はじめに
x86 Intel AVXプロセッサ向けの新しいSIMD命令セットは、2008年3月に公開されました。 これらの命令のハードウェアへの実装はさらに6か月待機しますが、AVX仕様はすでに確立されていると見なすことができ、コンパイラとアセンブラの新しいバージョンにAVX命令セットのサポートが追加されました。 この記事では、C / C ++およびアセンブラーでのIntel AVXルーチンの実用的な最適化の問題について説明します。
AVXコマンドセット
すべてのAVXコマンド、および他のいくつかのコマンドは、
Intel AVVサイトにある
マニュアルに記載されてい
ます 。 ある意味では、AVX命令セットは、すべての最新のプロセッサですでにサポートされているSSE命令セットの拡張です。 特に、AVXは元の128ビットSSEレジスタを256ビットに拡張します。 新しい256ビットレジスタは、ymm0-ymm15として指定されています(32ビットプログラムではymm0-ymm7のみが使用可能です)。 128ビットSSEレジスタxmm0-xmm15は、対応するAVXレジスタの下位128ビットを指します。
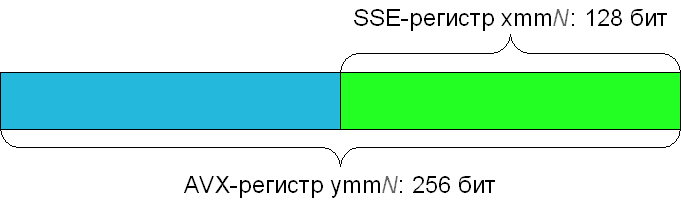
新しい256ビットレジスタを効果的に使用するために、無数の命令がAVXに追加されました。 ただし、それらのほとんどは、すでによく知られているSSE命令のわずかに変更されたバージョンです。
そのため、SSEからの各命令(およびSSE2、SSE3、SSSE3、SSE4.1、SSE4.2、およびAES-NI)には、AVXに接頭辞vを持つ独自のアナログがあります。 このようなAVX命令は、接頭辞に加えて、3つのオペランドを持つことができるという点でSSEの対応する命令と異なります。最初のオペランドは結果を書き込む場所を示し、他の2つはデータを取得する場所を示します。 3オペランド命令は、まず、コード内のレジスタをコピーする不必要な操作をなくし、次に、最適化コンパイラーの記述を単純化するという点で優れています。 SSE2コード
movdqa xmm2, xmm0
punpcklbw xmm0, xmm1
punpckhbw xmm2, xmm1次のようにAVXで書き直すことができます
vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1 vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1この場合、プレフィックスvのコマンドは、書き込み先のAVXレジスタの最上位128ビットを占有します。 たとえば、
vpaddw命令
xmm0、xmm1、xmm2は 、上位128ビットレジスタymm0を無効にします。
さらに、一部のSSE命令はAVXで拡張され、256ビットレジスタで動作します。 そのような指示には、浮動小数点数(単精度と倍精度の両方)を扱うすべてのチームが含まれます。 たとえば、次のAVXコード
vmovapd ymm0, [esi]
vmulpd ymm0, ymm0, [edx]
vmovapd [edi], ymm04倍を一度に処理します。
さらに、AVXにはいくつかの新しい指示が含まれています。
- vbroadcastss / vbroadcastsd / vbroadcastf128-AVXレジスタ全体に同じロード値を設定します
- vmaskmovps / vmaskmovpd-別のAVXレジスタ内の数値の符号に応じて、条件付きでAVXレジスタ内のfloat / double数値をロード/保存します
- vzeroupper-すべてのAVXレジスタの最上位128ビットをリセットします
- vzeroall-すべてのAVXレジスタの完全なゼロ化
- vinsertf128 / vextractf128-256ビットAVXレジスタの128ビット部分の挿入/受信
- vperm2f128-256ビットAVXレジスタの128ビット部分の置換。 順列パラメーターは静的に設定されます。
- vpermilps / vpermilpd-256ビットAVXレジスタの128ビット部分内のfloat / double数の置換。 この場合、置換パラメータは別のAVXレジスタから取得されます。
- vldmxcsr / vstmxcsr-AVX制御パラメーターのロード/保存(それなしの場合)
- xsaveopt-どのAVXレジスタにデータが含まれているかについてのヒントを取得します。 このチームはOS開発者向けに作られており、コンテキストの切り替えを加速するのに役立ちます。
アセンブラコードでのAVXの使用
現在、AVXは、x86用のすべての一般的なアセンブラーでサポートされています。
- GAS(GNU Assembler) -binutilsバージョン2.19.50.0.1以降ですが、以降のAVX仕様をサポートする2.19.51.0.1を使用することをお勧めします
- MASM-バージョン10以降(Visual Studio 2010に含まれる)
- NASM-バージョン2.03以降ですが、最新バージョンを使用することをお勧めします
- YASM-バージョン0.70以降ですが、最新バージョンを使用することをお勧めします
AVXシステムサポートの決定
AVXを使用する前に最初に行うことは、システムがそれをサポートしていることを確認することです。 SSEのさまざまなバージョンとは異なり、AVXを使用するには、プロセッサだけでなく、オペレーティングシステムもサポートする必要があります(結局、コンテキストを切り替えるときに上位128ビットAVXレジスタを保存する必要があります)。 幸いなことに、AVX開発者は、オペレーティングシステムがこの一連の命令をどのようにサポートするかを知る方法を提供してきました。 OSは、特別なXSAVE / XRSTOR命令を使用してAVXコンテキストを保存/復元します。これらのコマンドは、拡張制御レジスタ(拡張制御レジスタ)を使用して構成されます。 現在、このようなレジスタはXCR0のみで、XFEATURE_ENABLED_MASKでもあります。 その値を取得するには、ecxにレジスタ番号を書き込み(XCR0の場合、これはもちろん0です)、
XGETBVコマンドを呼び出します。 64ビットのレジスタ値は、edx:eaxのレジスタのペアに格納されます。 XFEATURE_ENABLED_MASKレジスタのビットをゼロに設定すると、XSAVEコマンドはFPUレジスタの状態を保存します(ただし、このビットは常に設定されます)。最初のビットはSSEレジスタ(AVXレジスタの下位128ビット)を保持し、2番目のビットはAVXの最高128ビットを保持します登録します。 T.O. コンテキストを切り替えるときにシステムがAVXレジスタの状態を保存するようにするには、ビット1と2がXFEATURE_ENABLED_MASKレジスタに設定されていることを確認する必要がありますが、これだけではありません:XGETBVコマンドを呼び出す前に、OSが実際にXSAVE命令を使用していることを確認する/コンテキストを管理するXRSTOR。 これは、パラメーターeax = 1でCPUID命令を呼び出すことによって行われます。OSがXSAVE / XRSTOR命令を使用してコンテキストの保存/復元制御を有効にしている場合、ecxレジスタの27番目のビットでCPUIDを実行すると1になります。 さらに、プロセッサ自体がAVX命令セットをサポートしていることを確認すると便利です。 これは同じ方法で行われます。eax= 1でCPUIDを呼び出し、その後、ecxレジスタの28番目のビットに1つあることを確認します。 上記のすべては、次のコードで表現できます(Intel AVXリファレンスからわずかな修正を加えてコピー)。
; extern "C" int isAvxSupported()
_isAvxSupported:
xor eax, eax
cpuid
cmp eax, 1 ; CPUID eax = 1?
jb not_supported
mov eax, 1
cpuid
and ecx, 018000000h ; , 27 ( XSAVE/XRSTOR)
cmp ecx, 018000000h ; 28 ( AVX )
jne not_supported
xor ecx, ecx ; XFEATURE_ENABLED_MASK/XCR0 0
xgetbv ; XFEATURE_ENABLED_MASK edx:eax
and eax, 110b
cmp eax, 110b ; , AVX
jne not_supported
mov eax, 1
ret
not_supported:
xor eax, eax
ret
AVX命令の使用
AVX命令をいつ使用できるかがわかったので、次はその命令を使用します。 AVXのプログラミングは、他の命令セットのプログラミングとほとんど異なりませんが、次の機能を考慮する必要があります。
- SSE命令とAVX命令(SSE命令のAVXアナログを含む)を混在させることは非常に望ましくありません。 AVX命令の実行からSSE命令に切り替えるために、プロセッサはAVXレジスタの上位128ビットを特別なキャッシュに保存します。これには最大50クロックサイクルかかります。 プロセッサがSSE命令の後に再びAVX命令に戻ると、AVXレジスタの上位128ビットが復元され、さらに50サイクルかかります。 したがって、SSE命令とAVX命令を混在させると、パフォーマンスが著しく低下します。 AVXコードでSSEから何らかのコマンドが必要な場合は、AVXの対応するプレフィックスvを使用します。
- vzeroupperまたはvzeroallコマンドを使用してAVXレジスタの上位128ビットを無効にすると、SSEコードへの移行中にAVXレジスタの上部を保存することを回避できます。 これらのコマンドはすべてのAVXレジスタを占有するという事実にもかかわらず、非常に高速に機能します。 適切なルールは、AVXを使用するルーチンを終了する前に、これらのコマンドのいずれかを使用することです。
- 整列データvmovaps / vmovapd / vmovdqaのload / saveコマンドでは、コマンド自体が32バイトを読み込む場合でも、データを16バイト整列させる必要があります。
- Windows x64では、ルーチンはレジスタxmm6-xmm15を変更しないでください。 したがって、これらのレジスタ(またはそれらに対応するymm6-ymm15レジスタ)を使用する場合、サブルーチンの先頭でスタックに保存し、サブルーチンを終了する前にスタックから復元する必要があります。
- Sandy Bridgeコアは、アクチュエーターが256ビットに拡張されているため、クロックサイクルごとに2つの256ビット浮動小数点AVXコマンドを実行できます(1回の乗算と1回の加算)。 Bulldozerコアには、浮動小数点コマンド用の2つのユニバーサル128ビットアクチュエータがあり、サイクルごとに1つの256ビットAVXコマンドを実行できます(乗算、加算、または複合乗算と加算(融合乗算加算);最後の演算を使用する場合Sandy Bridgeと同じパフォーマンスを期待できます)。
これで、AVXを使用してコードを記述するためのすべてがわかりました。 たとえば、これ:
; extern "C" double _vec4_dot_avx( double a[4], double b[4] )
_vec4_dot_avx:
%ifdef X86
mov eax, [esp + 8 + 0] ; eax = a
mov edx, [esp + 8 + 8] ; edx = b
vmovupd ymm0, [eax] ; ymm0 = *a
vmovupd ymm1, [edx] ; ymm1 = *b
%else
vmovupd ymm0, [rcx] ; ymm0 = *a
vmovupd ymm1, [rdx] ; ymm1 = *b
%endif
vmulpd ymm0, ymm0, ymm1 ; ymm0 = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
vperm2f128 ymm1, ymm0, ymm0, 010000001b ; ymm1 = ( +0.0, +0.0, a3 * b3, a2 * b2 )
vaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
vxorpd xmm1, xmm1, xmm1 ; ymm1 = ( +0.0, +0.0, +0.0, +0.0 )
vhaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
%ifdef X86 ; 32- st(0)
sub esp, 8
vmovsd [esp], xmm0
vzeroall ; SSE- :
fld qword [esp]
add esp, 8
%else
vzeroupper ; xmm0 , 128
%endif
ret
AVXコードのテスト
AVXコードが機能していることを確認するには、ユニットテストを記述することをお勧めします。 ただし、現在販売されているプロセッサのいずれもAVXをサポートしていない場合、これらのユニットテストを実行する方法は疑問です。 Intelの特別なユーティリティである
Software Development Emulator(SDE)がこれを支援します。 SDEでできることは、プログラムを実行し、その場で新しい命令セットをエミュレートすることです。 もちろん、パフォーマンスは実際のハードウェアのパフォーマンスとはかけ離れていますが、この方法でプログラムの正確性を確認できます。 SDEの使用は単純ではありません。avx-unit-test.exeファイルにAVXコードの単体テストがあり、「Hello、AVX!」パラメーターで実行する必要がある場合は、パラメーターでSDEを実行するだけです。
sde -- avx-unit-test.exe "Hello, AVX!"プログラムを開始すると、SDEはAVX命令だけでなく、XGETBVおよびCPUID命令もエミュレートするため、AVXサポートを検出するために以前に提案された方法を使用すると、SDEで実行されているプログラムはAVXが実際にサポートされていると判断します。 AVXに加えて、SDE(または、SDEが構築されているJITピンコンパイラ)は、SSE3、SSSE3、SSE4.1、SSE4.2、SSE4a、AES-NI、XSAVE、POPCNT、およびPCLMULQDQ命令をエミュレートできます。新しい命令セット用のソフトウェアの開発を妨げません。
AVXコードのパフォーマンス評価
AVXコードのパフォーマンスに関するいくつかのアイデアは、Intel-
Intel Architecture Code Analyzer(IACA)の別のユーティリティを使用して取得できます。 IACAを使用すると、コードの線形セクションのランタイムを評価できます(条件分岐命令が検出された場合、IACAは分岐が発生しないと見なします)。 IACAを使用するには、まず分析するコードのセクションに特別なマーカーを付ける必要があります。 マーカーは次のようになります。
; ,
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
; ,
%macro IACA_END 0
mov ebx, 222
db 0x64, 0x67, 0x90
%endmacroここで、分析するコードの一部でこれらのマクロを囲む必要があります
IACA_START
vmovups ymm0, [ecx]
vbroadcastss ymm1, [edx]
vmulps ymm0, ymm0, ymm1
vmovups [ecx], ymm0
vzeroupper
IACA_ENDこれらのマクロでコンパイルされたオブジェクトファイルは、IACAから提供される必要があります。
iaca -32 -arch AVX -cp DATA_DEPENDENCY -mark 0 -o avx-sample.txt avx-sample.objIACAのパラメーターは次のように理解する必要があります
- -32-入力オブジェクトファイル(MS COFF)に32ビットコードが含まれることを意味します。 64ビットコードの場合、 -64を指定します。 オブジェクトファイル(.obj)ではなく、実行可能モジュール(.exeまたは.dll)がIACA入力に供給される場合、この引数は省略できます。
- -arch AVX -IACAは、AVXをサポートする将来のIntelプロセッサー(つまりSandy Bridge)でこのコードのパフォーマンスを分析する必要があることを示します。 他の可能な値は-arch nehalemと-arch westmereです。
- -cp DATA_DEPENDENCYは、どの命令がデータのクリティカルパスにあるか(つまり、このコードの結果をより速く計算できるように最適化する必要がある命令)を表示するようIACAに要求します。 別の可能な値: -cp PERFORMANCEは、プロセッサパイプラインを「プラグイン」する命令を表示するようIACAに要求します。
- -mark 0は、マーカーのすべてのコードマークセクションを分析するようIACAに指示します。 -mark nを指定すると、IACAはマークされたn番目のコードのみを分析します。
- -o avx-sampleは、分析結果が書き込まれるファイルの名前を設定します。 このパラメーターを省略すると、分析結果がコンソールに表示されます。
IACAを実行した結果を以下に示します。
Intel(R) Architecture Code Analyzer Version - 1.1.3
Analyzed File - avx-sample.obj
Binary Format - 32Bit
Architecture - Intel(R) AVX
*******************************************************************
Intel(R) Architecture Code Analyzer Mark Number 1
*******************************************************************
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
Port Binding in cycles:
-------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------
| Cycles | 1 | 0 | 0 | 2 | 2 | 1 | 1 | 2 | 1 |
-------------------------------------------------------
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
ここで最も重要なメトリックは、合計スループットとデータ依存性レイテンシです。 最適化するコードが小さなサブルーチンであり、プログラムがその結果のデータに依存している場合、データの依存性のレイテンシを可能な限り小さくする必要があります。 例は、上記のvec4_dot_avxルーチンのリストです。 最適化されたコードが要素の大きな配列を処理するサイクルの一部である場合、タスクは合計スループットを減らすことです(実際、このメトリックは相互スループットと呼ばれるべきですが、まあまあです)。
C / C ++コードでAVXを使用する
AVXサポートは、次の一般的なコンパイラに実装されています。
- バージョン16以降のMicrosoft C / C ++コンパイラ(Visual Studio 2010に含まれる)
- バージョン11.1以降のインテルC ++コンパイラー
- バージョン4.4以降のGCC
256ビットAVX命令を使用するために、新しいヘッダーファイル
immintrin.hがこれらのコンパイラの配布に含まれ、対応する組み込み関数の説明
が含まれています。 このヘッダーファイルを含めると、すべてのSSE-intrinsic'ovのヘッダーファイルが自動的に含まれます。 128ビットAVX命令については、それらには別個のリーダーだけでなく、別個の組み込み関数もあります。 代わりに、SSEx命令に組み込み関数を使用し、これらの組み込み関数への呼び出しがコンパイルされる命令のタイプ(SSEまたはAVX)は、コンパイラオプションで指定されます。 つまり、SSEとAVX形式の128ビット命令を1つのコンパイル済みファイルに混在させることは機能せず、SSEバージョンとAVXバージョンの両方の関数を使用する場合は、それらを異なるコンパイル済みファイルに記述し、これらのファイルを異なるパラメーターでコンパイルする必要があります) SSEx組み込み関数のAVX命令へのコンパイルを含むコンパイルオプションは次のとおりです。
- / arch:AVX-Microsoft C / C ++ CompilerおよびIntel C ++ Compiler for Windows
- -mavx-Linux用GCCおよびIntel C ++コンパイラー用
- / QxAVX-Intel C ++コンパイラー用
- / QaxAVX-Intel C ++コンパイラー用
これらのコマンドは、SSEx組み込み関数の動作を変更するだけでなく、通常のC / C ++コードをコンパイルするときにコンパイラーがAVX命令を生成できるようにすることに留意してください(/ )
これらすべての組み込み関数の処理を容易にするために、Intelはオンラインリファレンス-Intel Intrinsic Guideを作成しました。これには、Intelプロセッサでサポートされるすべての組み込み関数の説明が含まれています。 ハードウェアにすでに実装されている命令については、レイテンシとスループットも示されます。 このガイドは、
Intel AVX Webサイトからダウンロードできます(Windows、Linux、およびMac OS Xのバージョンがあります)。
AVXシステムサポートの決定
原則として、AVXシステムのサポートを認識するために、インラインアセンブラーでコードを書き換えるか、アセンブラーによってアセンブルされたオブジェクトファイルを単にリンクすることにより、前述のアセンブラーコードを使用できます。 ただし、インラインアセンブラを使用できない場合(たとえば、コーディングガイドラインのため、またはWindows x64用のMicrosoft C / C ++コンパイラの場合のようにコンパイラがサポートしていないため)、あなたは深いたわごとにいます。 問題は、xgetbvステートメントの組み込み関数が存在しないことです! したがって、タスクは2つの部分に分かれています。プロセッサがAVXをサポートしていることを確認し(クロスプラットフォームで実行可能)、OSがAVXをサポートしていることを確認します(ここでは、各OSに独自のコードを記述する必要があります)。
組み込み関数void
__cpuid (int cpuInfo [4]、int infoType)がある同じCPUID命令を使用して、プロセッサがAVXをサポートしていることを確認できます。 infoTypeパラメーターは、CPUIDを呼び出す前にeaxレジスタの値を設定します。関数の実行後のcpuInfoには、eax、ebx、ecx、edxのレジスタが(この順序で)含まれます。 T.O. 次のコードを取得します。
int isAvxSupportedByCpu() {
int cpuInfo[4];
__cpuid( cpuInfo, 0 );
if( cpuInfo[0] != 0 ) {
__cpuid( cpuInfo, 1 );
return cpuInfo[3] & 0x10000000; // , 28- ecx
} else {
return 0; //
}
}OSからのサポートはより複雑です。 AVXは現在、次のOSでサポートされています。
- Windows 7
- Windows Server 2008 R2
- Linuxカーネル2.6.30以降
Windowsは、kernel32.dllのGetEnabledExtendedFeatures関数の形式で、新しい命令セットのOSサポートについて学習する機能を追加しました。 残念ながら、この機能は
文書化されています。 しかし、それに関するいくつかの情報はまだ取得できます。 この関数は、プラットフォームSDKのWinBase.hファイルに記述されています。
WINBASEAPI
DWORD64
WINAPI
GetEnabledExtendedFeatures(
__in DWORD64 FeatureMask
);FeatureMaskパラメーターの値は、WinNT.hヘッダーにあります。
//
// Known extended CPU state feature IDs
//
#define XSTATE_LEGACY_FLOATING_POINT 0
#define XSTATE_LEGACY_SSE 1
#define XSTATE_GSSE 2
#define XSTATE_MASK_LEGACY_FLOATING_POINT (1i64 << (XSTATE_LEGACY_FLOATING_POINT))
#define XSTATE_MASK_LEGACY_SSE (1i64 << (XSTATE_LEGACY_SSE))
#define XSTATE_MASK_LEGACY (XSTATE_MASK_LEGACY_FLOATING_POINT | XSTATE_MASK_LEGACY_SSE)
#define XSTATE_MASK_GSSE (1i64 << (XSTATE_GSSE))
#define MAXIMUM_XSTATE_FEATURES 64XSTATE_MASK_ *マスクがXFEATURE_ENABLED_MASKレジスタの同じビットに対応していることは簡単にわかります。
これに加えて、Windows DDKには、Wintl.hのGetEnabledExtendedFeaturesおよびXSTATE_MASK_ *に似た2滴の水など、
RtlGetEnabledExtendedFeatures関数と
XSTATE_MASK_XXX定数の説明があります。 T.O. WindowsからAVXサポートを確認するには、次のコードを使用できます。
int isAvxSupportedByWindows() {
const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
}プログラムがWindows 7とWindows 2008 R2だけでなく動作する必要がある場合は、GetEnabledExtendedFeatures関数をkernel32.dllから動的にロードする必要があります。 Windowsの他のバージョンにはこの機能はありません。
Linuxでは、私が知る限り、OSからのAVXサポートについて知るための個別の機能はありません。 ただし、2.6.30カーネルにAVXサポートが追加されているという事実を活用できます。 その後、カーネルのバージョンがこの値以上であることを確認するためだけに残ります。
uname関数を使用してカーネルバージョンを確認できます。
AVX命令の使用
組み込み関数を使用してMMXまたはSSEを使用したことがある場合、組み込み関数を使用してAVXコードを記述することは難しくありません。 さらに注意が必要なのは、サブプログラムの最後で_mm256_zeroupper()関数を呼び出すことだけです(ご想像のとおり、この組み込み関数はvzeroupper命令を生成します)。 たとえば、上記のアセンブラサブルーチンvec4_dot_avxは、次のように組み込みで書き換えることができます。
double vec4_dot_avx( double a[4], double b[4] ) {
// mmA = a
const __m256d mmA = _mm256_loadu_pd( a );
// mmB = b
const __m256d mmB = _mm256_loadu_pd( b );
// mmAB = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
const __m256d mmAB = _mm256_mul_pd( mmA, mmB );
// mmABHigh = ( +0.0, +0.0, a3 * b3, a2 * b2 )
const __m256d mmABHigh = _mm256_permute2f128_pd( mmAB, mmAB, 0x81 );
// mmSubSum = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
const __m128d mmSubSum = _mm_add_pd(
_mm256_castpd256_pd128( mmAB ),
_mm256_castpd256_pd128( mmABHigh )
);
// mmSum = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
const __m128d mmSum = _mm_hadd_pd( mmSubSum, _mm_setzero_pd() );
const double result = _mm_cvtsd_f64( mmSum );
_mm256_zeroupper();
return result;
}AVXコードのテスト
組み込み関数を介してAVX命令セットを使用する場合、このコードをSDEエミュレーターで実行する以外に、もう1つの可能性があります-組み込み関数SSE1-SSE4.2を介して256ビットAVX組み込み関数をエミュレートする
特別なヘッダーファイルを使用し
ます 。 この場合、NehalemおよびWestmereプロセッサで実行できる実行可能ファイルを取得します。これはもちろん、エミュレータよりも高速です。 ただし、このメソッドは、コンパイラーによってAVXコードによって生成されたエラーを検出するためにうまく機能しないことに注意してください(そして、そうかもしれません)。
AVXコードのパフォーマンス評価
IACAを使用して、組み込み関数からC / C ++コンパイラーによって作成されたAVXコードのパフォーマンスを分析することは、アセンブラーコードの分析とほとんど変わりません。 iacaMarks.hヘッダーファイルは、IACAディストリビューションにあり、IACA_STARTおよびIACA_ENDマーカーマクロについて説明しています。 分析されたコードセクションをマークする必要があります。 サブルーチンのコードでは、IACA_ENDマーカーはreturnステートメントの前にある必要があります。そうでない場合、コンパイラーはマーカーコードをスローして「最適化」します。 IACA_START / IACA_ENDマクロは、Windows x64用のMicrosoft C / C ++コンパイラでサポートされていないインラインアセンブラを使用するため、特別なマクロオプションを使用する必要がある場合は、IACA_VC64_STARTおよびIACA_VC64_ENDを使用します。
おわりに
この記事では、AVX命令セットを使用してプログラムを開発する方法を示しました。 この知識が、コンピューターの機能を100%使用するプログラムでユーザーを喜ばせるのに役立つことを願っています!
運動
vec4_dot_avxサブルーチンのコードは、パフォーマンスの点で最適ではありません。 より最適に書き換えてみてください。
あなたのデータ依存性のレイテンシは何でしたか?