素晴らしい本「Programming a Collective Mind」は、クラスター分析のトピックに関する動機に基づいてこの投稿を書くように私を刺激しました。
ある投稿では、クラスター分析、Pythonでのその美しい実装、特にクラスターの視覚的表現である
樹状図を検討したいという要望がありました。
サンプルコードは、本のサンプルコードに基づいています。
クラスター分析の主なアイデアは、要素が多少似ているデータグループのセットから分離することです。 このような分析のフレームワークでは、実際には、研究対象データの特定の分類がグループへの分布のために発生します。 これらのグループは階層的に順序付けられており、分析後の結果のクラスターの構造はツリーの形で表すことができます-樹形図(ご存知の「デンドロ」、ギリシャ語の「ツリー」)。
各タスクの類似性の尺度は異なるように設定できますが、最も単純なものは
ユークリッド距離と
ピアソン相関係数です。 この例では、ピアソン相関係数を調べていますが、簡単に置き換えることができます。
一般に、歴史的にクラスター分析は人文科学で最も人気があり、それが適用された最初のタスクの1つは古代の埋葬に関するデータの分析でした。
クラスターを構築するためのアルゴリズムは、原則として、シンプルで論理的です。
アルゴリズム
の初期データは、いくつかの要素のリストと、それらの間の類似性の関数(要素の「近接度」)です。 各要素には、特定の空間(たとえば、単語の数の空間)に「座標」があり、それによって要素間の類似性が計算されます。
例:要素-ブログ、2つの「座標」-ブログのコンテンツ内の単語「php」と「xml」の数。
ブログ番号1-7回で「php」という単語が見つかり、5回で「xml」が見つかりました。 これらの単語の数のスペースでのブログ番号1の「座標」は(7; 5)です。
ブログ番号2-6回で「php」という単語が見つかり、4回で「xml」が見つかりました。 次に、これらの単語の数のスペースにあるブログ番号2の「座標」-(6; 4)。
類似性は、関数-ユークリッド距離を使用して決定されます。
d(blog1, blog2) = sqrt( (7-6)^2 + (5-4)^2) = 1.414
出力では、クラスターのツリー(クラスター階層)を取得します。
アルゴリズムは次のように機能します。1)ステップ1:ソースリストの各要素をクラスターと見なし、それらを
結合リストに追加し
ます2)ステップ2-N:最も近いクラスターを見つけて、それらを新しいクラスターにマージします(新しいクラスターの「座標」-結合されるクラスターの「座標」の合計の半分)。 新しい
プールをプールリストに追加し、
リストから元のクラスターを削除し
ます 。 したがって、
マージリストの各ステップで
は、要素が少なくなります。
停止基準 :1つのクラスターのみ
の統合のリストに存在し、結合するものは何もありません(1つを取得すると、「ルート」クラスター)
hcluster関数は、このアルゴリズムを実装します。
- def hcluster(行、距離=ピアソン):
- 距離= {}
- currentclustid = -1
- #クラスターは最初は単なる行です
- clust = [bicluster(rows [i]、id = i) for i in range(len(rows))]]
- while len(clust)> 1:
- 最低ペア=(0,1)
- 最も近い=距離(clust [0] .vec、clust [1] .vec)
- #すべてのペアをループして最短距離を探します
- 範囲内のi(len(clust)):
- 範囲内のj(i + 1、len(clust))の場合:
- #distancesは距離計算のキャッシュです
- if (clust [i] .id、clust [j] .id)距離にない場合:
- 距離[(clust [i] .id、clust [j] .id)] =距離(clust [i] .vec、clust [j] .vec)
- d =距離[(clust [i] .id、clust [j] .id)]
- d <最も近い場合 :
- 最も近い= d
- 最低ペア=(i、j)
- #2つのクラスターの平均を計算する
- mergevec = [
- (clust [lowestpair [0]]。vec [i] + clust [lowestpair [1]]。vec [i])/ 2.0
- for iの範囲(len(clust [0] .vec))]
- # 新しいクラスターを作成
- newcluster = bicluster(mergevec、左= cluster [lowestpair [0]]、
- 右=クラスター[最低ペア[1]]、
- 距離=最も近い、id = currentclustid)
- #元のセットになかったクラスターIDは負です
- currentclustid- = 1
- del clust [lowestpair [1]]
- del clust [lowestpair [0]]
- clust.append(newcluster)
- 好奇心を返す[0]
*このソースコードは、 ソースコードハイライターで強調表示されました。
この例では、プログラミングブログのコンテンツのクラスター分析の例を検討します。 この本は英語のブログについて説明していますが、私は35のロシア語の用語を英語の用語の出現に関して分析することにしました。 分析の結果を表示するには、ブログの名前を小さなライブラリを使用して翻訳する必要がありました。
Pythonのすべての必要なファイルとスクリプトを含む完全なアーカイブをダウンロードできます
-cluster.zipアーカイブの構成:
blogdata.txt –
clusters.py -
draw_dendrograms.py - ( clusters.py)
feedlist.txt - RSS
generatefeedvector.py - blogdata.txt
translit.py, utils.py -
RSSブログのリストを含むfeedlist.txtの場合、たとえば、次のコンテンツ(検索
http://lenta.yandex.ru/feed_search.xml?text=programmingから取得)を取得できます。
feeds.feedburner.com/nayjest
www.codenet.ru/export/read.xml
feeds2.feedburner.com/simplecoding
feeds2.feedburner.com/nickspring
feeds2.feedburner.com/Sribna
community.livejournal.com/ru_cpp/data/rss
community.livejournal.com/ru_lambda/data/rss
feeds2.feedburner.com/rusarticles
feeds2.feedburner.com/Jstoolbox
feeds2.feedburner.com/rsdn/cpp
4matic.wordpress.com/feed
www.nowa.cc/external.php?type=RSS2
www.gotdotnet.ru/blogs/gaidar/rss
community.livejournal.com/ru_programmers/data/rss
www.compdoc.ru/rssdok.php
feeds2.feedburner.com/rsdn/philosophy
softwaremaniacs.org/blog/feed
community.livejournal.com/new_ru_php/data/rss
www.newsrss.ru/mein_rss/rss_cdata.xml
feeds2.feedburner.com/5an
subscribe.ru/archive/comp.soft.prog.linuxp/index.rss
feeds.feedburner.com/mrkto
rbogatyrev.livejournal.com/data/rss
feeds2.feedburner.com/poisonsblog
community.livejournal.com/ruby_ru/data/rss
feeds2.feedburner.com/devoid
rgt.rpod.ru/rss.xml
feeds2.feedburner.com/rsdn/decl
feeds2.feedburner.com/Toeveryonethe
www.osp.ru/rss/Software.rss
feeds2.feedburner.com/Freshcoder
blogs.technet.com/craftsmans_notes/rss.xml
feeds2.feedburner.com/RuRubyRails
feeds2.feedburner.com/bitby
opita.net/rss.xml
樹状図構築プログラム自体は、順次起動される2つのスクリプト(データ収集+処理)で構成されます。
python generatefeedvector.py
python draw_dengrograms.py
この例が機能するには、Python Imaging Library(PIL)が必要です。これは
www.pythonware.com/products/pilからダウンロードできます。
解凍後、通常どおりインストールされます。
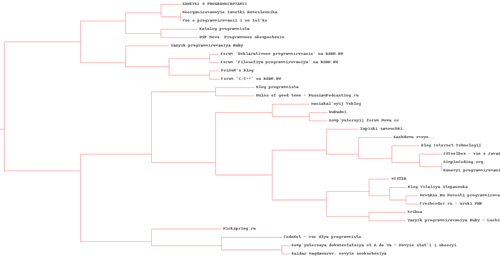
python setup.py installそして、ここが最も興味深い瞬間です。 スクリプトの結果、次の樹状図が取得されました。
1)ブログ用(完全な品質
-img-fotki.yandex.ru/get/4100/serg-panarin.0/0_21f52_b8057f0d_-1-orig.jpg )
2)単語の場合(完全な品質
-img-fotki.yandex.ru/get/4102/serg-panarin.0/0_21f53_dcdea04f_-1-orig.jpg )
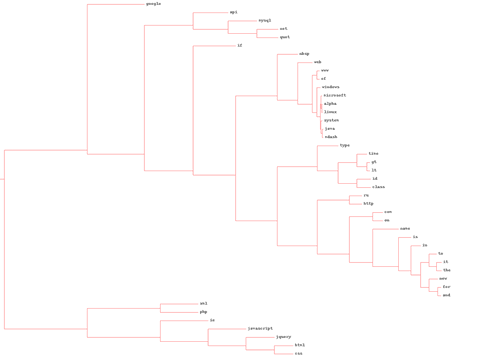
feedlist.txtを変更することにより、任意のブログを分析し、樹状図を取得できます。