私たちのチームは短期間で数十人の従業員から約200人のユニット全体に移動しました。このパスからのマイルストーンを共有したいと思います。 さらに、ビッグデータで今まさに必要なのは誰で、実際のエントリーのしきい値は何かを説明します。

新しい分野で成功するためのレシピ
ビッグデータの操作は比較的新しい技術分野であり、他のすべてと同様に、成長するにつれて成長するサイクルを経ます。
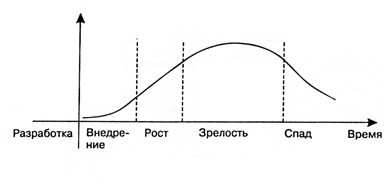
特定の専門家の観点から、このサイクルの各段階での技術分野での仕事には長所と短所があります。
ステージ1.実装最初の段階では、これはR&Dユニットの発案であり、実際の利益はまだ得られません。
賛成論者:それに多くのお金が投資されています。 投資とともに、以前はアクセスできなかったタスクを解決し、投資を回収することへの期待が高まっています。
短所:どんなテクノロジーであっても、最初はどんなに有望であったとしても、独自の制限があります。既存の問題をすべて排除するために使用することはできません。 これらの限界は、新しいアイデアを用いた実験が実行されるにつれて明らかになり、いわゆる「高い期待のピーク」の後に技術への関心が冷めます。
ステージ2.成長実際のテイクオフは、マーケティングのノイズではなく、その本当の能力による失望のくぼみを克服するテクノロジーのみです。
長所:この段階では、技術は長期的な投資を呼び込みます。お金だけでなく、労働市場の専門家の時間です。 これが単なる誇大広告ではなく、新しいアプローチや市場セグメントであることが明らかになったら、スペシャリストが「トレンド」に統合するときです。 これは、キャリアテイクオフの観点から有望な技術を習得するための理想的な瞬間です。
短所:この段階では、技術の文書化はまだ不十分です。
ステージ3.成熟度成熟した技術は、市場の真の主力製品です。
長所:年齢が上がるにつれて、蓄積されるドキュメントの量が増え、トレーニングやコースが表示されるため、テクノロジーを使いやすくなります。
短所:同時に、労働市場での競争が激化しています。
ステージ4.不況衰退の段階(日没)は、すべてのテクノロジーで発生しますが、引き続き機能します。
長所:この時点で、テクノロジーはすでに完全に説明されており、境界は明確であり、膨大な量のドキュメントがあり、コースが利用できます。
短所:新しい知識と展望を獲得するという観点からは、もはやそれほど魅力的ではありません。 実際、これは伴奏です。
成長段階は、新しい専門分野で働き始めたいすべての人にとって最も魅力的です:若い専門家と関連分野の既に確立された専門家の両方にとって。
ビッグデータの開発は現在この段階にあります。 高い期待が残った。 ビジネスでは、ビッグデータが利益を生むことがすでに証明されているため、生産性は横ばいになります。 この瞬間は、労働市場の専門家に素晴らしいチャンスを与えます。
ストーリーのビッグデータ特定の企業へのテクノロジーの導入は、基本的に成長の一般的なサイクルを繰り返します。 ここでの経験は非常に典型的です。
1年半前にX5でビッグデータチームの構築を開始しました。 それから、それは主要な専門家のほんの小さなグループでした、そして今、私たちのほぼ200人がいます。
プロジェクトチームはいくつかの進化段階を経て、その間に役割とタスクをより深く理解しました。 その結果、独自のチーム形式ができました。 アジャイルアプローチに落ち着きました。 主なアイデアは、チームが問題を解決するための能力をすべて備えており、スペシャリスト間でどれだけ正確にそれらを配布するかはもはや重要ではないということです。 これに基づいて、技術の成長を考慮に入れて、チームの役割の構成が徐々に形成されました。 そして今、私たちは:
- 製品所有者(製品所有者)-サブジェクト領域を理解し、一般的なビジネスアイデアを策定し、収益化の方法を予測します。
- ビジネスアナリスト(ビジネスアナリスト)-このタスクに取り組んでいます。
- データ品質(データ品質スペシャリスト)-既存のデータを使用して問題を解決できるかどうかを確認します。
- 直接データサイエンス/データアナリスト(データサイエンティスト/データアナリスト)-数学モデルを作成します(スプレッドシートでのみ動作するものを含むさまざまな亜種があります)。
- テストマネージャー。
- 開発者
この場合、インフラストラクチャとデータはすべてのチームで使用され、次のロールがサービスとしてチームに実装されます。 - インフラ
- ETL(データ読み込みコマンド)。
 どうやってドリームチームに来たの
どうやってドリームチームに来たの
夢ではありませんが、すでに述べたように、ビッグデータ分析の成熟度とX5と流通ネットワークの日常生活への浸透により、チームの構成が変わりました。
「クイックスタート」 -最小の役割、最大の速度
最初のチームには、2つのロールのみが含まれていました。
- 製品所有者がモデルを提案し、推奨事項を作成しました。
- データアナリスト-既存のデータに基づいて収集された統計。
すべてが迅速に計画され、ビジネスで手動で実装されました。
「私たちはそう思いますか?」-私たちはビジネスを理解し、最も有用な結果を生み出すことを学びました
ビジネスと対話するための新しい役割が登場しました。
- ビジネスアナリスト-プロセス要件の説明。
- データ品質-データの一貫性をチェックしました。
- タスクに応じて、データアナリスト/データサイエンティストはデータ統計を分析し、ローカルワークステーションでモデル計算を実行しました。
「さらにリソースが必要」 -ローカル計算タスクがクラスターに移動し、外部システムにアクセスし始めました
必要なスケーリングをサポートするには:
- HADOOPサーバーを作成したインフラストラクチャ。
- 開発者-外部ITシステムとの統合を実装し、この段階でユーザーインターフェース自体をチェックしました。
データアナリスト/データサイエンティストは、クラスターでモデルを計算するためのいくつかのオプションをチェックできるようになりましたが、ビジネスでの手動の実装は依然として維持されていました。
「負荷は増え続けます」 -新しいデータが表示され、それらを処理するには新しい容量が必要です
これらの変更はチームに反映できませんでした:
- インフラストラクチャは、増加する負荷の下でHADOOPクラスターを開発しました。
- ETLチームは、定期的なデータのダウンロードと更新を開始しました。
- 機能テストが登場しました。
「すべての自動化」 -テクノロジーが定着しました。ビジネスの実装を自動化するときです
この段階で、DevOpsがチームに登場し、機能の自動アセンブリ、テスト、およびインストールをセットアップしました。
チームビルディングに関する重要な考え方1.当初から適切な専門家がいなかった場合、すべてがうまくいくという事実ではなく、その周りにチームを構築できました。 これは、筋肉が成長し始めた骨格です。
2.ビッグデータ市場は完全にグリーンであるため、それぞれの役割に十分な「準備された」専門家はいません。 もちろん、先輩の部門全体を採用することは非常に便利ですが、明らかに、そのような「スター」チームは多くは構築できません。 「既製の」人員だけを追いかけないことにしました。 先ほど述べたように、アジャイルを堅持し、特定の問題を解決する能力がチーム全体にあることだけに注意する必要があります。 言い換えれば、特定の技術的および数学的な基盤を持つ1人のチームの専門家と初心者を取り込んで(そして取り込んで)、望ましい結果を達成するために必要な一連の能力を形成することができます。
3.各役割は、ビッグデータを扱う原則の理解を意味しますが、この理解の深さが必要です。 テスター、アナリストなど、古典的な開発に直接類似する役割の最大の変動性 彼らにとって、ビッグデータに属することがほとんど見えないタスクと、もう少し深く掘り下げる必要があるタスクがあります。 何らかの方法で、キャリアを開始するには、特定の経験、ITの理解、学習への欲求、および使用されているツールに関するいくつかの理論的知識(記事を読むことで取得可能)で十分です。
4.技術はよく知られており、多くの人がそれをやりたいという事実にもかかわらず、ビッグデータでのキャリアを始めるのにふさわしい(そしてそこで心から働きたい)すべての専門家が本当にここに来ようとするわけではない。
多くの優秀な候補者は、BigDataチームでの作業は厳密にデータサイエンスであると考えています。 エントリのしきい値が高いアクティビティの基本的な変更とは何ですか。 しかし、彼らは自分の能力を過小評価しているか、さまざまなプロフィールの人々がビッグデータで求められていることを知らないだけで、別の役割でキャリアを開始する方が簡単です-上記のいずれか。
a。 実際、多くの役割で混合チームで作業を開始するには、ビッグデータの分野で狭い専門的な教育を必要としません。
b。 混合構造ユニットを構築するという考えを固守して、チームを積極的に拡大しました。 そして、最も興味深いのは、以前にビッグデータを扱ったことのない私たちのタスクに来た人々が、タスクに対処して、会社に完全に定着したことです。 彼らはビッグデータの実践を短時間で学ぶことができました。
5.十分な経験がなくても、プロジェクト内のより戦略的なタスクに対処するために、このセグメントで成長するように動機付けられ、より深く潜り、必要な言語とツールを学ぶことができます。 そして、蓄積された経験は、ビッグデータの知識が必要な役割に切り替え、この方向のロジックを理解するのに役立ちます。 ところで、この意味で、混合チームは開発を加速するのに大いに役立ちます。
BigDataにアクセスする方法は?
私たちの場合、異なるレベルのスペシャリストのバランスの取れたチームのアイデアは「出発」しました-グループはすでに複数の内部プロジェクトを実施しています。 既成の人員が不足し、そのようなチームのビジネスニーズが増加すれば、他の企業も同じシナリオに直面するでしょう。
この方向を真剣に選択したい場合は、Data Sciense-Kaggle、ODS、およびその他の特殊なリソースに没頭すると役立ちます。 さらに、近い将来、データサイエンティストの役割に自分自身が見えない場合でも、その方向自体に興味があるなら、ビッグデータにはまだ必要です!
価値を高めるには:
- あなたの数学の知識を更新します。 通常のビッグデータの問題を解決するには、博士号は必要ありませんが、高等数学の基礎知識は依然として必要です。 統計の根底にあるメカニズムを理解すると、プロセスを簡単に認識できるようになります。
- 現在の専門分野に最も近い役割を選択してください。 この役割(および行きたい特定の会社)で直面する課題を見つけてください。 同様の問題を以前に解決したことがある場合は、履歴書でそれらを強調する必要があります。
- 選択した役割に固有のツールは、たとえビッグデータには関係ないと思われる場合でも、非常に重要です。 たとえば、内部ソリューションを開発する場合、複雑なインターフェイスを扱う多くのフロントエンド開発者が必要であることがわかりました。
- 市場は活発に発展していることを忘れないでください。 誰かが内部でチームを構築し、活気づけていますが、誰かは労働市場で既製の専門家を見つけることを期待しています。 あなたが初心者の場合、強力なチームに参加してみてください。そこでは、追加の知識を得る機会があります。
PSところで、現在、私たちは積極的に成長を続けており、
データエンジニア 、
テストスペシャリスト 、
React開発者 、および
UI / UXスペシャリストを探してい
ます 。 5月10〜11日に、#bigdatax5での作業を含めることをDataFestのブースの全員と
話し合います。