オペレーティングシステムの概要
こんにちは、Habr! 私の考えでは、OSTEPという興味深い文献の一連の翻訳記事に注目したいと思います。 この記事では、unixに似たオペレーティングシステムの動作、つまり、プロセス、さまざまなスケジューラ、メモリ、および現代のOSを構成する他の同様のコンポーネントの動作について詳しく説明します。
ここで見ることができるすべての資料のオリジナル。 翻訳は専門的ではない(非常に自由に)行われましたが、一般的な意味を保持したいと思います。
このテーマの実験室の仕事はここで見つけることができます:
その他の部品:
そして、あなたは
電報で私のチャンネルを見ることができます=)
スケジューラーの紹介
問題の本質:プランナーポリシーの作成方法
基本的なスケジューラポリシーフレームワークはどのように開発する必要がありますか? 重要な前提は何ですか? 重要な指標は何ですか? 初期のコンピューティングで使用された基本的なテクニックは何ですか?ワークロードの仮定
考えられるポリシーについて説明する前に、最初に、システムで実行されているプロセスについて簡単に説明します。これをまとめて
ワークロードと呼びます。 ワークロードをポリシー構築の重要な部分として定義し、ワークロードについてより多くの知識があれば、より良いポリシーを作成できます。
システムで実行されているプロセス(
ジョブ (タスク)とも呼ばれる)について、次のことを想定しています。 これらの仮定のほとんどすべては現実的ではありませんが、思考の発展に必要です。
- 各タスクは同じ時間実行されますが、
- すべてのタスクが同時に設定され、
- 割り当てられたタスクは完了するまで機能し、
- すべてのタスクはCPUのみを使用し、
- 各タスクの実行時間は既知です。
スケジューラメトリック
負荷に関するいくつかの仮定に加えて、さまざまな計画ポリシーを比較するために、スケジューラメトリックというツールがさらに必要です。 メトリックは単に何かの尺度です。 プランナーを比較するために使用できる多くのメトリックがあります。
たとえば、ターンアラウンド時間と呼ばれるメトリックを使用します。 タスクの所要時間は、タスクを完了するのにかかる時間とタスクがシステムに入る時間の差として定義されます。
ターンアラウンド=完了-到着すべてのタスクが同時に到着すると仮定したため、Ta = 0、したがってTt = Tcになります。 上記の仮定を変更すると、この値は自然に変化します。
別の測定基準は
公平性です。 生産性と誠実さは、多くの場合、計画において対立する特性です。 たとえば、スケジューラはパフォーマンスを最適化できますが、他のタスクの実行を待機するコストがかかるため、整合性が低下します。
ファーストインファーストアウト(FIFO)
実装できる最も基本的なアルゴリズムは、FIFOまたは
先着(in)、先着(out)と呼ば
れます。 このアルゴリズムにはいくつかの利点があります。実装が非常に簡単であり、すべての前提に適合し、仕事を非常にうまく行います。
簡単な例を考えてみましょう。 3つのタスクが同時に設定されたとしましょう。 しかし、タスクAが他の誰よりも少し早く来たと仮定すると、Cに対してBのように、他のタスクよりも早く実行リストに載ることになります。各タスクが完了するまでに10秒かかるとします。 これらのタスクを完了する平均時間はどれくらいですか?
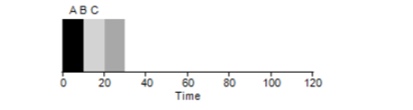
値-10 + 20 + 30をカウントし、3で割ると、プログラムの平均実行時間が20秒になります。
では、仮定を変えてみましょう。 特に、仮定1なので、各タスクに同じ時間がかかるとは仮定しません。 今回、FIFOはどのように表示されますか?
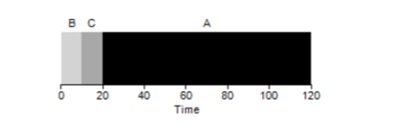
結局のところ、タスクの実行時間が異なると、FIFOアルゴリズムの生産性に非常に悪影響を及ぼします。 タスクAは100秒間実行され、BとCはそれぞれ10秒のままであると仮定します。

図からわかるように、システムの平均時間は(100 + 110 + 120)/ 3 = 110です。 この効果は
、コンボイ効果と呼ばれます。リソースの短期消費者が大量の消費者の後に並んでいる場合です。 満杯のトロリーを持った顧客がいるとき、食料品店の行列のように見えます。 この問題に対する最善の解決策は、現金を交換するか、リラックスして深く呼吸することです。
最短の仕事が最初
重いプロセスで同様の状況を何らかの形で解決することは可能ですか? もちろん。 別のタイプのスケジューリングは、
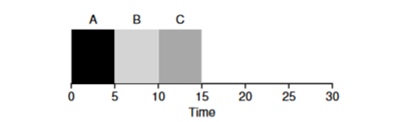
Shortest Job First (SJF)と呼ばれます。 そのアルゴリズムも非常に原始的です-名前が示すように、最短のタスクが次々に最初に起動されます。
この例では、同じプロセスを開始した結果、プログラムの平均所要時間が改善され、
110ではなく50になり、ほぼ2倍改善されます。
したがって、すべてのタスクが同時に到着するという所定の仮定では、SJFアルゴリズムが最も最適なアルゴリズムのようです。 ただし、私たちの仮定はまだ現実的ではないようです。 今回は、仮定2を変更し、今回は、タスクがすべて同時にではなく、いつでも残ることができると想像します。 これはどのような問題につながりますか?

タスクA(100秒)が最初に到着し、実行を開始すると想像してください。 時間t = 10で、タスクBとCが到着し、それぞれに10秒かかります。 したがって、平均実行時間は(100+(110-10)+(120-10))\ 3 = 103です。プランナーは状況を改善するために何ができますか?
完了までの最短時間(STCF)
状況を改善するために、プログラムが完了するまで稼働しているという前提3を省略します。 さらに、ハードウェアサポートが必要になります。ご
想像のとおり 、
タイマーを使用して作業中のタスクを中断し、
コンテキストを
切り替えます。 したがって、スケジューラーはタスクBとCが受信された瞬間に何かを行うことができます-タスクAの実行を停止し、タスクBとCを処理し、終了後にプロセスAを続行します。このスケジューラーは
STCFまたは
Preemptive Job Firstと呼ばれます。
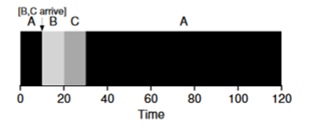
このスケジューラーの結果は次の結果になります:((120-0)+(20-10)+(30-10))/ 3 = 50 したがって、このようなスケジューラは、タスクに最適です。
メトリック応答時間
したがって、タスクの実行時間がわかっていて、これらのタスクがCPUのみを使用する場合、STCFが最適なソリューションになります。 そして、初期の頃に、これらのアルゴリズムはうまく機能し、かなりうまくいきました。 しかし、今ではユーザーはほとんどの時間をターミナルで過ごし、そこから生産的なインタラクティブな対話を期待しています。 そのため、新しいメトリックが作成されました-
応答時間 (応答)。
応答時間は次のように計算されます。
Tresponse = Tfirstrun-到着したがって、前の例では、応答時間は次のようになります。A= 0、B = 0、B = 10(abg = 3.33)。
また、3つのタスクが同時に到着する状況では、STCFアルゴリズムはあまり良くありません。小さなタスクが完全に完了するまで待つ必要があります。 したがって、このアルゴリズムは、所要時間メトリックには適していますが、対話性メトリックには適していません。 エディタで文字を入力しようとして端末に座っているとすると、プロセッサが他のタスクを占有しているため、10秒以上待つ必要があります。 これはあまり快適ではありません。
そこで、別の問題に直面しています-応答時間に敏感なスケジューラをどのように構築できますか?
ラウンドロビン
この問題を解決するために、
ラウンドロビン (RR)アルゴリズムが開発されました。 基本的な考え方は非常に単純です。タスクを開始して完了させるのではなく、一定時間(タイムクォンタムと呼ばれる)タスクを開始してから、キューから別のタスクに切り替えます。 アルゴリズムは、すべてのタスクが完了するまで作業を繰り返します。 この場合、プログラムの実行時間は、タイマーがプロセスを中断する時間の倍数でなければなりません。 たとえば、タイマーがx = 10msごとにプロセスを中断する場合、プロセス実行ウィンドウのサイズは10の倍数で、10.20またはx * 10である必要があります。
例を見てみましょう。ABVのタスクがシステムに同時に到着し、それぞれが5秒間動作したいとします。 SJFアルゴリズムは、各タスクを最後まで完了してから、別のタスクを開始します。 対照的に、起動ウィンドウ= 1sのRRアルゴリズムは、次のようにタスクを実行します(図4.3)。
(SJFアゲイン(応答時間が悪い)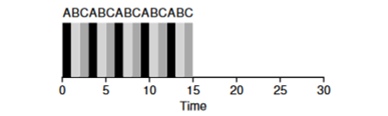 (ラウンドロビン(応答時間に適しています)
(ラウンドロビン(応答時間に適しています)アルゴリズムの平均応答時間はRR(0 + 1 + 2)/ 3 = 1ですが、SJF(0 + 5 + 10)/ 3 = 5です。
時間ウィンドウはRRにとって非常に重要なパラメーターであり、それが小さいほど応答時間が長くなると仮定するのは論理的です。 ただし、コンテキストを切り替える時間も全体的なパフォーマンスに影響するため、小さくしすぎることはできません。 したがって、実行ウィンドウのタイミングはOSアーキテクトによって設定され、その中で実行される予定のタスクに依存します。 コンテキストの切り替えは、時間を費やす唯一のサービス操作ではありません-実行中のプログラムは、他の多くのことで動作します。たとえば、さまざまなキャッシュであり、この環境を保存および復元する必要があるたびに、多くの時間がかかります。
RRは、応答時間のメトリックのみである場合、優れたプランナーです。 しかし、このアルゴリズムでは、タスクの所要時間のメトリックはどのように動作しますか? 動作時間A、B、C = 5秒で、同時に到着する上記の例を検討してください。 タスクAは13秒、Bは14秒、Cは15秒で終了し、平均所要時間は14秒になります。 したがって、RRは売上高メトリックの最悪のアルゴリズムです。
より一般的には、RRなどのアルゴリズムはすべて正直であり、すべてのプロセス間でCPUの動作時間を均等に分割します。 したがって、これらのメトリックは常に矛盾しています。
したがって、いくつかの対立するアルゴリズムがあり、同時にいくつかの仮定が残っています-タスク時間は既知であり、タスクはCPUのみを使用するということです。
I / Oとの混合
まず、プロセスがCPUのみを使用するという前提4を削除しますが、もちろんそうではないため、プロセスは他の機器を使用できます。
プロセスがI / O操作を要求すると、プロセスはブロック状態になり、I / Oが完了するのを待ちます。 I / Oがハードドライブに送信される場合、このような操作には数ミリ秒以上かかることがあり、プロセッサはその時点でアイドル状態になります。 このとき、スケジューラは他のプロセスによってプロセッサを引き継ぐことがあります。 スケジューラが行う必要がある次の決定は、プロセスがそのI / Oを完了したときです。 これが発生すると、割り込みが発生し、OSは呼び出されたI / Oプロセスを準備完了状態にします。
いくつかのタスクの例を考えてみましょう。 それぞれに50msのプロセッサ時間が必要です。 ただし、最初のものは10ミリ秒ごとにI / Oにアクセスします(これも10ミリ秒実行されます)。 また、プロセスBは、I / Oなしで50ミリ秒のプロセッサを使用するだけです。
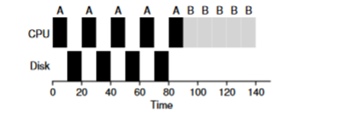
この例では、STCFスケジューラーを使用します。 Aのようなプロセスを実行すると、スケジューラはどのように動作しますか? 彼は次のことを行います-最初に完全にAを処理し、次にBを処理します。

この問題を解決するための従来のアプローチは、プロセスAの各10ミリ秒のサブタスクを個別のタスクとして解釈することです。 したがって、STJFアルゴリズムで開始する場合、50ミリ秒のタスクと10ミリ秒のタスクの選択は明らかです。 次に、サブタスクAが完了すると、プロセスBとI / Oが開始されます。 I / Oの完了後、プロセスBの代わりに10ミリ秒のプロセスAを再び開始することが決定されます。したがって、最初のプロセスがI / Oを待機している間にCPUが別のプロセスによって使用されると、オーバーラップを実現できます。 その結果、システムの利用効率が向上します。対話型プロセスがI / Oを待機しているときに、プロセッサで他のプロセスを実行できます。
Oracleはもうありません
ここで、タスクの時間がわかっているという仮定を取り除こうとします。 これは一般に、リスト全体から見て最悪で最も非現実的な仮定です。 実際、平均的な標準OSでは、OS自体は通常、タスクを完了するのにかかる時間についてほとんど知らないので、タスクにかかる時間を知らずにスケジューラを構築するにはどうすればよいでしょうか? おそらく、この問題を解決するためにRRのいくつかの原則を使用できますか?
まとめ
タスクプランニングの基本的なアイデアを検討し、プランナーの2つのファミリをレビューしました。 最初のタスクは開始時に最短のタスクを開始するため、所要時間が長くなり、2番目のタスクはすべてのタスク間で均等に引き裂かれ、応答時間が長くなります。 両方のアルゴリズムは、他のファミリーアルゴリズムが優れている場合は悪いです。 また、CPUとI / Oを並行して使用するとパフォーマンスがどのように改善されるかについても調べましたが、OSの透視に関する問題は解決しませんでした。 そして、次のレッスンでは、近い過去を調べて将来を予測しようとしているプランナーを検討します。 また、マルチレベルフィードバックキューと呼ばれます。