2019年2月から3月にかけて、 SNA Hackathon 2019ソーシャルネットワークフィードをランク付けするコンテストが開催され、そこで私たちのチームが1位になりました。 この記事では、コンテストの組織、私たちが試みた方法、ビッグデータのトレーニングのためのcatboost設定についてお話します。

SNAハッカソン
この名前のハッカソンは3回開催されます。 ok.ruソーシャルネットワークによってそれぞれ編成され、タスクとデータはこのソーシャルネットワークに直接関連しています。
この場合のSNA(ソーシャルネットワーク分析)は、ソーシャルグラフの分析としてではなく、ソーシャルネットワークの分析としてより正確に理解されます。
- 2014年の目標は、投稿が獲得するいいねの数を予測することでした。
- 2016年、ソーシャルグラフの分析により近い、VVZの目標(おそらくおなじみです)。
- 2019年-ユーザーが投稿を好きになる可能性におけるユーザーのフィードのランキング。
2014年については言えませんが、2016年と2019年には、データを分析する機能に加えて、ビッグデータを扱うスキルも必要でした。 これらのコンテストに私を惹きつけたのは、機械学習とビッグデータ処理タスクの組み合わせであり、これらの分野での経験が勝つ助けになったと思います。
mlbootcamp
2019年、コンテストはプラットフォームhttps://mlbootcamp.ruで開催されました。
コンテストは2月7日にオンラインで始まり、3つのタスクで構成されました。 誰もがサイトに登録し、 ベースラインをダウンロードして、数時間車をアップロードできました。 3月15日のオンラインステージの終わりに、各ショーのトップ15が、3月30日から4月1日に行われたオフラインステージのMail.ruオフィスに招待されました。
挑戦する
ソースデータは、ユーザー識別子(userId)と投稿識別子(objectId)を提供します。 ユーザーに投稿が表示された場合、データには、userId、objectId、この投稿に対するユーザーの反応(フィードバック)、さまざまな標識のセット、または写真やテキストへのリンクを含む行が含まれます。
| userId | objectId | ownerId | フィードバック | 画像 |
|---|
| 3555 | 22 | 5677 | [いいね、クリック] | [hash1] |
| 12842 | 55 | 32144 | [嫌い] | [hash2、hash3] |
| 13145 | 35 | 5677 | [クリック、再共有] | [hash2] |
テストデータセットには同様の構造が含まれていますが、フィードバックフィールドがありません。 目的は、フィードバック分野での「いいね」反応の存在を予測することです。
送信ファイルの構造は次のとおりです。
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35.61.55 |
| 131 | 35,68,129,11 |
メトリック-ユーザーによる平均ROC AUC。
データのより詳細な説明は完全なサイトで見つけることができます。 テストや写真などのデータをダウンロードすることもできます。
オンラインステージ
オンライン段階では、タスクは3つの部分に分割されました
- 共同システム -画像とテキストを除くすべての標識が含まれます。
- 画像 -画像に関する情報のみが含まれます。
- テキスト -テキストに関する情報のみが含まれます。
オフラインステージ
オフライン段階では、データにはすべての属性が含まれていましたが、テキストと画像はまばらでした。 データセット内の行は、すでに多くありましたが、1.5倍になりました。
問題解決
仕事でcvをやっているので、このコンテストの旅は「画像」タスクから始めました。 提供されたデータは、userId、objectId、ownerId(投稿が公開されているグループ)、投稿の作成および表示のタイムスタンプ、そしてもちろんこの投稿の画像です。
タイムスタンプに基づいていくつかの機能を生成した後、次のアイデアは、imagenetで事前にトレーニングされたニューロンの最後から2番目のレイヤーを取得し、これらの埋め込みを後押しすることでした。
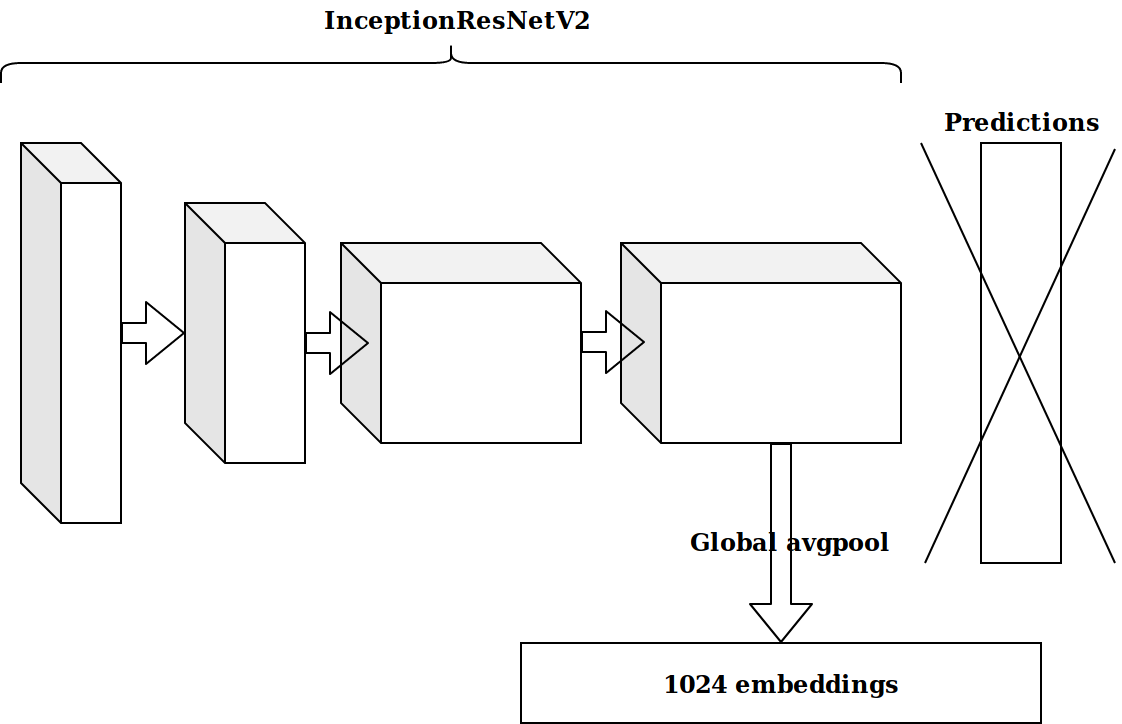
結果は印象的ではありませんでした。 imagenetニューロンからの埋め込みは無関係です。自動エンコーダーをファイルする必要があると思いました。
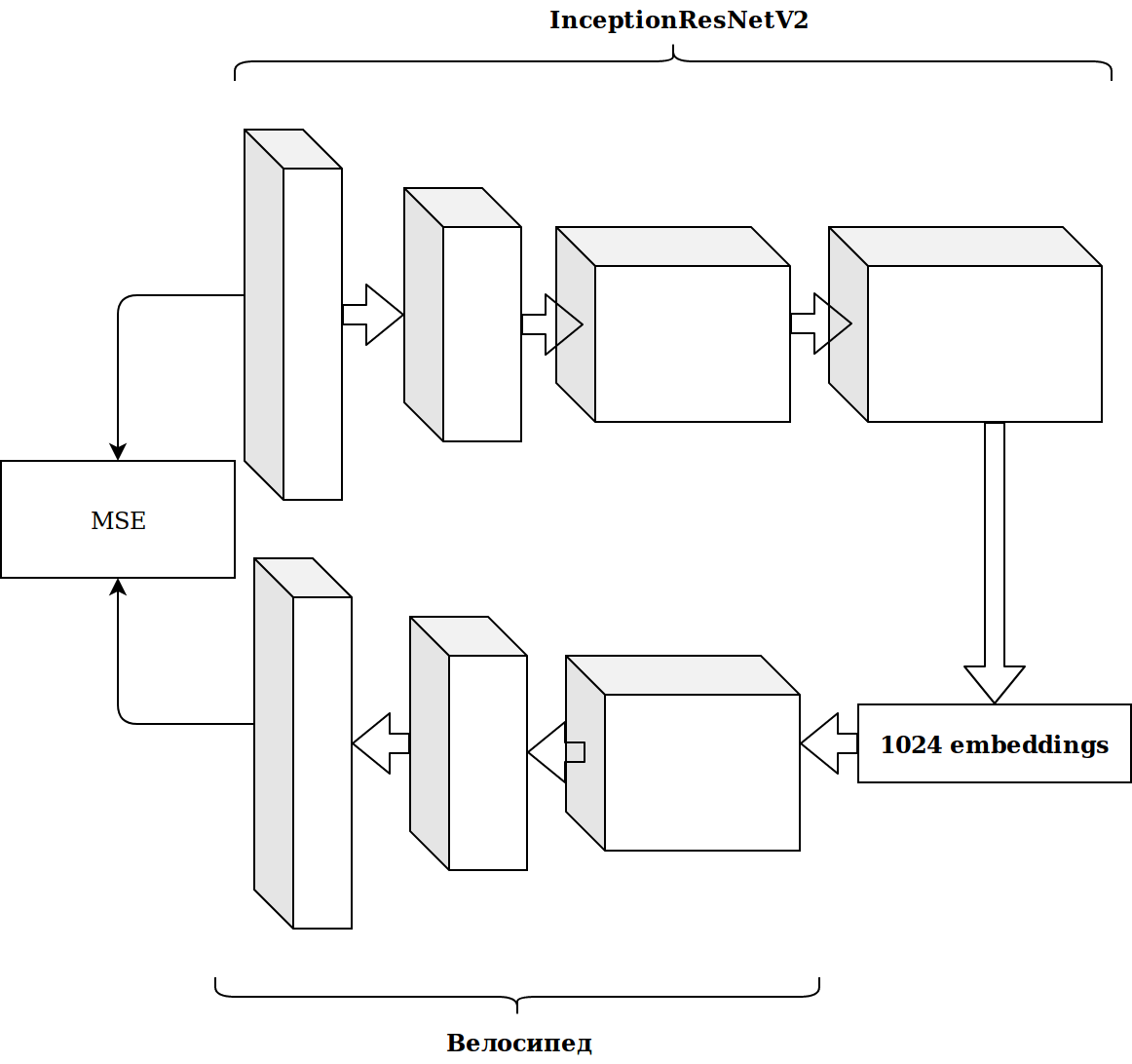
時間がかかり、結果は改善しませんでした。
機能の生成
画像の操作には多くの時間がかかり、私はもっと簡単なことをすることにしました。
すぐにわかるように、データセットにはいくつかのカテゴリカルサインがあります。あまり気にしないように、私はcatboostを使用しました。 解決策は素晴らしく、設定なしで、すぐにリーダーボードの最初の行に到達しました。
たくさんのデータがあり、それらは寄木細工のフォーマットでレイアウトされているので、二度考えることなく、私はscalaを取り、すべてをスパークで書き始めました。
画像の埋め込みよりも多くの成長をもたらした最も単純な機能:
- データ内でobjectId、userId、ownerIdが出会った回数(人気と相関するはずです)。
- ownerIdが見たuserIdの投稿数(グループに対するユーザーの関心と相関するはずです);
- ownerIdによって投稿を視聴したユニークユーザーIDの数(グループのオーディエンスのサイズを反映)。
タイムスタンプから、ユーザーがテープを視聴した時刻(朝/日/夜/夜)を取得できました。 これらのカテゴリを組み合わせることにより、引き続き機能を生成できます。
- 夕方にuserIdがログインした回数。
- この投稿が頻繁に表示される時間(objectId)など。
これにより、メトリックが徐々に改善されました。 ただし、トレーニングデータセットのサイズは約2,000万レコードであるため、機能を追加すると学習が大幅に遅くなります。
データ使用方法を再定義しました。 データは時間に依存しますが、将来的には明示的な情報漏洩は見られませんでしたが、万が一に備えて、次のように破りました。
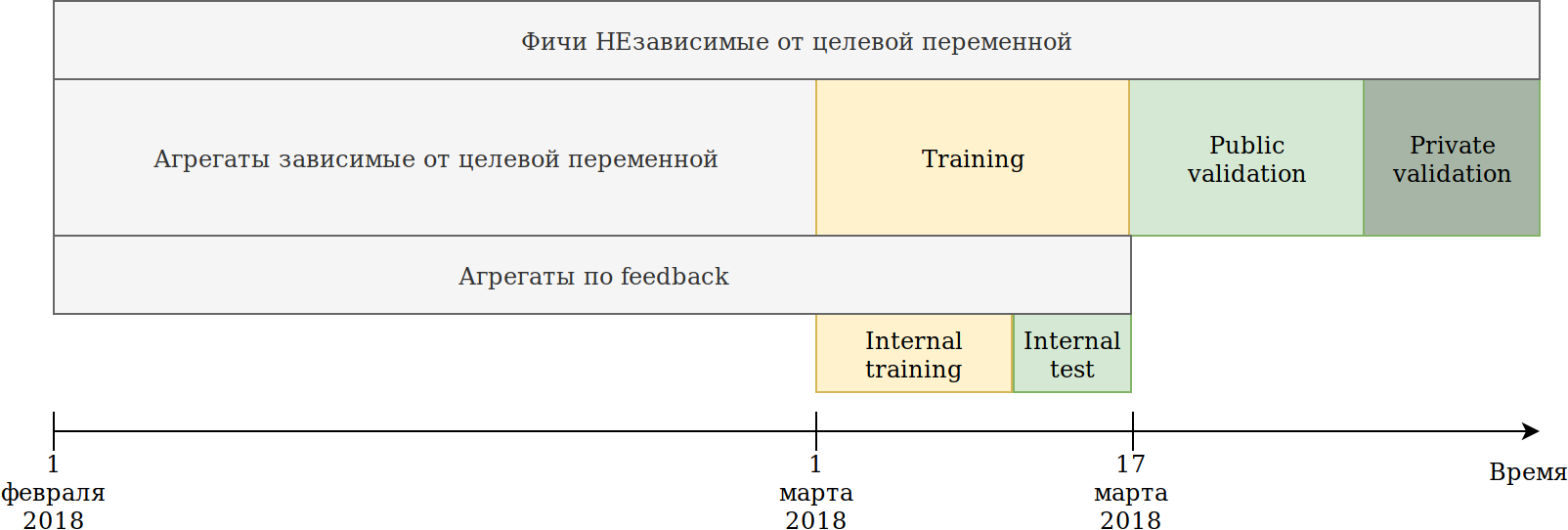
提供されたトレーニングセット(2月と3月の2週間)は2つのパートに分かれていました。
過去N日間のデータについて、彼はモデルをトレーニングしました。 上記の集計は、テストを含むすべてのデータに基づいて構築されました。 同時に、ターゲット変数のさまざまなエンコーダを構築できるデータが登場しました。 最も簡単なアプローチは、すでに新しい機能を作成しているコードを再利用し、トレーニングされておらずターゲット= 1のデータを送信することです。
したがって、同様の機能が得られました。
- userIdがownerIdグループの投稿を見た回数。
- userIdがownerIdへの投稿にいいねした回数。
- userIdがownerIdを気に入った投稿の割合。
つまり、カテゴリ機能のさまざまな組み合わせに応じて、データセットの一部でターゲットのエンコードを意味することが判明しました。 原則として、catboostはターゲットエンコーディングも構築します。この観点からは利点はありませんが、たとえば、このグループの投稿が好きなユニークユーザーの数をカウントすることが可能になりました。 同時に、主な目標が達成されました-私のデータセットは数回減少し、特徴の生成を続けることができました。
catboostは、好まれる反応に応じてのみエンコーダーを構築できますが、フィードバックには他の反応があります:再共有、嫌い、嫌い、クリック、無視、これは手動で行うことができます。 データセットを膨張させないように、あらゆる種類の集計を再集計し、重要度の低い機能をふるいにかけました。
その時までに私は大きな差で一位になりました。 唯一の恥ずかしさは、画像の埋め込みがほとんど利益をもたらさないことでした。 このアイデアは、catboostにすべてを与えるようになりました。 クラスタKは画像を意味し、新しいカテゴリフィーチャimageCatを取得します。
KMeansから取得したクラスターを手動でフィルタリングおよびマージした後のクラスを次に示します。

imageCatに基づいて、以下を生成します。
- 新しいカテゴリ機能:
- imageCatが最も頻繁に見たuserId;
- どのimageCatがownerIdで最も頻繁に表示されるか。
- 最も頻繁にuserIdを気に入ったimageCat。
- さまざまなカウンター:
- userIdを監視した一意のimageCatの数。
- 上記のターゲットエンコーディングに加えて、約15の同様の機能。
テキスト
画像コンテストの結果は私に合っていたので、テキストを試してみることにしました。 以前、私はテキストをあまり使いませんでした、そして愚かさで、私はtf-idfとsvdで1日を殺しました。 次に、doc2vecを使用したベースラインを確認しました。 doc2vecのパラメーターをわずかに調整して、テキストの埋め込みを取得しました。
そして、彼は単に画像のコードを再利用し、画像の埋め込みをテキストの埋め込みに置き換えました。 その結果、テキストコンテストで2位になりました。
共同システム
まだ「棒を突く」ことのない競技は1つしかありませんでしたが、リーダーボードのAUCから判断すると、この特定の競技の結果はオフラインステージに最も影響を与えそうでした。
ソースデータに含まれるすべての兆候を取り、カテゴリカルな兆候を選択し、画像自体の特徴を除き、画像と同じ集計を計算しました。 キャットブーストに入れるだけで2位になりました。
catboostを最適化する最初のステップ
最初の1位と2番目の2位は私を喜ばせましたが、特別なことは何もしなかったという理解がありました。
コンテストのタスクは、ユーザーのフレームワーク内で投稿をランク付けすることです。この間、分類問題を解決してきました。つまり、間違ったメトリックを最適化しました。
簡単な例を示します。
| userId | objectId | 予言 | グラウンドトゥルース |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
小さな置換を行います
| userId | objectId | 予言 | グラウンドトゥルース |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
次の結果が得られます。
| モデル | オーク | User1 AUC | User2 AUC | 平均AUC |
|---|
| オプション1 | 0.8 | 1,0 | 0,0 | 0.5 |
| オプション2 | 0.7 | 0.75 | 1,0 | 0.875 |
ご覧のとおり、AUCメトリック全体を改善しても、ユーザー内の平均AUCメトリックが改善されるわけではありません。
Catboostは、すぐにランキング指標を最適化できます。 ランキングメトリック、catboostを使用した場合の成功事例について読み、YetiRankPairwiseを設定して夜間学習を行います。 結果は印象的ではありませんでした。 私はよく勉強していないと判断したので、エラー関数をQueryRMSEに変更しました。これは、catboostのドキュメントから判断すると、より速く収束します。 その結果、分類のトレーニング中と同じ結果が得られましたが、これら2つのモデルのアンサンブルが大幅に増加し、3つすべての大会で1位になりました。
Collaborative Systemsコンペティションのオンラインステージが終了する5分前に、Sergey Shalnovは私を2位に移しました。 私たちが一緒に行ったさらなる方法。
オフライン段階の準備
オンラインステージでの勝利はRTX 2080 TIビデオカードで保証されていましたが、300,000ルーブルの主な賞であり、最終的には1位だったため、この2週間で仕事ができました。
結局のところ、セルゲイはキャットブーストも使用しました。 私たちはアイデアや機能を交換し、アンナベロニカドログシュのレポートについて学びました。そこでは、私の質問の多く、さらにはまだ出ていない質問に対しても答えがありました。
レポートを表示すると、すべてのパラメーターをデフォルト値に戻す必要があり、設定を非常に慎重に調整する必要があるという考えが、一連の標識を修正した後でのみ得られました。 現在、1つのトレーニングには約15時間かかりましたが、1つのモデルでは、ランキングのアンサンブルよりも速度が向上しました。
機能の生成
競争「コラボレーションシステム」では、多数の機能がモデルにとって重要であると評価されています。 たとえば、 auditweights_spark_svdは最も重要な属性であり、その意味についての情報はありません。 重要な兆候に基づいてさまざまなユニットを数える価値があると思いました。 たとえば、ユーザーごと、グループごと、オブジェクトごとの平均auditweights_spark_svd。 同じことは、トレーニングが実行されておらず、ターゲット= 1のデータ、つまりユーザーが気に入ったオブジェクトのユーザーごとの平均auditweights_spark_svdから計算できます。 auditweights_spark_svd以外にも、いくつかの重要な兆候がありました 。 それらのいくつかを次に示します。
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
たとえば、userIdによるauditweightsCtrGenderの平均値は、userId + ownerIdによるuserOwnerCounterCreateLikesの平均値と同様に重要な機能であることが判明しました。 これにより、フィールドの意味を理解する必要性について考える必要がありました。
他の重要な機能はauditweightsLikesCountとauditweightsShowsCountでした 。 一方を他方に分割すると、さらに重要な機能が得られました。
データ漏洩
競争モデルと生産モデルは非常に異なるタスクです。 データを準備する際、すべての詳細を考慮し、テストのターゲット変数に関する重要な情報を転送しないことは非常に困難です。 実稼働ソリューションを作成する場合、モデルのトレーニング時にデータリークの使用を回避しようとします。 しかし、コンテストに勝ちたい場合は、データリークが最良の機能です。
データを調べると、objectIdに従って、 auditweightsLikesCountとauditweightsShowsCountの値が変化していることがわかります。つまり、これらの記号の最大値の比率は、配信時の比率よりも変換後をはるかによく反映しています。
最初に見つかったリークはauditweightsLikesCountMax / auditweightsShowsCountMaxでした 。
しかし、データをより詳しく見るとどうなりますか? 配達日で並べ替えて取得:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | ターゲット(いいね!) |
|---|
| 1 | 1 | 12 | 3 | おそらくない |
| 1 | 2 | 15 | 3 | おそらくはい |
| 1 | 3 | 16 | 4 | |
最初のそのような例を見つけたのは驚くべきことであり、私の予測が実現しなかったことが判明しました。 しかし、オブジェクトのフレームワーク内のこれらの記号の最大値が増加するという事実を考えると、あまりにも怠notではなく、 auditweightsShowsCountNextとauditweightsLikesCountNext 、つまり次の瞬間の値を見つけることにしました。 機能を追加する
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) 24時間、急激にジャンプしました。
userId + ownerId内のuserOwnerCounterCreateLikes、たとえば、objectId + userGender内のauditweightsCtrGenderで次の値が見つかった場合、同様のリークが使用される可能性があります。 漏れのあるこのようなフィールドを6つ見つけ、可能な限り情報を引き出しました。
その時までに、私たちは共同の属性から最大限の情報を絞り込んでいたが、画像とテキストのコンテストには戻ってこなかった。 確認すべき素晴らしいアイデアがありました:対応する競技会で、画像やテキストに機能がどれだけ直接与えるか?
画像やテキストに関するコンテストでのリークはありませんでしたが、それまでにcatboostのデフォルトパラメータを返し、コードをコーミングし、いくつかの機能を追加しました。 合計結果:
| 解決策 | スピード |
|---|
| 画像で最大 | 0.6411 |
| 最大画像なし | 0.6297 |
| 2位結果 | 0.6295 |
| 解決策 | スピード |
|---|
| テキストで最大 | 0.666 |
| テキストなしの最大 | 0.660 |
| 2位結果 | 0.656 |
| 解決策 | スピード |
|---|
| コラボレーティブで最大 | 0.745 |
| 2位結果 | 0.723 |
多くのテキストや画像が絞り出される可能性は低いことが明らかになり、いくつかの最も興味深いアイデアを試した後、それらとの作業をやめました。
コラボレーションシステムでの機能のさらなる生成は成長をもたらさず、ランキングを開始しました。 オンラインの段階では、分類とランキングのアンサンブルはわずかに増加しましたが、それは分類の訓練が不十分だったためでした。 YetiRanlPairwiseを含むエラー関数はどれも、LogLossの結果に近づきませんでした(0.745対0.725)。 起動できなかったQueryCrossEntropyに希望がありました。
オフラインステージ
オフライン段階では、データ構造は同じままですが、小さな変更があります。
- 識別子userId、objectId、ownerIdが再ランダム化されました。
- いくつかの標識が削除され、いくつかの名前が変更されました。
- データは約1.5倍になりました。
リストされた困難に加えて、大きなプラスが1つありました。RTX2080TIを備えた大規模サーバーがチームに割り当てられました。 私は長い間htopを楽しんでいました。
アイデアは1つでした-すでにそこにあるものを再現するだけです。 サーバーに環境をセットアップするのに数時間を費やした後、結果が再現されていることを徐々に確認し始めました。 私たちが直面している主な問題は、データ量の増加です。 負荷をわずかに減らし、パラメータcatboost ctr_complexity = 1を設定することにしました。 これにより速度は少し低下しますが、私のモデルは動作し始め、結果は良好でした-0.733。 私とは異なり、セルゲイはデータを2つの部分に分割せず、すべてのデータをトレーニングしましたが、これはオンライン段階で最高の結果をもたらしましたが、オフライン段階では多くの困難がありました。 生成したすべての機能を使用して、「額に」キャットブーストを配置しようとすると、オンライン段階では何も起こりませんでした。 Sergeyは、たとえばfloat64型をfloat32に変換するなど、型の最適化を行いました。 この記事では、パンダのメモリの最適化に関する情報を見つけることができます。 その結果、SergeyはすべてのデータについてCPUのトレーニングを行い、約0.735になりました。
これらの結果は勝つには十分でしたが、実際のスピードを隠し、他のチームが同じことをしていないことを確信できませんでした。
最後までの戦い
catboostのチューニング
ソリューションは完全に再現され、テキストデータと画像の機能が追加されたため、残りはcatboostパラメーターを調整することだけでした。 Sergeyは少数の反復でCPUを研究し、ctr_complexity = 1で研究しました。 あと1日しかありませんでした。繰り返しを追加するか、ctr_complexityを増やすだけで、午前中はさらに高速になり、1日中歩くことができました。
オフラインの段階では、スコアは非表示にするのが非常に簡単で、サイトで最適なソリューションではないものを選択するだけです。 提出の締め切り前の最後の数分間にリーダーボードの急激な変化が予想され、停止しないことに決めました。
アンナのビデオから、モデルの品質を向上させるには、次のパラメーターを選択するのが最善であることを学びました。
- learning_rate-デフォルト値は、データセットのサイズに基づいて計算されます。 learning_rateの減少により、品質を維持するには、反復回数を増やす必要があります。
- l2_leaf_reg-正則化係数、デフォルト値は3、できれば2〜30 。値を小さくするとオーバーフィットが増加します。
- bagging_temperature-選択範囲内のオブジェクトの重みにランダム化を追加します。 デフォルト値は1で、指数分布から重みが選択されます。 値の減少は、過剰適合の増加につながります。
- random_strength-特定の反復の分割の選択に影響します。 random_strengthが高いほど、重要度の低いスプリットが選択される可能性が高くなります。 後続の各反復で、ランダム性が低下します。 値の減少は、過剰適合の増加につながります。
他のパラメーターは最終結果にあまり影響を与えないため、それらを選択しようとしませんでした。 ctr_complexity = 1のGPUデータセットでのトレーニングの1回の反復には20分かかり、縮小されたデータセットで選択されたパラメーターは、完全なデータセットでの最適なパラメーターとわずかに異なりました。 その結果、データの10%で約30回の反復を行い、すべてのデータでさらに約10回の反復を行いました。 およそ次のことが判明しました。
- learning_rateをデフォルトから40%増やしました。
- l2_leaf_regは同じままです。
- bagging_temperatureとrandom_strengthが0.8に減少しました。
デフォルトのパラメーターでは、モデルは十分にトレーニングされていないと結論付けることができます。
リーダーボードで結果を見たとき、私は非常に驚きました:
| モデル | モデル1 | モデル2 | モデル3 | アンサンブル |
|---|
| チューニングなし | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| チューニングあり | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
モデルをすばやく適用する必要がない場合は、パラメーターの選択を、最適化されていないパラメーターの複数のモデルのアンサンブルに置き換えることをお勧めします。
Sergeyは、データセットのサイズを最適化してGPUで実行することに従事していました。 最も簡単なオプションはデータの一部を切り捨てることですが、これを行う方法はいくつかあります。
- データセットがメモリに収まり始めるまで、最も古いデータ(2月初旬)を徐々に削除します。
- 重要度が最も低い機能を削除します。
- エントリが1つしかないuserIdを削除します。
- テスト中のuserIdのみを残します。
そして最後に-すべてのオプションのアンサンブルを作成します。
最後のアンサンブル
最終日の夜遅くまでに、モデルのアンサンブルを投稿し、0.742が得られました。 夜、ctr_complexity = 2でモデルを起動し、30分ではなく5時間トレーニングしました。 午前4時にのみ彼女はカウントし、私は最後のアンサンブルを行いました。
問題を解決するためのさまざまなアプローチにより、予測は強く相関せず、アンサンブルが大幅に増加しました。 適切なアンサンブルを取得するには、予測モデルの生の予測を使用して(prediction_type = 'RawFormulaVal')、scale_pos_weight = neg_count / pos_countを設定することをお勧めします。
このサイトでは、プライベートリーダーボードで最終結果を見ることができます。
その他の解決策
多くのチームがレコメンダーシステムアルゴリズムの規範に従いました。 私は、この分野の専門家ではないため、それらを評価することはできませんが、2つの興味深い決定が記憶されました。
- ニコライ・アノヒンの決定 。 Mail.ruの従業員であるNikolaiは賞金を請求しなかったため、彼の目標は最高速度を得るのではなく、簡単にスケーラブルなソリューションを得ることでした。
- facebookのこの記事に基づいた審査員チームの決定により、手作業なしで画像を非常にうまくクラスター化することができました。
おわりに
メモリに最も多く保管されるもの:
- データにカテゴリ機能があり、ターゲットエンコーディングを正しく行う方法を知っている場合は、とにかくcatboostを試してみることをお勧めします。
- コンテストに参加する場合、learning_rateとイテレーションを除き、パラメーターの選択に時間を無駄にしないでください。 より高速なソリューションは、複数のモデルのアンサンブルを作成することです。
- BoostingsはGPUで学習できます。 CatboostはGPUで非常にすばやく学習できますが、多くのメモリを消費します。
- アイデアの開発およびテスト中は、小さなrsm〜= 0.2(CPUのみ)およびctr_complexity = 1を設定することをお勧めします。
- 他のチームとは異なり、モデルのアンサンブルは大幅に増加しました。 アイデアを交換し、異なる言語で書いただけです。 データを分割するための別のアプローチがあり、誰もが独自のバグを抱えていたと思います。
- ランキングの最適化がランキングの最適化よりも悪い結果をもたらした理由は明らかではありません。
- 私はテキストについて少し経験し、推奨システムがどのように作られているかを理解しました。

受け取った感情、知識、賞品について主催者に感謝します。