5th
Call Hierarchy Resharperの新機能についてはすでに書いています。 呼び出し階層の論理的な開発は、値追跡です。 値追跡は、開発者がプログラム内の特定のポイントに間違ったデータがどのように到達するか、またはこのデータがどこに移動するかを理解するのに役立つように作成されました。 その結果、
NullReferenceExceptionまたは不正な動作と出力の原因を調査することが容易になります。
繰り返しますが、深く理論化することはしませんが、どのように、どのようなシナリオでバリュートラッキングが機能するかを簡単に示します。
簡単な例
簡単な例を考えてみましょう。
VisitDataメソッドでは、
VisitDataが発生します
VisitDataがどこから来たのかを調べてみましょう。
VisitDataメソッドで
dcパラメーターを使用するキャレットを配置し、分析を実行します(
R#-> VisitData > Value Origin ):
public class Main
{
void Start()
{
Console .WriteLine(Do( new DataClass()));
}
void Start2()
{
Console .WriteLine(Do( null ));
}
int Do(DataClass data)
{
var v = new Visitor();
return v.VisitData(data);
}
}
public class DataClass
{
public int GetData()
{
return 0;
}
}
public class Visitor
{
public int VisitData(DataClass dc)
{
return dc.GetData();
}
}
*このソースコードは、 ソースコードハイライターで強調表示されました。

上記の例を使用して独立して分析を開始し、結果ツリーをナビゲートすると、プログラマーにとって興味深いすべてのノードがツリーに含まれていることがわかります。
dcの直接使用(例外が発生する正確な場所)dataパラメーターをVisitDataメソッドにVisitData- 「良いデータ」を使用して
Doメソッドを呼び出します(ツリーでは、関心のあるデータが太字で強調表示されています ) null Doメソッドを呼び出すことは、あなたが探している問題です
概して、大規模なFind Usagesのみが行われました。 しかし、ValueTracking:
- マイナーなステップをスキップして時間を節約
- データを便利な形式で表示します。 問題への集中を失うことなく、シンボルのすべての使用を目で追跡することなく、問題の原因を見つけることができます。
値の追跡は、変数名が絶えず変化し、データがコレクションに追加され、クロージャーを介して送信される場合に特に便利です。 これらのより複雑で興味深いケースを検討していきましょう。
継承
今回は、インターフェース、その実装、フィールド、フィールド初期化子、コンストラクターがあります。
Main.Startメソッドが表示できる値を把握してみましょう。 これを行うには、式
dataProvider.Fooを選択し、Value Originを呼び出します。
public interface IInterface
{
int Foo();
}
public class Base1 : IInterface
{
public virtual int Foo()
{
return 1;
}
}
public class Base2 : IInterface
{
private readonly int _foo = 2;
public Base2()
{
}
public Base2( int foo)
{
this ._foo = foo;
}
public virtual int Foo()
{
return _foo;
}
}
public class Main
{
public void Start(IInterface dataProvider)
{
Console .WriteLine(dataProvider.Foo());
}
public void Usage()
{
Start( new Base2(3));
}
}
* This source code was highlighted with Source Code Highlighter .

バリュートラッキングの結果には以下が表示されます。
1定数を返すFooメソッドの実装Fooメソッドの実装_fooフィールドの値と、 _fooフィールドのすべての値のソースを返します。- コンストラクターでこのフィールドに値を割り当てる
- パラメーター
3を使用したコンストラクター呼び出し - 値
2このフィールドの初期化子
つまり ほんの数ステップで、すべての可能な値が見つかりました。 分岐階層と複雑なロジックがある場合、どれくらいの時間を節約できるか想像してみてください。
コレクション
次に、コレクションの操作を検討します。 次のコードを使用して、画面に表示されるすべての値のセットを見つけてみましょう。 これを行うには、
Console.WriteLine内で
i使用を開始し、Value Origin分析を実行します。
class Main
{
void Foo()
{
var list = new List < int >();
list.AddRange(GetData());
list.AddRange(GetDataLazy());
ModifyData(list);
foreach ( var i in list)
{
Console .WriteLine(i);
}
}
void ModifyData( List < int > list)
{
list.Add(6);
}
private IEnumerable < int > GetData()
{
return new [] { 1, 2, 3 };
}
IEnumerable < int > GetDataLazy()
{
yield return 4;
yield return 5;
}
}
* This source code was highlighted with Source Code Highlighter .
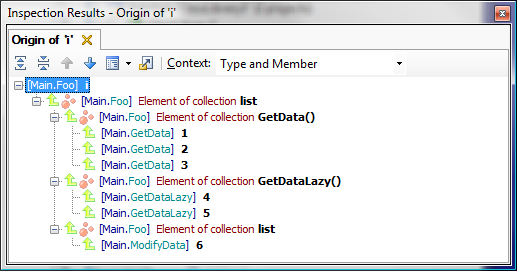
配列の明示的な作成、遅延列挙子からの値、および
Addメソッドの呼び出しの両方が見つかりました。 いいね!
反対方向のコレクション、または値の行き先
それでは、反対の方向で試してみましょう
5番の位置を確認してください。 それを選択して、Value Destinationを呼び出します。
public class testMy
{
void Do()
{
int x = 5;
var list = Foo(x);
foreach ( var item in list)
{
Console .WriteLine(item);
}
}
List < int > Foo( int i)
{
var list = new List < int >();
list.Add(i);
return list;
}
}
* This source code was highlighted with Source Code Highlighter .

すぐに、数
5わかりました。
Fooメソッドに渡される- コレクションに追加されました
- コレクションが返されて使用されます
- コレクションアイテムが表示されます。
この例と前の例では、値の追跡が値の追跡からコレクションの追跡に移行するとすぐに、ツリー内の対応するノードが特別なピンクのアイコンでマークされます。
ラムダス
ラムダは、それらと一緒に、特にそれらがたくさんあり、彼らが囲まれていると戦わせない場合、問題が絶えず発生します。 次の状況でR#がどのように機能するかを見てみましょう。 この場合、両方向の値をトレースしてみましょう。
public class MyClass
{
void Main()
{
var checkFunction = GetCheckFunction();
Console .WriteLine(checkFunction(1));
}
Func< int , bool > GetCheckFunction()
{
Func< int , bool > myLambda = x =>
{
Console .WriteLine(x);
return x > 100; //
};
return myLambda;
}
}
* This source code was highlighted with Source Code Highlighter .
最初に、パラメーター
x値がどこから来るかを探します。
Console.WriteLine呼び出しで使用を選択し、Value Originを呼び出します。

- ラムダパラメータを含むが見つかりました
- さらに、このラムダが送信される場所を分析しました。 lambdaを追跡するすべてのノードには、特別なアイコンが付いていることに注意してください。
- 最後のステップでは、ラムダが引数
1で呼び出されることがわかります。これはx望ましい値です
ここで、ラムダによって返される値が使用されている場所を見つけてみましょう。
x>100選択し、Value Destination(
R#-> Inspect-> Value Destination )を呼び出します。

- 分析は、ラムダ実行の結果として返される式を追跡します
- 次に、R#はラムダが通過した場所を追跡しました
- 最後に、ラムダによって返された値を使用する
WriteLineメソッドの呼び出しがあります。
画面(
Console.WriteLine )の出力を2行に置き換えることで、ネストされたラムダを使用したより複雑な例を簡単に作成できます。
Func<Func< int , bool >, int , bool > invocator = (func, i) => func(i);
Console .WriteLine(invocator (checkFunction,1));
* This source code was highlighted with Source Code Highlighter .
分析は引き続き機能し、式
x>100値がどこに行くかを簡単に把握できます。 ラムダが埋め込まれたコードは、普通の人が理解するのが非常に難しく、分析がさらに一般的になります。 さらに、ネストされたラムダのコレクションを作成しようとすることができます-それは動作します! しかし、私はそのような演習を読者と難しい実生活に任せます。