推奨システム:
- 車からのヒント
- コールドスタート
- ハイブリッドシステムの概要
-人工免疫システムとイディオタイプの効果
データマイニングとレコメンデーションシステムに関するさまざまな出版物を読んでいるときに、そのようなシステムの実装に対する興味深いアプローチを偶然見つけました。 これは、
人工免疫システム (IMS)の概念に基づいており、それに従って、学習および記憶する能力を含む、生体の免疫システムのいくつかの特性がコンピューターシステムで実現されます。 推奨システムは、特定の抗原に反応する抗体の濃度を記述するモデルを使用します。 特に興味深いのは、いわゆる
イディオタイプの効果 (
Idiotype )であり、抗体の濃度は抗原との類似性だけでなく、相互の類似性にも依存することを示しています。
生物学に精通していない人のために、私は問題の本質を簡単に説明します。
抗原は、摂取すると免疫系からの応答を誘発する物質です。 それに応じて、刺激を特定し中和するために使用される特定のクラスのタンパク質である
抗体を生成します。 私たちの場合、抗原はユーザーであり、抗体はあなたがそれと比較しているオブジェクトです。 これを想像しやすくするために、他のユーザーが抗体である集合フィルタリングシステムを検討していると考えることを提案します。
数学的な説明
それでは、ビジネスに取り掛かりましょう。 抗体の濃度を記述する方程式は、
J。Doyne Farmerによって提案されました
。
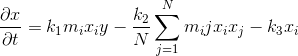
ここで:
m
i-抗原と抗体iの類似性、
x
iおよびx
jは、それぞれ抗体濃度iおよびjです。
yは抗原の濃度、
m
ijは、抗体iとjの類似性です。
k
1-刺激係数、
k
2は抑制係数、
k
3-死亡率、
Nは抗体の数です。
各用語を個別に検討します。
- 抗体刺激は問題を引き起こさないはずです。 この用語は、抗原に近づくと抗体の濃度を増加させます。
- 抗体抑制ははるかに興味深いです。 前述のイディオタイプの効果が存在するのはこの用語です。 集団フィルタリングシステムの場合、抗原を私たちと比較するユーザーがそれに似ているだけでなく、お互いにほとんど似ていない場合、結果が増加します。 これにより、より多様なユーザーのセットを作成できます。
- 最初の2つの項の絶対値がほぼ等しい場合、死亡率は結果を減少させます。 彼のおかげで、良くも悪くもない抗体は自分で排除されます。
動作原理
このようなシステムのアルゴリズムは非常に単純です。
1.データベースから最初の抗体を取り出し、記載されている式に従ってその濃度を計算します。
2.結果は、明らかに、それが特定の最小値を下回っている場合、正と負の両方になる可能性があります-抗体を破棄し、以下を取ります。
3.抗体がなくなるか、システムが
安定するまで 、つまり、最後のプラスまたはマイナス10回の繰り返しで結果が変わらない場合、このサイクルを続けます。
IISには、他の推奨システムとの2つの主な違いがあります。
- 比較するオブジェクトを選択する別の原則。 一般的な集合フィルタリングシステムで最も類似したユーザーが選択されると、IISはイディオタイプの効果も追加します。これにより、最終的な選択がより多様になります。 この効果は、新しいコレクションを作成するだけでなく、既存のコレクションを改善するためにも使用できます。
- 評価の計算方法自体は異なります。 従来のシステムでこれが単にある種の相関係数である場合、IMSではこの係数に得られた濃度が乗算されます。
例
読者の要望に応じて、IMSの簡単な使用例を紹介します。 何らかの方法で取得したユーザーA、B、C、Yの相関テーブルがあると仮定すると、システムは集合フィルタリングの原理で動作するため、ユーザーYに似た2人のユーザーを見つけ、その声を使用してユーザーYの声をさらに予測する必要がありますこの例では、このテーブルをどのように取得し、将来どのように結果を使用するかについては検討しません。 イディオタイプの効果が、必要なユーザーの選択にどのように影響するかについてのみ検討します。
| A | B | C | Y |
| A | 1 | 0.2 | 0.8 | 0.9 |
| B | 0.2 | 1 | 0.6 | 0.8 |
| C | 0.8 | 0.6 | 1 | 0.85 |
| Y | 0.9 | 0.8 | 0.85 | 1 |
通常のシステムでは、ユーザーBとCが明白な選択肢になり、彼らも正しいでしょう。
IISが提供するものを見てみましょう。 ユーザーBとCの集中度を計算します。式が目の前にあるようにします。
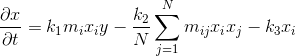
2人のユーザーN = 2を選択する必要があるため、k
1 = 0.3、k
2 = 0.2、k
3 = 0.1、y = 1とします。
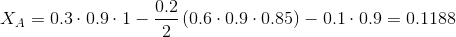
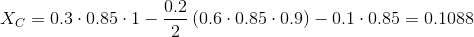
採用した最小濃度値が0.11であるとします。 X
Cは明らかにそれに適合しないため、その代替品を探す必要があります。 ユーザーBを検討します。
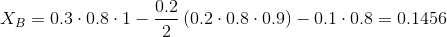
ご覧のとおり、ユーザーYとの類似性はユーザーCのそれよりもわずかに低いという事実にもかかわらず、BはCよりもAに似ていないため、その集中度は著しく高くなっています。ユーザーCをBに置き換えたため、他のユーザーに依存するため、ユーザーAの集中度:

濃度を計算することにより、ユーザーYとユーザーの類似性を適宜調整できます。
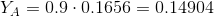
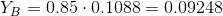

おわりに
公開されたテスト結果によると、IISは他のシステムよりも正確な結果を提供しますが、その成功の理由は、上記の特定の要因の影響ではなく、相互作用にあります。 詳細については、ソースを確認することをお勧めします。
1. Steve CayzerとUwe Aickelin「 免疫ネットワークに基づく推薦システム 」(pdf)
2. Steve CayzerとUwe Aickelin " 推奨のためのイディオタイプの相互作用の影響について
人工免疫システムのコミュニティ "(pdf)
3. Q ChenとU Aickelin「 人工免疫システムを使用した映画推薦システム 」(pdf)私のブログのオリジナル