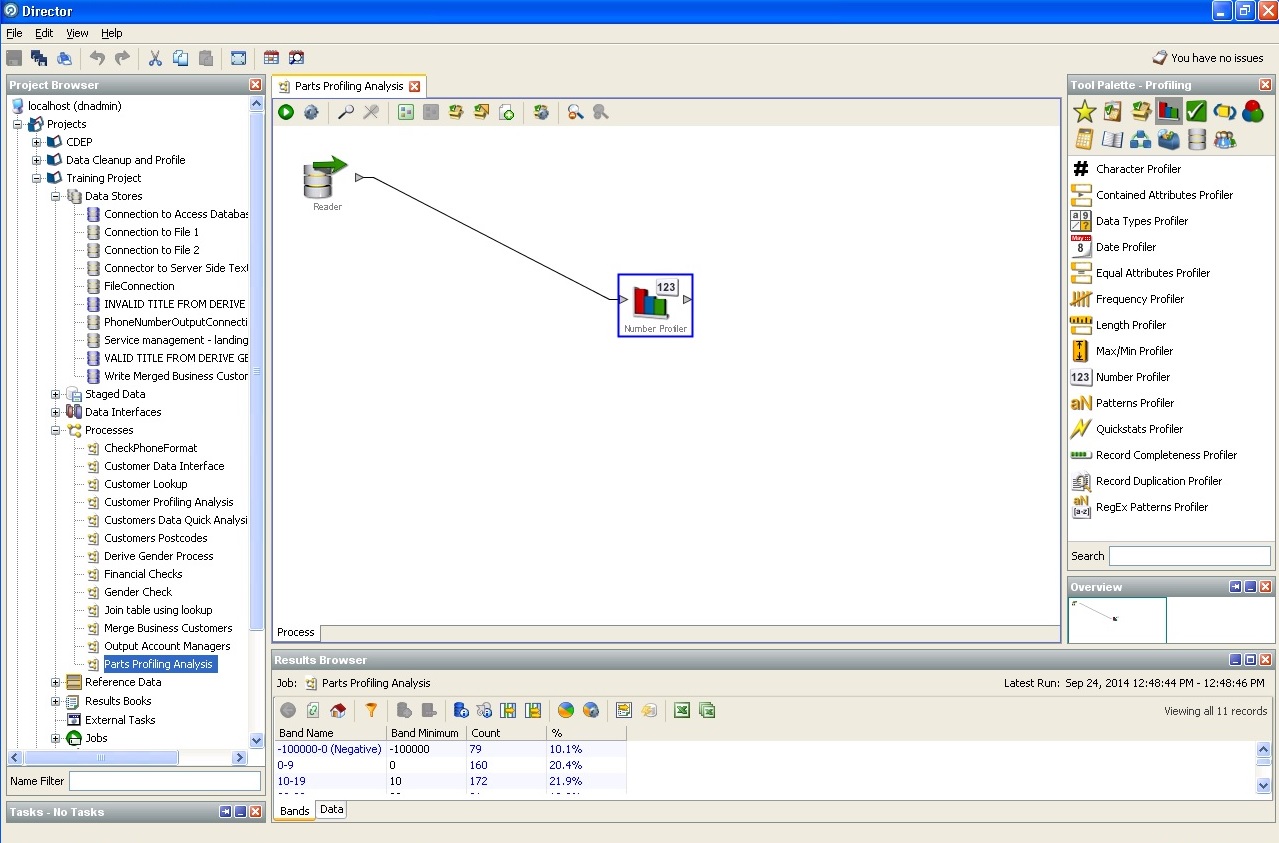
間接データからユーザーの性別を判断する:
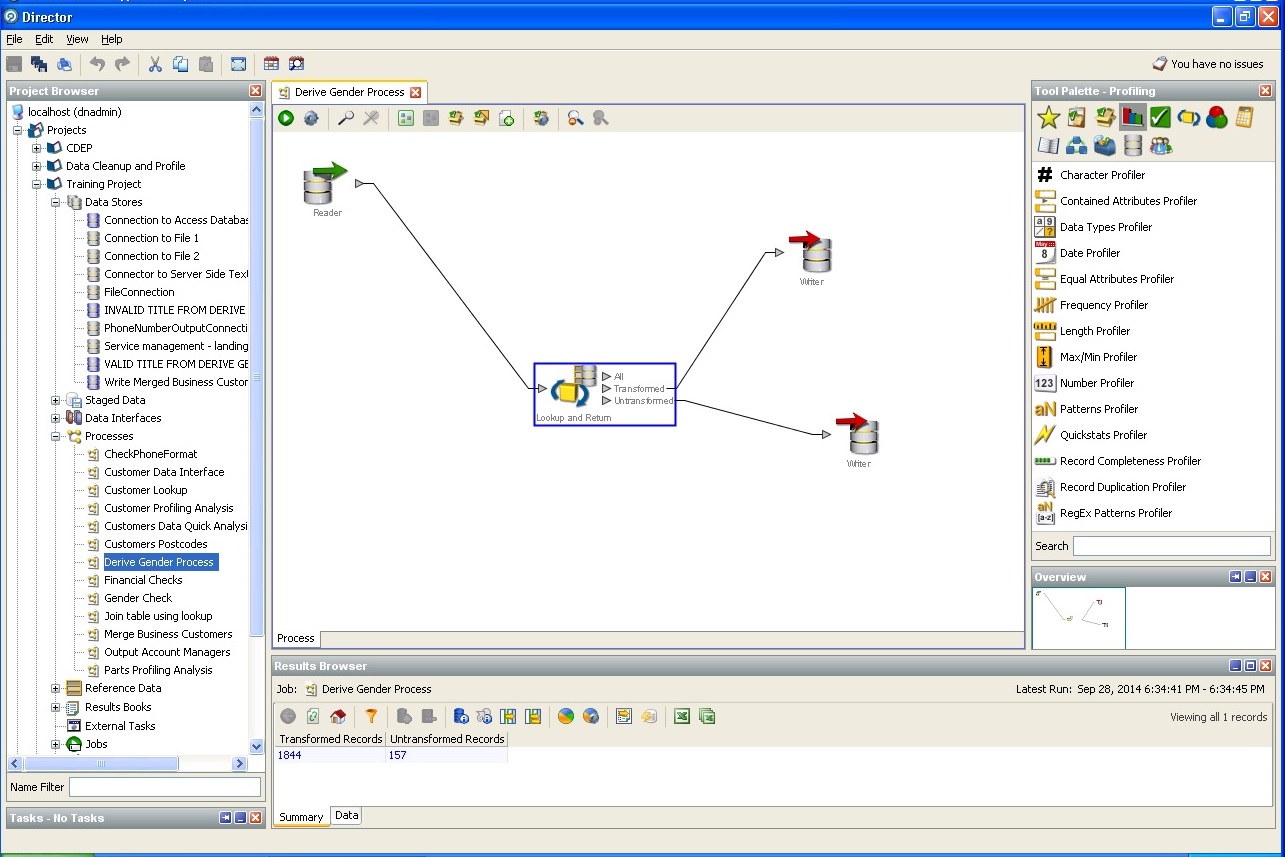
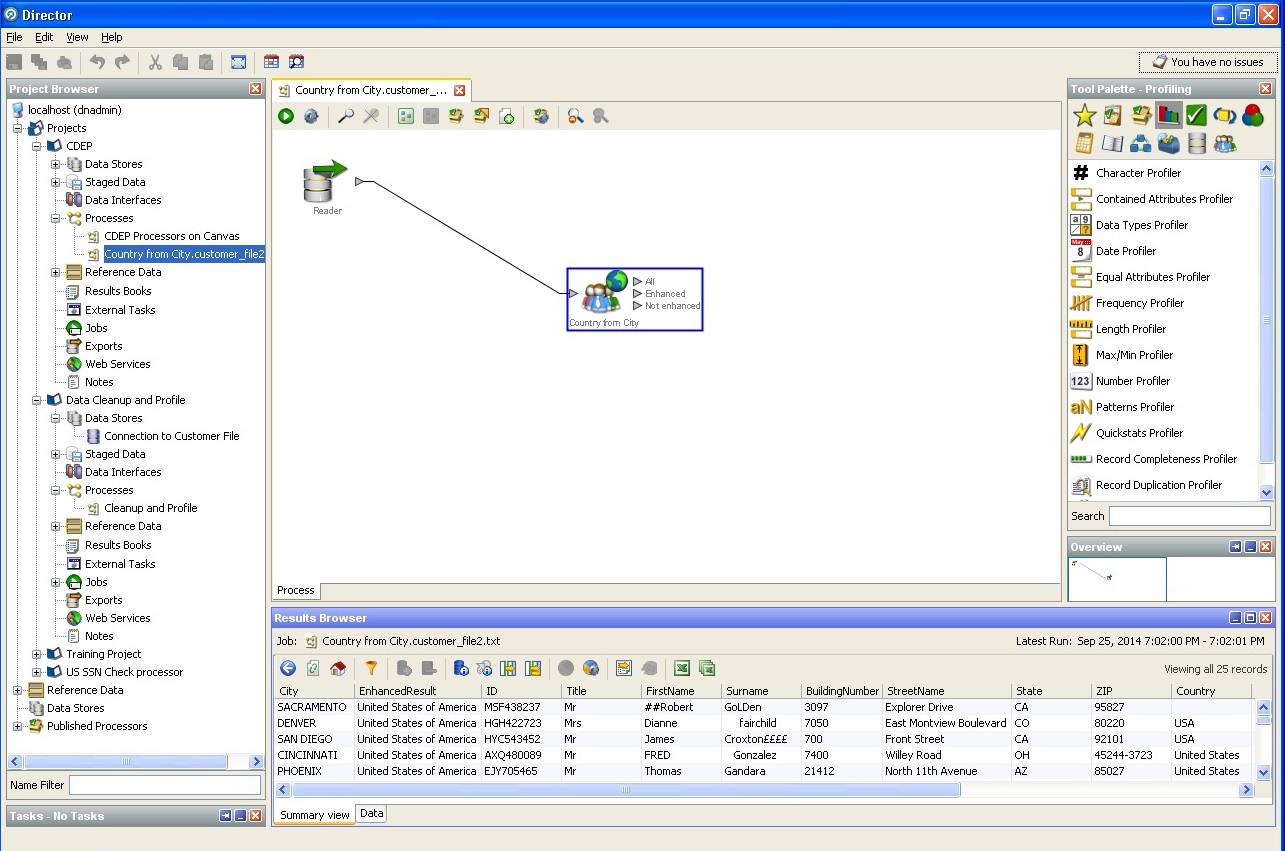
都市および国、州の定義:
ランダムデータベースでの最も単純なキー検索:
ユーザーデータの重複排除:
 5. Oracle EDQの作業結果についての面白い観察。
5. Oracle EDQの作業結果についての面白い観察。作家と詩人の文学への貢献を比較する原則の1つは、彼らの詩と文学の辞書を比較することです。 Oracle EDQ、Python、Javaで既製のソリューションをテストするために、自由時間でコンパイルされた多くの辞書を提供します。 コメントの言語学者が結果を投稿してくれれば感謝します。
番号p.p.
| 言葉
| 発生頻度
|
ライオン
トルストイ、戦争と平和。 頻度表のフラグメント
著作権辞書。
| 私。
ブロツキー、ウラニア。
| 私。
Brodsky Complete works、周波数辞書の断片
著者。
| N.
ネクラソフ、全コレクションの周波数辞書の断片
エッセイ。
|
1。
| そして
| 10351
| で
1037
| で
5745
| そして
3420
|
3。
| で
| 5185
| そして
647
| そして
4500
| で
2108
|
4。
| じゃない
| 4292
| じゃない
391
| じゃない
3022
| じゃない
1726
|
5。
| なに
| 3845
| に
341
| に
2239
| 私は
1040
|
6。
| 彼は
| 3730
| どうやって
329
| どうやって
1758
| と
883
|
7。
| に
| 3305
| と
237
| と
1674
| に
854
|
8。
| と
| 3030
| なに
168
| なに
1531
| どうやって
763
|
9。
| どうやって
| 2097
| に
148
| そして
1200
| なに
693
|
10。
| 私は
| 1896
| から
147
| 私は
1040
| 彼は
644
|
11。
| 彼の
| 1882
| から
104
| に
922
| あなたは
475
|
12。
| に
| 1771
| 私は
90
| から
810
| でも
472
|
13。
| それから
| 1600
| どこで
88
| すべて
748
| でも
449
|
14。
| 彼女は
| 1564
| より
88
| によって
744
| だから
383
|
15。
| でも
| 1234
| のために
76
| あなたは
721
| に
367
|
16。
| それは
| 1208
| によって
74
| で
713
| すべて
344
|
17。
| 言った
| 1135
| でも
72
| のために
687
| のために
313
|
18。
| だった
| 1125
| どちらでもない
70
| から
635
| 私に
309
|
19。
| だから
| 1032
| するだろう
69
| でも
617
| はい
294
|
20。
| 王子
| 1012
| それから
67
| 彼は
592
| 彼の
275
|
21。
| のために
| 985
| あなたは
67
| でも
584
| それから
232
|
22。
| でも
| 962
| について
66
| それから
540
| だった
229
|
23。
| 彼に
| 918
| でも
63
| について
538
| によって
224
|
24。
| すべて
| 908
| そこにある
61
| それは
524
| いや
223
|
25。
| によって
| 895
| 私は
61
| 私は
489
| どちらでもない
222
|
26。
| 彼女
| 885
|
| でも
463
| について
213
|
27。
| から
| 845
|
| どこで
449
| 彼らの
212
|
28。
|
|
|
| より
443
| から
209
|
29。
|
|
|
| A
428
| から
207
|
30。
|
|
|
| 同じ
422
| 私たちは
206
|
結論:個々の単語の頻度に関する過去100年間のロシア語の統計は、詩人の間ではあまり変化していません-単語は「メロディアス」です。 ちなみに、Daria Dontsovaの統計は、完全な作品の頻度辞書の分野でLeo Tolstoyとほぼ一致しています。
6.結論としてのいくつかの正式な計算。約6万人のイワノフ・イワノフ・イワノビッチが私たちの国に住んでいます。 仮に、平均的なデータベースに100個のテーブルが保存され、各テーブルに10個のキーフィールドがあり、各キーが6万個の値を取ることができると仮定すると、データベース内の一意のキー状態の総数は約6,000万です。 1つのテーブルに2つのキーが混在していても、1つのテーブルに最大20の一意の状態を生成できます。 合計すると、最大で数千個が一意の状態のベースに達する可能性があります。 開発時間の10%とETL実行時間の5〜7%を費やしてこのような些細なことをキャッチすることは許されない贅沢だということに同意しますか?
UPD1作業中の重要度の高いディレクトリごとに制御システムをドラッグすることにうんざりしている場合は、MDM(マスターデータ管理)システムが役立ちます。 もちろん、フリーソフトウェアのバージョンを含むそのようなシステムを市場に提供しています。
UPD2多くの場合、会議で「より安価なデータ品質管理システムを作成する方法」という質問があります。 この記事は、EDQ機能をいくらか簡略化したこの問題の簡単な紹介とみなしてください。 はい、そしてまだ、たくさんのODI + EDQを使用して非常にうまくやることができますが、これはさらにナレーションの対象となります。