さて、私たちはさまざまなデータ形式からテキストを取得することについての研究を続けています。 少し前まで、
zip形式のxmlベースのファイル (odtとdocx)からテキストを抽出する方法と、今週の初めから
pdfからテキストを抽出する方法を学びました。 今日は約束のrtfを続けます。
リッチテキスト形式(別名rtf)は、テキストデータを表すための非常に複雑な形式では
ありませんが
、かなり忘れられていると思われるかもしれません 。 まあ、テキストを取得するのは比較的簡単ですが、その歴史から:最初のバージョンから現在の1.9.1まで-300ページの公式ドキュメントと膨大な数のアドオンを取得しました。 それらを回避してみましょう...
そして中身は何ですか?
それが起こったので、rtfファイルの中を見て、中身を見てみましょう:
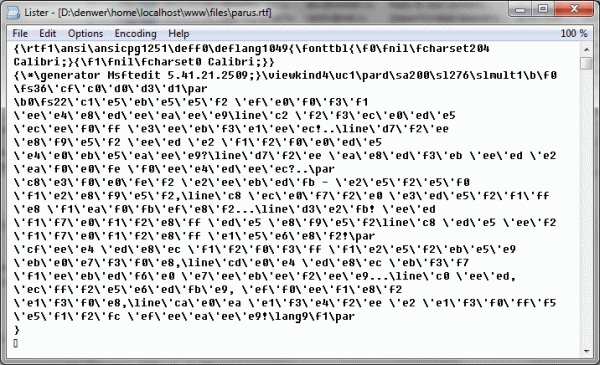
何が見えますか?
私たちのお気に入りの詩「帆」が見えます。 最初はテキスト形式の8ビットデータ形式が表示されます。 これはすでに喜ばしいことです。ソースデータ内のテキストを使用すると、何が起きているかを理解するのがはるかに簡単になります。 それでは、このデータそのものの読み方を理解しましょう。 これを行うために、このトピックに関する少しの理論を説明します。
rtfは、ネストされたセットに
グループ化できる
制御ワードで構成されていると想定しています。 制御語はバックスラッシュ(
\ )で始まり、グループは中括弧(
{および
} )で囲まれます。
制御ワードは、英語のアルファベットの文字のシーケンス(
aから
z )で構成され、数値パラメーター(負の場合もある)で補完できます。 または、単語に英数字以外のASCII文字を1つ含めることができます。 これらの規則に当てはまらないものは、制御ワードの一部ではありません。 したがって、
\rtf1\ansi\ansicpg1251の形式のシーケンスは、パラメーター1(形式のメジャーバージョン)の
rtf 、
ansi (現在のエンコード)、およびパラメーター1251の
ansicpg (
ansicpg現在のコードページ番号)の3つの単語に簡単に分割されます。 Windows-1251)。
グループ化されたセットは、制御ワードの範囲を定義します。 したがって、中括弧内に記述されている制御ワードは、その中とすべての子サブセット内でのみ機能します。 現在どの単語が起こっているのかを正しく理解するには、制御単語のスタックを保持する必要があります。 中括弧を開くときは、スタック内に新しい配列要素を作成します。この配列要素にすぐにスタックの前のレイヤーのデータを追加し、ブレースを閉じるときに最上位のレイヤーを削除します。
また、新しいサブグループを作成するのではなく、パラメータゼロを追加することで一部の制御ワードを閉じることができることにも注意してください。 たとえば、次のオプションは同等です。
This is {\b bold} text 、
This is \b bold \b0 text =
This is bold textです。
テキストはどこで入手できますか?
私たちは私たちのために新しい形式のデバイスに会いました、今、私たちは自分自身に質問をします、どこでテキストを入手するか。 すべては見た目ほど複雑ではありません-現在のシーケンスが制御ワードとして識別されていない場所でテキストを使用する必要があります。 もちろん、いくつかの例外があります。
まず、rtfファイルのソースエンコーディングがANSIであることに注意する価値があります。したがって、飾り気なく、英語のテキストのみが保存されます。 少なくともロシア語のテキストに興味があり、さらに優れたUnicodeに興味がありますか? 真実は、rtfは古い形式ですが、両方を保存するのに適しているということです。
したがって、rtfでは、ASCIIテーブルの後半、128以上のテーブルを使用する可能性があります。 もちろん、現在のエンコーディング(制御ワード
\ansicpg )が与えられます。 これを行うために、RTFに
\'hhの形式のシーケンスが導入されました。hhはASCIIテーブルの文字のバイナリ16進コードです。
2番目のより興味深いオプションは、ユニコードでエンコードされたデータです。 それらの場合、形式には数値パラメータABCDを含む簡潔な短いキーワード
\uABCDが含まれます。 この場合のABCDは、10進数のUnicode文字コードです。 あなたが気づいたかもしれないように、すべてが再び簡単です。
シンプルですが、それほどではありません。
\ucNには、Unicodeに密接に関連する別の
\ucNキーワードがあります。 実際、RTF形式は、このファイルを開く必要のある古いデバイスとの互換性を非常に熱心にサポートしています。 オプションとして、そのようなデバイス(たとえば、Windows 3.11を搭載したコンピューター:)はUnicodeを読み取ることができません。どうすればよいですか? これを行うには、
\uキーワードで暗号化された各ユニコード文字の後に、rtf-viewerが現在のデータを表示または解析できない場合に表示されるゼロから数文字を示すことができます(ドキュメントによると、ビューアが正しく表示できない場合)データ、彼はそれらをスキップする必要があります)。
この点で、ほとんどの最近のエディターは、ユニコード制御ワードの後に、現在の文字の代わりに表示したい記号として疑問符を付けます。 ただし、オプションは可能
Lab\u915GValue 。例:
Lab\u915GValue Unicodeを表示できない場合に表示する必要がある文字数を自問してみましょう。 ここでもすべてはそれほど複雑ではありません-上記のキーワード
\ucNはパラメーターNとしてこの値を提供します。 つまり Unicodeデータの前には、
\uc1ようなものが必ず表示されます。これにより、Unicodeの後に1文字スキップするように指示されます。
読んでみよう!
蓄積したデータは、最初のrtfファイルを読み取るのに十分なようです。 行こう:
- 関数 rtf_isPlainText ( $ s ) {
- $ failAt = array ( "*" 、 "fonttbl" 、 "colortbl" 、 "datastore" 、 "themedata" ) ;
- for ( $ i = 0 ; $ i < count ( $ failAt ) ; $ i ++ )
- if ( ! empty ( $ s [ $ failAt [ $ i ] ] ) ))は falseを 返し ます 。
- trueを 返し ます 。
- }
- 関数 rtf2text ( $ filename ) {
- $ text = file_get_contents ( $ filename ) ;
- if (! strlen ( $ text ) )
- return "" ;
- $ document = "" ;
- $ stack = array ( ) ;
- $ j = -1 ;
- for ( $ i = 0 ; $ i < strlen ( $ text ) ; $ i ++ ) {
- $ c = $ text [ $ i ] ;
- スイッチ ( $ c ) {
- ケース 「 \\ 」 :
- $ nc = $ text [ $ i + 1 ] ;
- if ( $ nc == '\\' && rtf_isPlainText ( $ stack [ $ j ] ) ) $ document 。= '\\' ;
- elseif ( $ nc == '〜' && rtf_isPlainText ( $ stack [ $ j ] ) )) $ document 。= '' ;
- elseif ( $ nc == '_' && rtf_isPlainText ( $ stack [ $ j ] ) ) $ document 。= '-' ;
- elseif ( $ nc == '*' ) $ stack [ $ j ] [ "*" ] = true ;
- elseif ( $ nc == "'" ) {
- $ hex = substr ( $ text 、 $ i + 2、2 ) ;
- if ( rtf_isPlainText ( $ stack [ $ j ] ) )
- $ document 。= html_entity_decode ( "&#" 。 hexdec ( $ hex ) 。 ";" ) ;
- $ i + = 2 ;
- } elseif ( $ nc > = 'a' && $ nc <= 'z' || $ nc > = 'A' && $ nc <= 'Z' ) {
- $ word = "" ;
- $ param = null ;
- for ( $ k = $ i + 1 、 $ m = 0 ; $ k < strlen ( $ text ) ; $ k ++、 $ m ++ ) {
- $ nc = $ text [ $ k ] ;
- if ( $ nc > = 'a' && $ nc <= 'z' || $ nc > = 'A' && $ nc <= 'Z' ) {
- if ( empty ( $ param ) )
- $ワード = $ nc ;
- 他に
- 休憩 ;
- } elseif ( $ nc > = '0' && $ nc <= '9' )
- $ param 。= $ nc ;
- elseif ( $ nc == '-' ) {
- if ( empty ( $ param ) )
- $ param 。= $ nc ;
- 他に
- 休憩 ;
- } その他
- 休憩 ;
- }
- $ i + = $ m - 1 ;
- $ toText = "" ;
- switch ( strtolower ( $ word ) ) {
- ケース 「u」 :
- $ toText 。= html_entity_decode ( "&#x" 。dechex ( $ param ) 。 ";" ) ;
- $ ucDelta = @ $ stack [ $ j ] [ "uc" ] ;
- if ( $ ucDelta > 0 )
- $ i + = $ ucDelta ;
- 休憩 ;
- ケース "par" : ケース "page" : ケース "column" : ケース "line" : ケース "lbr" :
- $ toText 。= " \ n " ;
- 休憩 ;
- ケース "emspace" : ケース "enspace" : ケース "qmspace" :
- $ toText 。= "" ;
- 休憩 ;
- case "tab" : $ toText 。= " \ t " ; 休憩 ;
- case "chdate" : $ toText 。= date ( "mdY" ) ; 休憩 ;
- case "chdpl" : $ toText 。= date ( "l、j F Y" ) ; 休憩 ;
- case "chdpa" : $ toText 。= date ( "D、j M Y" ) ; 休憩 ;
- case "chtime" : $ toText 。= date ( "H:i:s" ) ; 休憩 ;
- case "emdash" : $ toText 。= html_entity_decode ( "&mdash;" ) ; 休憩 ;
- case "endash" : $ toText 。= html_entity_decode ( "&ndash;" ) ; 休憩 ;
- case "bullet" : $ toText 。= html_entity_decode ( "&#149;" ) ; 休憩 ;
- case "lquote" : $ toText 。= html_entity_decode ( "&lsquo;" ) ; 休憩 ;
- case "rquote" : $ toText 。= html_entity_decode ( "&rsquo;" ) ; 休憩 ;
- case "ldblquote" : $ toText 。= html_entity_decode ( "&laquo;" ) ; 休憩 ;
- case "rdblquote" : $ toText 。= html_entity_decode ( "&raquo;" ) ; 休憩 ;
- デフォルト :
- $ stack [ $ j ] [ strtolower ( $ word ) ] = empty ( $ param ) ? true : $ param ;
- 休憩 ;
- }
- if ( rtf_isPlainText ( $ stack [ $ j ] ) )
- $ document 。= $ toText ;
- }
- $ i ++;
- 休憩 ;
- ケース "{" :
- array_push ( $ stack 、 $ stack [ $ j ++ ] ) ;
- 休憩 ;
- ケース 「}」 :
- array_pop ( $スタック ) ;
- $ j- ;
- 休憩 ;
- case '\ 0' : case '\ r' : case '\ f' : case '\ n' : break ;
- デフォルト :
- if ( rtf_isPlainText ( $ stack [ $ j ] ) )
- $ドキュメント = $ c ;
- 休憩 ;
- }
- }
- $ documentを 返し ます 。
- }
GitHubにコメントを付け
てコードを取得でき
ます 。
おわりに
最後に何がありますか? このコードはほとんどのrtfファイルを正しく処理しますが、改善する方法がいくつかあります。 まず、非テキストデータに追加のクリッピングを追加する価値があります。フォント、カラーパレット、スキン、バイナリデータ、および「できない場合は読み上げない」とマークされているすべて(
\* )のみを切り取ります。 次に、
\'hh形式のキーワードをより正確に表示するために、エンコーディングとコードページを解析する価値があります。
次は? さらに、fb2、epubなどの電子書籍形式に触れたいと思います。 この点に関して、読者に助けを求めたいと思います。第一に、他のどの形式の電子書籍を見る価値があるのか、第二に、指定した形式のファイルをもっと見つけることができる場所です。 事前に感謝します:)
参照: