自然言語処理は現在、非常に保守的なセクターを除いて使用されていません。 ほとんどの技術的ソリューションでは、「人間の」言語の認識と処理が長い間導入されています。そのため、ハードコードされた応答オプションを備えた通常のIVRは徐々に過去のものになり、チャットボットはライブオペレーターの参加なしでより適切に通信し始めています、メールフィルターは強打で動作します 録音された音声、つまりテキストの認識はどうですか? むしろ、現代の認識および処理技術の基礎は何でしょうか? 私たちの今日の適応翻訳はこれによく反応します-カットの下で、NLPの基本のギャップを埋める長い道のりを見つけるでしょう。 素敵な読書を!
自然言語処理とは何ですか?
自然言語処理(以下NLPと呼びます)-自然言語処理は、コンピューターが自然(人間)言語を分析する方法に専念するコンピューターサイエンスとAIのサブセクションです。 NLPでは、テキストと音声に機械学習アルゴリズムを使用できます。
たとえば、NLPを使用して、音声認識、ドキュメントの一般化、機械翻訳、スパム検出、名前付きエンティティの認識、質問への回答、オートコンプリート、予測テキスト入力などのシステムを作成できます。
今日、私たちの多くは音声認識スマートフォンを持っています-彼らは私たちの音声を理解するためにNLPを使用しています。 また、多くの人々はOSに組み込まれた音声認識を備えたラップトップを使用しています。
例
コルタナ
Windowsには、音声を認識するCortana仮想アシスタントがあります。 Cortanaを使用すると、リマインダーを作成したり、アプリケーションを開いたり、手紙を送ったり、ゲームをしたり、天気を調べたりすることができます。
シリ
SiriはAppleのOS(iOS、watchOS、macOS、HomePod、tvOS)のアシスタントです。 多くの機能は音声制御でも機能します:誰かに電話をかけたり、書いたり、メールを送信したり、タイマーを設定したり、写真を撮ったりなど。
Gmail
よく知られている電子メールサービスは、スパムを検出して受信トレイの受信トレイに届かないようにする方法を知っています。
Dialogflow
NLPボットを作成できるGoogleのプラットフォーム。 たとえば、注文
を受け入れるために昔ながらのIVRを必要としないピザ注文ボット
を作成でき
ます 。
NLTK Pythonライブラリ
NLTK(Natural Language Toolkit)は、PythonでNLPプログラムを作成するための主要なプラットフォームです。 多くの
言語コーパスの使いやすいインターフェイスと、分類、トークン化、
ステミング 、
マークアップ 、フィルタリング、
セマンティック推論のためのワードプロセッシング用のライブラリがあります。 まあ、これもコミュニティの助けを借りて開発されている無料のオープンソースプロジェクトです。
このツールを使用して、NLPの基本を示します。 以降のすべての例では、NLTKが既にインポートされていると想定しています。 これは
import nltk実行できます
テキストのNLPの基本
この記事では、次のトピックについて説明します。
- オファーによるトークン化。
- 単語によるトークン化。
- テキストの補題とスタンプ 。
- ストップワード。
- 正規表現。
- 言葉の袋 。
- TF-IDF
1.オファーによるトークン化
文のトークン化(場合によってはセグメンテーション)は、記述言語をコンポーネント文に分割するプロセスです。 アイデアは非常にシンプルに見えます。 英語や他のいくつかの言語では、特定の句読点、つまりピリオドを見つけるたびに文を分離できます。
しかし、英語でも、このタスクは略語でも使用されるため、このタスクは簡単ではありません。 略語表は、ワードプロセッシング中に文の境界を誤って配置しないようにするのに非常に役立ちます。 ほとんどの場合、これにはライブラリが使用されるため、実装の詳細を心配する必要はありません。
例:バックギャモンボードゲームについての短いテキストを受け取ります。
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
NLTKを使用してトークン化を提供するには、
nltk.sent_tokenizeメソッドを使用できます
| text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
出口で、3つの個別の文を取得します。
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2.言葉によるトークン化
単語によるトークン化(場合によってはセグメンテーション)は、文を構成要素の単語に分割するプロセスです。 特定のバージョンのラテンアルファベットを使用する英語および他の多くの言語では、スペースが適切な単語区切り文字です。
ただし、スペースのみを使用すると問題が発生する可能性があります。英語では、複合名詞は異なる方法で記述され、場合によってはスペースで区切られます。 ここでも、ライブラリが役立ちます。
例:前の例の文を取り、
nltk.word_tokenizeメソッドをそれらに適用してみましょう
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
結論:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3.テキストの補題とスタンプ
通常、テキストには同じ単語の異なる文法形式が含まれており、ルート語が1つある場合もあります。 語彙化とステミングは、出会うすべての単語形式を単一の通常の語彙形式にすることを目的としています。
例:さまざまな単語形式を1つにまとめる:
dog, dogs, dog's, dogs' => dog
同じですが、文全体を参照します:
the boy's dogs are different sizes => the boy dog be differ size
補題とステミングは、正規化の特殊なケースであり、異なります。
ステミングは、単語の語根から「過剰」をカットする粗いヒューリスティックなプロセスであり、多くの場合、これは単語構築接尾辞の損失につながります。
語彙化は、語彙と形態素解析を使用して、最終的に単語をその標準的な形式、つまり補題に導く、より微妙なプロセスです。
違いは、ステマー(ステミングアルゴリズムの特定の実装-翻訳者コメント)がコンテキストを知らなくても動作するため、品詞によって意味が異なる単語の違いを理解しないことです。 ただし、ステマーには独自の利点があります。実装が簡単で、動作が高速です。 さらに、「精度」の低下は場合によっては問題になりません。
例:- goodという言葉は、betterという言葉の補題です。 ここでは辞書を調べる必要があるため、Stemmerはこの接続を認識しません。
- 言葉遊びは言葉遊びの基本的な形です。 ここでは、ステミングと補題の両方が対処します。
- 会合という言葉は、文脈に応じて、名詞の通常の形または会う動詞の形のいずれかです。 ステミングとは異なり、補題化はコンテキストに基づいて正しい補題を選択しようとします。
違いがわかったので、例を見てみましょう。
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
結論:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4.ストップワード
ストップワードは、テキスト処理の前後にテキストからスローされるワードです。 機械学習をテキストに適用すると、そのような単語は多くのノイズを追加する可能性があるため、無関係な単語を取り除く必要があります。
ストップワードは通常、セマンティックロードを持たない記事、間投詞、共用体などによって理解されます。 ストップワードの一般的なリストはなく、すべて特定のケースに依存することを理解してください。
NLTKには、ストップワードの定義済みリストがあります。 初めて使用する前に、
nltk.download(“stopwords”)をダウンロードする必要があります。 ダウンロード後、
stopwordsパッケージをインポートして、単語自体を確認できます。
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
結論:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
文からストップワードを削除する方法を検討してください。
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
結論:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
リストの理解に慣れていない場合は、
こちらをご覧
ください 。 同じ結果を得る別の方法を次に示します。
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
ただし、リストの内包表記は最適化されているため高速です。インタープリターはループ中に予測パターンを明らかにします。
リストを
多数に変換した理由を尋ねるかもしれません。 セットは、一意の値を未定義の順序で格納できる抽象データ型です。 複数の検索は、リスト検索よりもはるかに高速です。 少数の単語の場合、これは重要ではありませんが、多数の単語について話している場合は、セットを使用することを強くお勧めします。 さまざまな操作を実行するのにかかる時間についてもう少し知りたい場合は、
この素晴らしいチートシートをご覧ください。
5.正規表現。
正規表現(regular、regexp、regex)は、検索パターンを定義する一連の文字です。 例:
- 。 -改行以外の任意の文字。
- \ wは1ワードです。
- \ d-1桁。
- \ sは1つのスペースです。
- \ Wは1つの非単語です。
- \ D-1桁の非数字;
- \ S-1つの非スペース。
- [abc]-a、b、またはcのいずれかに一致する指定された文字を検索します。
- [^ abc]-指定された文字以外の文字を検索します。
- [ag]-a〜gの範囲の文字を検索します。
Pythonドキュメントからの抜粋:
正規表現では、バックスラッシュ(\)を使用して、特殊な形式を示したり、特殊文字の使用を許可したりします。 これは、Pythonでバックスラッシュを使用することに反します。たとえば、文字通りバックスラッシュを示すには、検索パターンとして'\\\\'を記述する必要があり'\\\\' 。
解決策は、検索パターンに生の文字列表記を使用することです。 プレフィックス'r'使用した場合、バックスラッシュは特別に処理されません。 したがって、 r”\n”は2文字('\' 'n')の文字列であり、 “\n”は1文字(改行)の文字列です。
正規表現を使用して、テキストをさらにフィルタリングできます。 たとえば、単語以外のすべての文字を削除できます。 多くの場合、句読点は不要であり、常連の助けを借りて簡単に削除できます。
Pythonの
reモジュールは、正規表現操作を表します。
re.sub関数を使用して、検索パターンに適合するすべてのものを指定された文字列に置き換えることができます。 したがって、すべての非単語をスペースに置き換えることができます。
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
結論:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
レギュラーは、はるかに複雑なパターンを作成するために使用できる強力なツールです。 正規表現について詳しく知りたい場合は、これら2つのWebアプリケーション、
regex 、
regex101をお勧めします。
6.言葉の袋
機械学習アルゴリズムは生のテキストを直接処理できないため、テキストを一連の数値(ベクトル)に変換する必要があります。 これは
特徴抽出と呼ばれ
ます 。
ワードバッグは、テキストを操作するときに使用される一般的なシンプルな特徴抽出手法です。 テキスト内の各単語の出現を説明します。
モデルを使用するには、次のものが必要です。
- 既知の単語(トークン)の辞書を定義します。
- 有名な単語の存在度を選択します。
単語の順序または構造に関する情報は無視されます。 それが言葉のバッグと呼ばれる理由です。 このモデルは、おなじみの単語がドキュメントに現れるかどうかを理解しようとしますが、正確にどこで発生するかを知りません。
直感は、
同様のドキュメントが
同様の内容を持って
いることを示唆し
ます 。 また、コンテンツのおかげで、ドキュメントの意味について何かを学ぶことができます。
例:このモデルを作成する手順を検討してください。 モデルがどのように機能するかを理解するために、4つの文のみを使用します。 実際には、より多くのデータに遭遇します。
1.データをダウンロードする
これがデータであり、配列としてロードすることを想像してください。
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
これを行うには、ファイルを読み取り、行で分割します。
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
結論:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2.辞書を定義する
大文字と小文字、句読点、1文字のトークンを無視して、読み込まれた4つの文からすべての一意の単語を収集します。 これが私たちの辞書(有名な言葉)になります。
辞書を作成するには、sklearnライブラリーの
CountVectorizerクラスを使用できます。 次のステップに進みます。
3.ドキュメントベクトルを作成する
次に、ドキュメント内の単語を評価する必要があります。 このステップでの目標は、生のテキストを一連の数字に変えることです。 その後、これらのセットを機械学習モデルへの入力として使用します。 最も単純なスコアリング方法は、単語の存在に注意することです。つまり、単語がある場合は1を、存在しない場合は0を入力します。
これで、前述のCountVectorizerクラスを使用して単語の袋を作成できます。
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
結論:
これらは私たちの提案です。 「単語の袋」モデルがどのように機能するかがわかります。
言葉の袋についてのいくつかの言葉
このモデルの複雑さは、辞書の決定方法と単語の出現回数のカウント方法です。
辞書のサイズが大きくなると、文書ベクトルも大きくなります。 上記の例では、ベクトルの長さは既知の単語の数に等しくなります。
場合によっては、信じられないほど大量のデータを持つことができ、ベクトルは数千または数百万の要素で構成されます。 さらに、各ドキュメントには、辞書の単語のごく一部しか含めることができません。
結果として、ベクトル表現には多くのゼロがあります。 多くのゼロを持つベクトルはスパースベクトルと呼ばれ、より多くのメモリと計算リソースが必要です。
ただし、このモデルを使用してコンピューティングリソースの要件を減らすと、既知の単語の数を減らすことができます。 これを行うには、一連の単語を作成する前に既に検討したものと同じ手法を使用できます。
- 単語の大文字小文字を無視します。
- 句読点を無視します。
- ストップワードの排出。
- 単語を基本的な形(語彙化とステミング)に還元。
- スペルミスの単語の修正。
辞書を作成する別のより複雑な方法は、グループ化された単語を使用することです。 これにより、辞書のサイズが変更され、単語の袋にドキュメントに関する詳細が追加されます。 このアプローチは「
N-gram 」と呼ばれます。
N-gramは、エンティティ(単語、文字、数字、数字など)のシーケンスです。 言語本体のコンテキストでは、N-gramは通常、一連の単語として理解されます。 ユニグラムは1ワード、バイグラムは2ワードのシーケンス、トライグラムは3ワードなどです。 数値Nは、N-gramに含まれるグループ化された単語の数を示します。 考えられるすべてのN-gramがモデルに該当するわけではなく、ケースに表示されるN-gramのみが該当します。
例:次の文を考慮してください。
The office building is open today
彼のバイグラムは次のとおりです。
ご覧のとおり、バイグラムのバッグは言葉のバッグよりも効果的なアプローチです。
単語の評価(スコアリング)辞書を作成するとき、単語の存在を評価する必要があります。 単純なバイナリアプローチを既に検討しています(1-単語があり、0-単語がありません)。
他の方法があります:
- 数量。 文書に各単語が出現する回数が計算されます。
- 頻度 テキスト内の各単語の出現頻度(単語の合計数に対して)が計算されます。
7. TF-IDF
頻度スコアリングには問題があります。頻度が最も高い単語には、それぞれ最高の評価があります。 これらの言葉では、頻度の低い言葉ほど、モデルの
情報ゲインが少ない場合があります。 状況を修正する1つの方法は、単語スコアを下げることです。これは
、すべての同様のドキュメントでよく見
られます 。 これは
TF-IDFと呼ばれます。
TF-IDF(用語頻度の略-逆文書頻度)は、コレクションまたはコーパスの一部である文書内の単語の重要性を評価するための統計的尺度です。
TF-IDFによるスコアリングは、ドキュメント内の単語の出現頻度に比例して増加しますが、この単語を含むドキュメントの数によって相殺されます。
ドキュメントYの単語Xのスコアリング式:
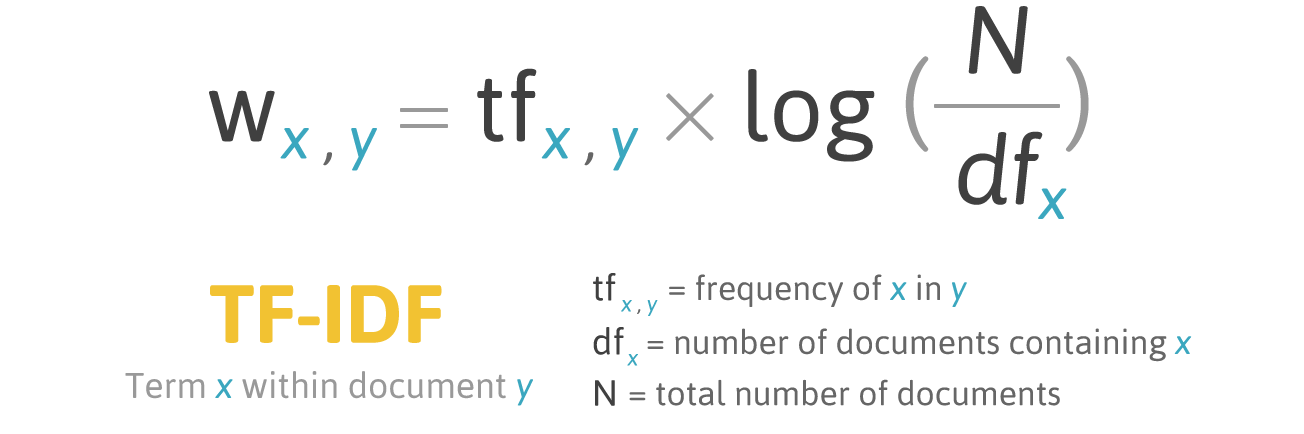 フォーミュラTF-IDF。 ソース: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
フォーミュラTF-IDF。 ソース: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF(用語頻度)は、ドキュメント内の単語の総数に対する単語の出現回数の比率です。
IDF(逆文書頻度)は、コレクション文書で特定の単語が出現する頻度の逆です。
その結果、
次のように単語
termの TF-IDFを計算できます。
例:sklearnライブラリーの
TfidfVectorizerクラスを使用して、TF-IDFを計算できます。 バッグオブワードの例で使用したのと同じメッセージを使用して、これを実行してみましょう。
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
コード:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
結論:
おわりに
この記事では、テキストのNLPの基本について説明しました。
- NLPでは、テキストと音声に機械学習アルゴリズムを使用できます。
- NLTK(Natural Language Toolkit)-PythonでNLPプログラムを作成するための主要なプラットフォーム。
- 提案トークン化は、記述言語をコンポーネント文に分割するプロセスです。
- 単語のトークン化は、文を構成要素の単語に分割するプロセスです。
- 語彙化とステミングは、出会うすべての単語形式を単一の通常の語彙形式にすることを目的としています。
- ストップワードは、テキスト処理の前後にテキストからスローされるワードです。
- regex(regex、regexp、regex)は、検索パターンを定義する一連の文字です。
- 単語の袋は、テキストを操作するときに使用される一般的でシンプルな特徴抽出手法です。 テキスト内の各単語の出現を説明します。
いいね! 特徴抽出の基本がわかったので、機械学習アルゴリズムへの入力として特徴を使用できます。
説明されているすべての概念を1つの大きな例で見たい場合は、
ここにいます 。