
RabbitMQは、Erlang言語で記述されたメッセージブローカーであり、各ノードが読み取りおよび書き込み要求を処理できる複数のノードへの完全なデータレプリケーションを備えたフェールオーバークラスターを編成できます。 多くのKubernetesクラスターの本番運用では、多数のRabbitMQインストールをサポートしており、ダウンタイムなしでクラスター間でデータを移行する必要に直面しています。
この操作は、少なくとも2つの場合に必要でした。
- KubernetesにないRabbitMQクラスターから、既に「バックアップ」されている(つまり、ポッドK8で機能している)新しいクラスターにデータを転送します。
- あるネームスペースから別のネームスペースへのKubernetes内のRabbitMQの移行(たとえば、パスがネームスペースで区切られている場合、インフラストラクチャをあるパスから別のパスに転送するため)。
この記事で提案するレシピは、K8または一部の古いサーバーのいずれかにある古いRabbitMQクラスター(たとえば3つのノード)が存在する状況に焦点を当てています(ただし、これらに限定されるわけではありません)。 Kubernetesでホストされるアプリケーションはそこで動作します(既に存在するか、将来的に):

...そして、それをKubernetesの新しいプロダクションに移行するという課題に直面しています。
まず、移行自体の一般的なアプローチについて説明し、その後、その実装に関する技術的な詳細を説明します。
移行アルゴリズム
アクションの前の最初の予備ステップは、古いRabbitMQインストールで高可用性(
HA )モードが有効になっていることを確認することです。 その理由は明らかです-データを失いたくありません。 このチェックを実行するには、RabbitMQ管理パネルに移動し、[管理]→[ポリシー]タブで、値が
ha-mode: allであることを確認し
ha-mode: all :

次のステップは、Kubernetesポッドで新しいRabbitMQクラスターを上げることです(この例では、たとえば3つのノードで構成されていますが、それらの数は異なる場合があります)。
その後、古いRabbitMQクラスターと新しいRabbitMQクラスターを組み合わせて、単一のクラスター(6ノード)を取得します。
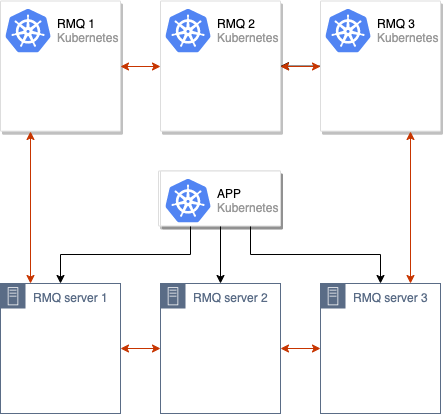
古いRabbitMQクラスターと新しいRabbitMQクラスターの間でデータを同期するプロセスが開始されます。 すべてのデータがクラスター内のすべてのノード間で同期された後、新しいクラスターを使用するようにアプリケーションを切り替えることができます。
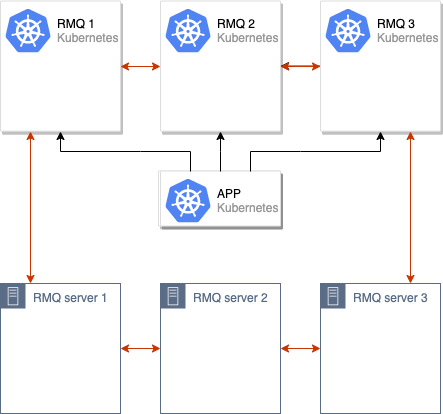
これらの操作の後、RabbitMQクラスターから古いノードを削除するだけで十分であり、移動は完了したと見なすことができます。

このスキームは、本番環境で繰り返し使用しています。 ただし、独自の利便性のために、Kubernetesクラスターのセットに典型的なRMQ構成を配布する特殊なシステムのフレームワーク内に実装しました
(好奇心がある人のために: 最近話した add-operator について話している ) 。 提案されたソリューションを実際に試すために、誰でもインストールに適用できる個別の指示を以下に示します。
実践してみます
必要条件
詳細は非常に簡単です。
- Kubernetesクラスター(minikubeも適しています);
- RabbitMQクラスター(ベアメタルに展開でき、公式のHelmチャートからKubernetesの通常のクラスターとして作成できます)。
以下に説明する例では、RMQをKubernetesにデプロイし、
rmq-oldという名前を付けました。
スタンド準備
1.ヘルムチャートをダウンロードして、少し編集します。
helm fetch --untar stable/rabbitmq-ha
便宜上、パスワード、
ErlangCookieを設定し、
ha-allポリシーを設定して、デフォルトでキューがRMQクラスターのすべてのノード間で同期されるようにします。
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2.チャートを設定します。
helm install . --name rmq-old --namespace rmq-old
3. RabbitMQ管理パネルに移動して、新しいキューを作成し、いくつかのメッセージを追加します。 これらは、移行後にすべてのデータが保存され、何も失われていないことを確認できるようにするために必要になります。

テストベンチの準備ができました。転送する必要のあるデータを含む「古い」RabbitMQがあります。
クラスター移行RabbitMQ
1.最初に、ユーザーの
同じ ErlangCookieとパスワードを使用して、新しいRabbitMQを
別のネームスペースにデプロイします。 これを行うには、上記の操作を実行し、最終的なRMQインストールコマンドを次のように変更します。
helm install . --name rmq-new --namespace rmq-new
2.ここで、新しいクラスターを古いクラスターとマージする必要があります。 これを行うには、
新しい RabbitMQの各ポッドに移動して、コマンドを実行します。
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
OLD_RMQ変数
OLD_RMQは、
古い RMQクラスターのノードのいずれかのアドレスが
OLD_RMQます。
これらのコマンドは、
新しい RMQクラスターの現在のノードを停止し、古いクラスターに接続して、再起動します。
3. 6ノードのRMQクラスターの準備ができました。

すべてのノード間でメッセージが同期されるまで待つ必要があります。 メッセージの同期時間は、クラスターがデプロイされているアイロンの容量とメッセージの数に依存することは容易に推測できます。 説明したシナリオでは、そのうちの10個しか存在しないため、データは即座に同期されましたが、十分な数のメッセージがある場合、同期には数時間かかることがあります。
したがって、同期ステータス:

ここで
+5は、メッセージが
すでに別の 5つのノードにあることを意味します([
Nodeフィールドで指定されているものを除く)。 したがって、同期は成功しました。
4.アプリケーションのRMQアドレスを新しいクラスターに切り替えるだけです(ここでの特定のアクションは、使用しているテクノロジースタックや他のアプリケーションの仕様によって異なります)。その後、古いクラスターに別れを告げることができます。
最後の操作(つまり、アプリケーションを新しいクラスター
に切り替えた
後 )では、
古いクラスターの各ノードに移動して、コマンドを実行します。
rabbitmqctl stop_app rabbitmqctl reset
クラスターは古いノードを「忘れました」。古いRMQを削除すると、移動が完了します。
注 :証明書でRMQを使用する場合、基本的に変更はありません-移動のプロセスはまったく同じ方法で実行されます。結論
説明したスキームは、RabbitMQを転送するか、新しいクラスターに移動する必要があるほとんどすべての場合に適しています。
私たちの場合、多くの場所からRMQにアクセスしたときに問題が発生したのは1回だけであり、どこでもRMQアドレスを新しいアドレスに変更する機会はありませんでした。 次に、同じネームスペースで同じRMQを同じラベルで起動し、既存のサービスとイングレスに該当するようにしました。ポッドを開始したときに、最初にラベルを削除して、リクエストが空のRMQに落ちないようにしました。メッセージの同期後にそれらを追加し直します。
RabbitMQを変更された構成の新しいバージョンに更新するときに同じ戦略を使用しました-すべてが時計のように機能しました。
PS
この資料の論理的な継続として、MongoDB(鉄サーバーからKubernetesへの移行)およびMySQL(Kubernetes内でこのDBMSを「準備する」オプションの1つ)に関する記事を準備しています。 これらは今後数か月で公開されます。
PPS
ブログもご覧ください。