告知
同僚、夏の半ばに、キューシステムの設計に関する別の記事シリーズ「VTrade Experiment」-トレーディングシステムのフレームワークを作成する試みをリリースする予定です。 このサイクルでは、取引所、オークション、店舗を構築する理論と実践を分析します。 記事の最後で、私が最も興味のあるトピックに投票することを提案します。

これは、Erlang / Elixir分散型リアクティブアプリケーションサイクルの最後の記事です。 最初の記事では、リアクティブアーキテクチャの理論的基礎を見つけることができます。 2番目の記事では、このようなシステムを構築するための基本的なパターンとメカニズムについて説明します。
今日は、コードベースとプロジェクト全般の開発の問題を提起します。
サービス組織
実際には、サービスを開発するとき、多くの場合、1つのコントローラーで複数の対話パターンを組み合わせる必要があります。 たとえば、プロジェクトのユーザープロファイルを管理するタスクを解決するユーザーサービスは、req-resp要求に応答し、pub-subを介してプロファイルの更新を報告する必要があります。 このケースは非常に簡単です。メッセージングの背後には、サービスのロジックを実装し、更新を公開する1つのコントローラーがあります。
フォールトトレラントな分散サービスを実装する必要がある場合、状況は複雑です。 ユーザーの要件が変更されたとします:
- これで、サービスはクラスターの5つのノードでリクエストを処理するはずです。
- バックグラウンド処理タスクを実行できる、
- また、プロファイル更新サブスクリプションリストを動的に管理できます。
注:データの一貫したストレージとレプリケーションの問題は考慮していません。 これらの問題は以前に解決されており、システムには信頼性の高いスケーラブルなストレージレイヤーが既にあり、ハンドラーには相互作用するメカニズムがあると仮定します。
ユーザーサービスの正式な説明はより複雑になりました。 プログラマーの観点からは、メッセージングの変更の使用は最小限です。 最初の要件を満たすために、req-resp交換ポイントのバランスを調整する必要があります。
バックグラウンドタスクを処理する要件が頻繁に発生します。 ユーザーの場合、これはユーザー文書の確認、ダウンロードしたマルチメディアの処理、またはソーシャルサービスとのデータの同期です。 ネットワーク。 これらのタスクは、クラスター内で何らかの形で分散され、進行を制御する必要があります。 したがって、2つのソリューションがあります。前の記事のタスク配布テンプレートを使用するか、適切でない場合は、ハンドラーのプールを管理するために必要なカスタムタスクスケジューラを作成します。
ポイント3では、pub-subテンプレートの拡張が必要です。 また、実装のために、pub-sub交換ポイントを作成した後、サービスの一部としてこのポイントのコントローラーをさらに起動する必要があります。 したがって、サブスクリプションを処理し、メッセージング層からユーザー実装にサブスクライブ解除するロジックを採用しているようです。
その結果、タスクを分解すると、要件を満たすために、異なるノードで5つのサービスインスタンスを実行し、追加のエンティティ(サブスクライブを担当するpub-subコントローラー)を作成する必要があることがわかりました。
5つのハンドラーを実行するために、サービスコードを変更する必要はありません。 追加のアクションは、交換ポイントでバランシングルールを設定することだけです。これについては後で説明します。
また、複雑さを追加しました:pub-subコントローラーとカスタムタスクスケジューラーは1つのコピーで動作するはずです。 繰り返しになりますが、基本的なメッセージングサービスは、リーダーを選択するためのメカニズムを提供する必要があります。
リーダーズチョイス
分散システムでは、リーダーの選択は、負荷の分散処理の計画を担当する唯一のプロセスを任命する手順です。
集中化の傾向がないシステムでは、普遍的なコンセンサスアルゴリズムとpaxosやraftなどのアルゴリズムがアプリケーションを見つけます。
メッセージングはブローカーであり中心的な要素であるため、彼はすべてのサービスコントローラー(リーダーシップの候補者)について知っています。 メッセージングは、投票なしでリーダーを任命できます。
交換ポイントを開始して接続すると、すべてのサービスがシステムメッセージ#'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} 。 LeaderPid pid現在のプロセスのpid一致する場合、リーダーとして割り当てられ、 Serversリストにはすべてのノードとそのパラメーターが含まれます。
新しいクラスターノードが表示されて切断されると、すべてのサービスコントローラーが#'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts}および#'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} 。
したがって、すべてのコンポーネントはすべての変更を認識し、クラスター内では常に1人のリーダーが保証されます。
仲介業者
仲介者を使用して複雑な分散処理プロセスを実装し、既存のアーキテクチャを最適化すると便利です。
サービスのコードを変更せず、たとえば、追加の処理、ルーティング、またはログメッセージのタスクを解決しないために、サービスの前にプロキシプロセッサを有効にして、追加のすべての作業を実行できます。
pub-sub最適化の典型的な例は、市場価格の変更などの更新イベントを生成するビジネスコアと、Webクライアントにwebsocket APIを提供するN層のアクセスレイヤーを備えた分散アプリケーションです。
「額」を決定した場合、顧客サービスは次のようになります。
- クライアントはプラットフォームとの接続を確立します。 トラフィックを終了するサーバー側で、この接続を処理するプロセスが開始されます。
- サービスプロセスのコンテキストでは、更新の承認とサブスクリプションが行われます。 プロセスは、トピックのsubscribeメソッドを呼び出します。
- カーネルでイベントが生成された後、接続を処理するプロセスに配信されます。
「ニュース」トピックの購読者が50,000人いると想像してください。 サブスクライバーは、5つのサーバーに均等に分散されます。 その結果、交換ポイントに到着する各更新は50,000回複製されます。つまり、サーバー上のサブスクライバの数に応じて、各サーバーに10,000回複製されます。 効果的なスキームではありませんか?
状況を改善するために、交換ポイントと同じ名前を持つプロキシを導入します。 グローバル名レジストラは、名前で最も近いプロセスを返すことができるはずです。これは重要です。
アクセスレイヤーのサーバーでこのプロキシを実行すると、websocket apiを提供するすべてのプロセスは、カーネル内の元のpub-sub交換ポイントではなく、それをサブスクライブします。 プロキシは、一意のサブスクリプションの場合にのみカーネルにサブスクライブし、着信メッセージをそのすべてのサブスクライバーに複製します。
その結果、50,000個ではなく、5個のメッセージがカーネルとアクセスサーバー間で送信されます。
ルーティングとバランシング
必須
現在のメッセージングの実装には、7つのクエリ分散戦略があります。
default 要求はすべてのコントローラーに渡されます。round-robin 。 コントローラー間でリクエストを繰り返し処理し、周期的にリクエストを分配します。consensus 。 サービスを提供するコントローラーは、リーダーとフォロワーに分けられます。 リクエストはリーダーにのみ渡されます。consensus & round-robin 。 グループにはリーダーがいますが、リクエストはすべてのメンバーに分散されます。sticky 。 ハッシュ関数が計算され、特定のハンドラーに割り当てられます。 このシグネチャを持つ後続のリクエストは、同じハンドラーに送られます。sticky-fun 。 交換ポイントが初期化されると、 stickyバランシング用のハッシュ計算機能が追加で転送されます。fun 。 sticky-funに似ていますが、さらにリダイレクト、拒否、または前処理を行うことができます。
交換戦略は、交換ポイントが初期化されるときに設定されます。
メッセージングのバランスをとることに加えて、エンティティにタグを付けることができます。 システム内のタグのタイプを考慮してください。
- 接続タグ。 どの接続を介してイベントが発生したかを理解できます。 コントローラプロセスが同じ交換ポイントに接続するが、異なるルーティングキーを使用する場合に使用されます。
- サービスタグ。 単一のサービスでプロセッサをグループ化し、ルーティングおよびバランシング機能を拡張できます。 req-respパターンの場合、ルーティングは線形です。 交換ポイントにリクエストを送信し、それをサービスに渡します。 ただし、ハンドラーを論理グループに分割する必要がある場合は、タグを使用して分割が実行されます。 タグを指定すると、リクエストはコントローラの特定のグループに送信されます。
- リクエストタグ。 回答を区別できます。 システムは非同期であるため、サービスの応答を処理するには、リクエストを送信するときにRequestTagを指定できる必要があります。 それから、リクエストが私たちに届いた答えを理解できます。
パブサブ
pub-subの場合、すべてが少し簡単です。 メッセージが公開される交換ポイントがあります。 交換ポイントは、必要なルーティングキーをサブスクライブするサブスクライバー間でメッセージを配信します(これはそれらに類似していると言えます)。
スケーラビリティと復元力
システム全体のスケーラビリティは、システムのレイヤーとコンポーネントのスケーラビリティの程度に依存します。
- サービスは、このサービスのハンドラーを使用してクラスターにノードを追加することによりスケーリングされます。 試運転中に、最適なバランシングポリシーを選択できます。
- 個別のクラスターのフレームワーク内のメッセージングサービス自体は、通常、特にロードされた交換ポイントを個々のクラスターノードに転送するか、クラスターの特別にロードされたゾーンにプロキシプロセスを追加することによってスケールアップされます。
- 特性としてのシステム全体のスケーラビリティは、アーキテクチャの柔軟性と、個々のクラスターを共通の論理エンティティに結合する可能性に依存します。
多くの場合、スケーリングの単純さと速度がプロジェクトの成功を決定します。 現在のパフォーマンスにおけるメッセージングは、アプリケーションとともに成長します。 50〜60台の車のクラスターがなくても、連邦に頼ることができます。 残念ながら、連合のトピックはこの記事の範囲外です。
ご予約
負荷分散の分析では、サービスコントローラーの予約について既に説明しました。 ただし、メッセージングも予約する必要があります。 ノードまたはマシンがクラッシュした場合、メッセージングはできるだけ早く自動的に回復します。
私のプロジェクトでは、転倒した場合に負荷を拾う追加のノードを使用しています。 Erlangには、OTPアプリケーション用の標準の分散モード実装があります。 実際、分散モードは、以前に起動した別のノードでクラッシュしたアプリケーションを実行することにより、障害発生時にリカバリを実行します。 プロセスは透過的であり、障害が発生すると、アプリケーションは自動的にフェールオーバーノードに移動します。 この機能の詳細については、 こちらをご覧ください 。
性能
rabbitmqとカスタムメッセージングのパフォーマンスを少なくともおおよそ比較してみましょう。
openstackチームからのrabbitmqの公式テスト結果が見つかりました。
6.14.1.2.1.2.2節。 元のドキュメントは、RPC CASTの結果を示しています。
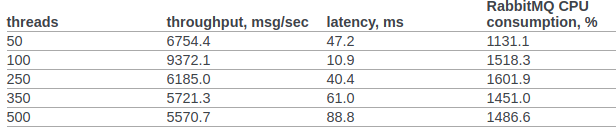
以前は、OSカーネルまたはerlang VMに追加の設定は行いません。 試験条件:
- erl opts:+ A1 + sbtu。
- 単一のアーランノード内のテストは、モバイルパフォーマンスの古いi7を搭載したラップトップで実行されます。
- クラスタテストは、10Gネットワークを備えたサーバーで実行されます。
- このコードは、Dockerコンテナーで機能します。 NATモードのネットワーク。
テストコード:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
シナリオ1:テストは、古いi7モバイル実行のラップトップで実行されます。 テスト、メッセージング、およびサービスは、1つのドッカーコンテナー内の1つのノードで実行されます。
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
シナリオ2 :Docker(NAT)の下の異なるマシンで実行されている3つのノード。
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
すべての場合において、CPU使用率は250%を超えませんでした
まとめ
このサイクルが意識のダンプのように見えず、私の経験が分散システムの研究者と、ビジネスシステム用の分散アーキテクチャの構築の最初の段階にあり、Erlang / Elixirを興味を持って見ている実践者の両方に真の利益をもたらすことを願っていますそれは価値がある...
@chuttersnapによる写真